 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Parameter Isolation Better for Prompt-Based Continual Learning?
Jan 28, 2026Prompt-based continual learning methods effectively mitigate catastrophic forgetting. However, most existing methods assign a fixed set of prompts to each task, completely isolating knowledge across tasks and resulting in suboptimal parameter utilization. To address this, we consider the practical needs of continual learning and propose a prompt-sharing framework. This framework constructs a global prompt pool and introduces a task-aware gated routing mechanism that sparsely activates a subset of prompts to achieve dynamic decoupling and collaborative optimization of task-specific feature representations. Furthermore, we introduce a history-aware modulator that leverages cumulative prompt activation statistics to protect frequently used prompts from excessive updates, thereby mitigating inefficient parameter usage and knowledge forgetting. Extensive analysis and empirical results demonstrate that our approach consistently outperforms existing static allocation strategies in effectiveness and efficiency.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
Toward Efficient Testing of Graph Neural Networks via Test Input Prioritization
Dec 20, 2025Graph Neural Networks (GNNs) have demonstrated remarkable efficacy in handling graph-structured data; however, they exhibit failures after deployment, which can cause severe consequences. Hence, conducting thorough testing before deployment becomes imperative to ensure the reliability of GNNs. However, thorough testing requires numerous manually annotated test data. To mitigate the annotation cost, strategically prioritizing and labeling high-quality unlabeled inputs for testing becomes crucial, which facilitates uncovering more model failures with a limited labeling budget. Unfortunately, existing test input prioritization techniques either overlook the valuable information contained in graph structures or are overly reliant on attributes extracted from the target model, i.e., model-aware attributes, whose quality can vary significantly. To address these issues, we propose a novel test input prioritization framework, named GraphRank, for GNNs. GraphRank introduces model-agnostic attributes to compensate for the limitations of the model-aware ones. It also leverages the graph structure information to aggregate attributes from neighboring nodes, thereby enhancing the model-aware and model-agnostic attributes. Furthermore, GraphRank combines the above attributes with a binary classifier, using it as a ranking model to prioritize inputs. This classifier undergoes iterative training, which enables it to learn from each round's feedback and improve its performance accordingly. Extensive experiments demonstrate GraphRank's superiority over existing techniques.
* This is the author-accepted manuscript of a paper published in Automated Software Engineering Journal
MultiEgo: A Multi-View Egocentric Video Dataset for 4D Scene Reconstruction
Dec 12, 2025Multi-view egocentric dynamic scene reconstruction holds significant research value for applications in holographic documentation of social interactions. However, existing reconstruction datasets focus on static multi-view or single-egocentric view setups, lacking multi-view egocentric datasets for dynamic scene reconstruction. Therefore, we present MultiEgo, the first multi-view egocentric dataset for 4D dynamic scene reconstruction. The dataset comprises five canonical social interaction scenes: meetings, performances, and a presentation. Each scene provides five authentic egocentric videos captured by participants wearing AR glasses. We design a hardware-based data acquisition system and processing pipeline, achieving sub-millisecond temporal synchronization across views, coupled with accurate pose annotations. Experiment validation demonstrates the practical utility and effectiveness of our dataset for free-viewpoint video (FVV) applications, establishing MultiEgo as a foundational resource for advancing multi-view egocentric dynamic scene reconstruction research.
Cross-modal Retrieval Models for Stripped Binary Analysis
Dec 11, 2025
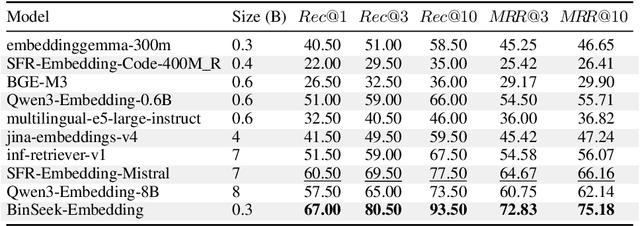
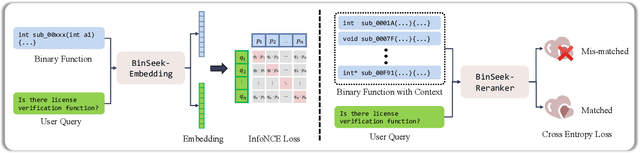
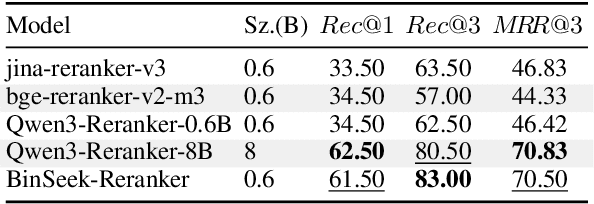
LLM-agent based binary code analysis has demonstrated significant potential across a wide range of software security scenarios, including vulnerability detection, malware analysis, etc. In agent workflow, however, retrieving the positive from thousands of stripped binary functions based on user query remains under-studied and challenging, as the absence of symbolic information distinguishes it from source code retrieval. In this paper, we introduce, BinSeek, the first two-stage cross-modal retrieval framework for stripped binary code analysis. It consists of two models: BinSeekEmbedding is trained on large-scale dataset to learn the semantic relevance of the binary code and the natural language description, furthermore, BinSeek-Reranker learns to carefully judge the relevance of the candidate code to the description with context augmentation. To this end, we built an LLM-based data synthesis pipeline to automate training construction, also deriving a domain benchmark for future research. Our evaluation results show that BinSeek achieved the state-of-the-art performance, surpassing the the same scale models by 31.42% in Rec@3 and 27.17% in MRR@3, as well as leading the advanced general-purpose models that have 16 times larger parameters.
PipeDiT: Accelerating Diffusion Transformers in Video Generation with Task Pipelining and Model Decoupling
Nov 15, 2025Video generation has been advancing rapidly, and diffusion transformer (DiT) based models have demonstrated remark- able capabilities. However, their practical deployment is of- ten hindered by slow inference speeds and high memory con- sumption. In this paper, we propose a novel pipelining frame- work named PipeDiT to accelerate video generation, which is equipped with three main innovations. First, we design a pipelining algorithm (PipeSP) for sequence parallelism (SP) to enable the computation of latent generation and commu- nication among multiple GPUs to be pipelined, thus reduc- ing inference latency. Second, we propose DeDiVAE to de- couple the diffusion module and the variational autoencoder (VAE) module into two GPU groups, whose executions can also be pipelined to reduce memory consumption and infer- ence latency. Third, to better utilize the GPU resources in the VAE group, we propose an attention co-processing (Aco) method to further reduce the overall video generation latency. We integrate our PipeDiT into both OpenSoraPlan and Hun- yuanVideo, two state-of-the-art open-source video generation frameworks, and conduct extensive experiments on two 8- GPU systems. Experimental results show that, under many common resolution and timestep configurations, our PipeDiT achieves 1.06x to 4.02x speedups over OpenSoraPlan and HunyuanVideo.
Class Incremental Medical Image Segmentation via Prototype-Guided Calibration and Dual-Aligned Distillation
Nov 11, 2025



Class incremental medical image segmentation (CIMIS) aims to preserve knowledge of previously learned classes while learning new ones without relying on old-class labels. However, existing methods 1) either adopt one-size-fits-all strategies that treat all spatial regions and feature channels equally, which may hinder the preservation of accurate old knowledge, 2) or focus solely on aligning local prototypes with global ones for old classes while overlooking their local representations in new data, leading to knowledge degradation. To mitigate the above issues, we propose Prototype-Guided Calibration Distillation (PGCD) and Dual-Aligned Prototype Distillation (DAPD) for CIMIS in this paper. Specifically, PGCD exploits prototype-to-feature similarity to calibrate class-specific distillation intensity in different spatial regions, effectively reinforcing reliable old knowledge and suppressing misleading information from old classes. Complementarily, DAPD aligns the local prototypes of old classes extracted from the current model with both global prototypes and local prototypes, further enhancing segmentation performance on old categories. Comprehensive evaluations on two widely used multi-organ segmentation benchmarks demonstrate that our method outperforms state-of-the-art methods, highlighting its robustness and generalization capabilities.
HEDN: A Hard-Easy Dual Network with Task Difficulty Assessment for EEG Emotion Recognition
Nov 10, 2025Multi-source domain adaptation represents an effective approach to addressing individual differences in cross-subject EEG emotion recognition. However, existing methods treat all source domains equally, neglecting the varying transfer difficulties between different source domains and the target domain. This oversight can lead to suboptimal adaptation. To address this challenge, we propose a novel Hard-Easy Dual Network (HEDN), which dynamically identifies "Hard Source" and "Easy Source" through a Task Difficulty Assessment (TDA) mechanism and establishes two specialized knowledge adaptation branches. Specifically, the Hard Network is dedicated to handling "Hard Source" with higher transfer difficulty by aligning marginal distribution differences between source and target domains. Conversely, the Easy Network focuses on "Easy Source" with low transfer difficulty, utilizing a prototype classifier to model intra-class clustering structures while generating reliable pseudo-labels for the target domain through a prototype-guided label propagation algorithm. Extensive experiments on two benchmark datasets, SEED and SEED-IV, demonstrate that HEDN achieves state-of-the-art performance in cross-subject EEG emotion recognition, with average accuracies of 93.58\% on SEED and 79.82\% on SEED-IV, respectively. These results confirm the effectiveness and generalizability of HEDN in cross-subject EEG emotion recognition.
SIM-Assisted End-to-End Co-Frequency Co-Time Full-Duplex System
Oct 31, 2025



To further suppress the inherent self-interference (SI) in co-frequency and co-time full-duplex (CCFD) systems, we propose integrating a stacked intelligent metasurface (SIM) into the RF front-end to enhance signal processing in the wave domain. Furthermore, an end-to-end (E2E) learning-based signal processing method is adopted to control the metasurface. Specifically, the real metasurface is abstracted as hidden layers of a network, thereby constructing an electromagnetic neural network (EMNN) to enable driving control of the real communication system. Traditional communication tasks, such as channel coding, modulation, precoding, combining, demodulation, and channel decoding, are synchronously carried out during the electromagnetic (EM) forward propagation through the metasurface. Simulation results show that, benefiting from the additional wave-domain processing capability of the SIM, the SIM-assisted CCFD system achieves significantly reduced bit error rate (BER) compared with conventional CCFD systems. Our study fully demonstrates the potential applications of EMNN and SIM-assisted E2E CCFD systems in next-generation transceiver design.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.