 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing in 3D: Free-Viewpoint Fusion Rendering with a 3D Infrared-Visible Scene Representation
Jan 19, 2026Infrared-visible image fusion aims to integrate infrared and visible information into a single fused image. Existing 2D fusion methods focus on fusing images from fixed camera viewpoints, neglecting a comprehensive understanding of complex scenarios, which results in the loss of critical information about the scene. To address this limitation, we propose a novel Infrared-Visible Gaussian Fusion (IVGF) framework, which reconstructs scene geometry from multimodal 2D inputs and enables direct rendering of fused images. Specifically, we propose a cross-modal adjustment (CMA) module that modulates the opacity of Gaussians to solve the problem of cross-modal conflicts. Moreover, to preserve the distinctive features from both modalities, we introduce a fusion loss that guides the optimization of CMA, thus ensuring that the fused image retains the critical characteristics of each modality. Comprehensive qualitative and quantitative experiments demonstrate the effectiveness of the proposed method.
Modality-Decoupled RGB-Thermal Object Detector via Query Fusion
Jan 13, 2026The advantage of RGB-Thermal (RGB-T) detection lies in its ability to perform modality fusion and integrate cross-modality complementary information, enabling robust detection under diverse illumination and weather conditions. However, under extreme conditions where one modality exhibits poor quality and disturbs detection, modality separation is necessary to mitigate the impact of noise. To address this problem, we propose a Modality-Decoupled RGB-T detection framework with Query Fusion (MDQF) to balance modality complementation and separation. In this framework, DETR-like detectors are employed as separate branches for the RGB and TIR images, with query fusion interspersed between the two branches in each refinement stage. Herein, query fusion is performed by feeding the high-quality queries from one branch to the other one after query selection and adaptation. This design effectively excludes the degraded modality and corrects the predictions using high-quality queries. Moreover, the decoupled framework allows us to optimize each individual branch with unpaired RGB or TIR images, eliminating the need for paired RGB-T data. Extensive experiments demonstrate that our approach delivers superior performance to existing RGB-T detectors and achieves better modality independence.
Learning A Robust RGB-Thermal Detector for Extreme Modality Imbalance
May 28, 2025RGB-Thermal (RGB-T) object detection utilizes thermal infrared (TIR) images to complement RGB data, improving robustness in challenging conditions. Traditional RGB-T detectors assume balanced training data, where both modalities contribute equally. However, in real-world scenarios, modality degradation-due to environmental factors or technical issues-can lead to extreme modality imbalance, causing out-of-distribution (OOD) issues during testing and disrupting model convergence during training. This paper addresses these challenges by proposing a novel base-and-auxiliary detector architecture. We introduce a modality interaction module to adaptively weigh modalities based on their quality and handle imbalanced samples effectively. Additionally, we leverage modality pseudo-degradation to simulate real-world imbalances in training data. The base detector, trained on high-quality pairs, provides a consistency constraint for the auxiliary detector, which receives degraded samples. This framework enhances model robustness, ensuring reliable performance even under severe modality degradation. Experimental results demonstrate the effectiveness of our method in handling extreme modality imbalances~(decreasing the Missing Rate by 55%) and improving performance across various baseline detectors.
Data Generation Scheme for Thermal Modality with Edge-Guided Adversarial Conditional Diffusion Model
Aug 07, 2024In challenging low light and adverse weather conditions,thermal vision algorithms,especially object detection,have exhibited remarkable potential,contrasting with the frequent struggles encountered by visible vision algorithms. Nevertheless,the efficacy of thermal vision algorithms driven by deep learning models remains constrained by the paucity of available training data samples. To this end,this paper introduces a novel approach termed the edge guided conditional diffusion model. This framework aims to produce meticulously aligned pseudo thermal images at the pixel level,leveraging edge information extracted from visible images. By utilizing edges as contextual cues from the visible domain,the diffusion model achieves meticulous control over the delineation of objects within the generated images. To alleviate the impacts of those visible-specific edge information that should not appear in the thermal domain,a two-stage modality adversarial training strategy is proposed to filter them out from the generated images by differentiating the visible and thermal modality. Extensive experiments on LLVIP demonstrate ECDM s superiority over existing state-of-the-art approaches in terms of image generation quality.
Channel and Spatial Relation-Propagation Network for RGB-Thermal Semantic Segmentation
Aug 24, 2023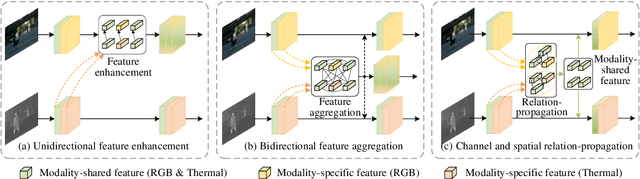
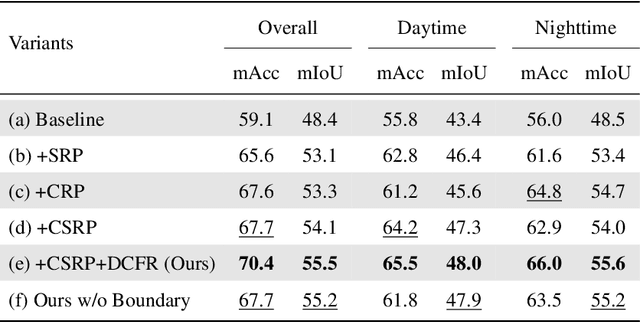
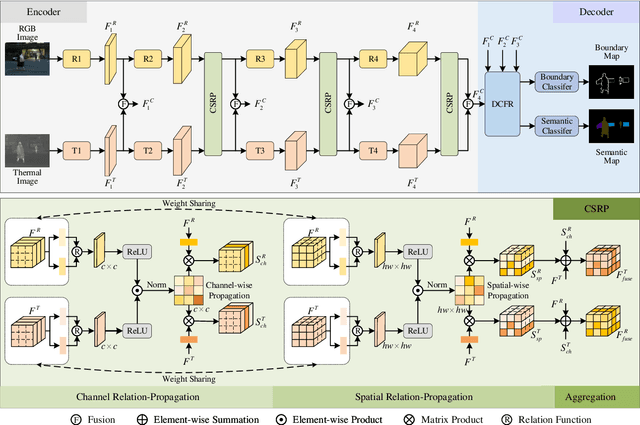

RGB-Thermal (RGB-T) semantic segmentation has shown great potential in handling low-light conditions where RGB-based segmentation is hindered by poor RGB imaging quality. The key to RGB-T semantic segmentation is to effectively leverage the complementarity nature of RGB and thermal images. Most existing algorithms fuse RGB and thermal information in feature space via concatenation, element-wise summation, or attention operations in either unidirectional enhancement or bidirectional aggregation manners. However, they usually overlook the modality gap between RGB and thermal images during feature fusion, resulting in modality-specific information from one modality contaminating the other. In this paper, we propose a Channel and Spatial Relation-Propagation Network (CSRPNet) for RGB-T semantic segmentation, which propagates only modality-shared information across different modalities and alleviates the modality-specific information contamination issue. Our CSRPNet first performs relation-propagation in channel and spatial dimensions to capture the modality-shared features from the RGB and thermal features. CSRPNet then aggregates the modality-shared features captured from one modality with the input feature from the other modality to enhance the input feature without the contamination issue. While being fused together, the enhanced RGB and thermal features will be also fed into the subsequent RGB or thermal feature extraction layers for interactive feature fusion, respectively. We also introduce a dual-path cascaded feature refinement module that aggregates multi-layer features to produce two refined features for semantic and boundary prediction. Extensive experimental results demonstrate that CSRPNet performs favorably against state-of-the-art algorithms.