 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-Based Emergency Braking Intensity Prediction Using Blind Source Separation
Apr 20, 2026Electroencephalography (EEG) signals have been promising for long-term braking intensity prediction but are prone to various artifacts that limit their reliability. Here, we propose a novel framework that models EEG signals as mixtures of independent blind sources and identifies those strongly correlated with braking action. Our method employs independent component analysis to decompose EEG into different components and combines time-frequency analysis with Pearson correlations to select braking-related components. Furthermore, we utilize hierarchical clustering to group braking-related components into two clusters, each characterized by a distinct spatial pattern. Additionally, these components exhibit trial-invariant temporal patterns and demonstrate stable and common neural signatures of the emergency braking process. Using power features from these components and historical braking data, we predict braking intensity at a 200 ms horizon. Evaluations on the open source dataset (O.D.) and human-in-the-loop simulation (H.S.) show that our method outperforms state-of-the-art approaches, achieving RMSE reductions of 8.0% (O.D.) and 23.8% (H.S.).
Modality-Decoupled RGB-Thermal Object Detector via Query Fusion
Jan 13, 2026The advantage of RGB-Thermal (RGB-T) detection lies in its ability to perform modality fusion and integrate cross-modality complementary information, enabling robust detection under diverse illumination and weather conditions. However, under extreme conditions where one modality exhibits poor quality and disturbs detection, modality separation is necessary to mitigate the impact of noise. To address this problem, we propose a Modality-Decoupled RGB-T detection framework with Query Fusion (MDQF) to balance modality complementation and separation. In this framework, DETR-like detectors are employed as separate branches for the RGB and TIR images, with query fusion interspersed between the two branches in each refinement stage. Herein, query fusion is performed by feeding the high-quality queries from one branch to the other one after query selection and adaptation. This design effectively excludes the degraded modality and corrects the predictions using high-quality queries. Moreover, the decoupled framework allows us to optimize each individual branch with unpaired RGB or TIR images, eliminating the need for paired RGB-T data. Extensive experiments demonstrate that our approach delivers superior performance to existing RGB-T detectors and achieves better modality independence.
RadioDUN: A Physics-Inspired Deep Unfolding Network for Radio Map Estimation
Jun 10, 2025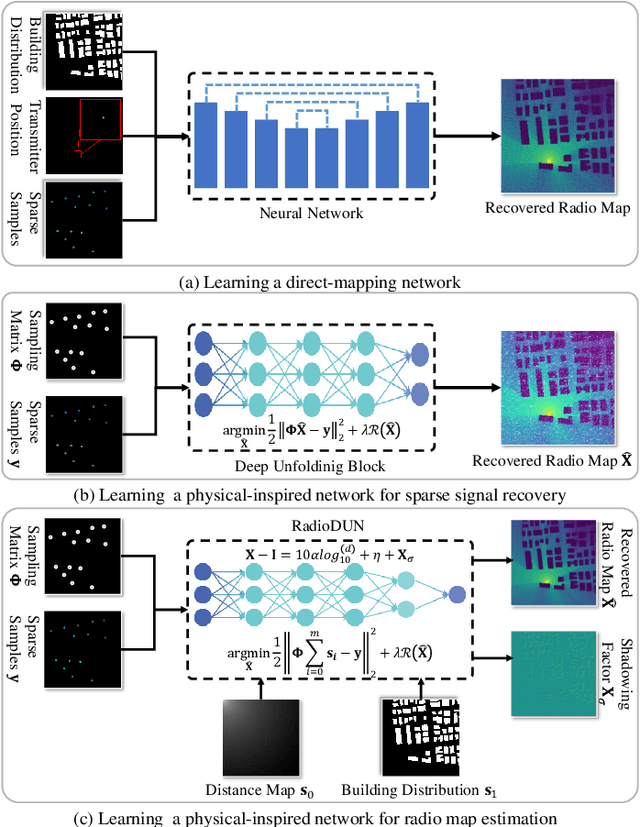

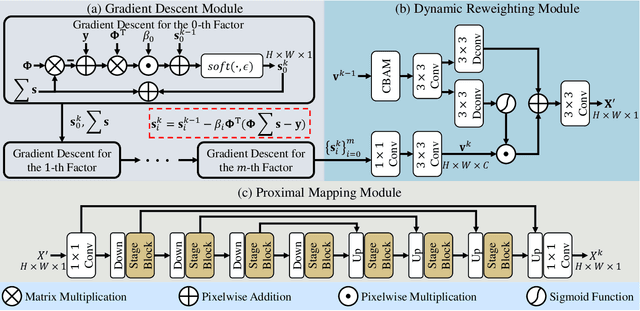
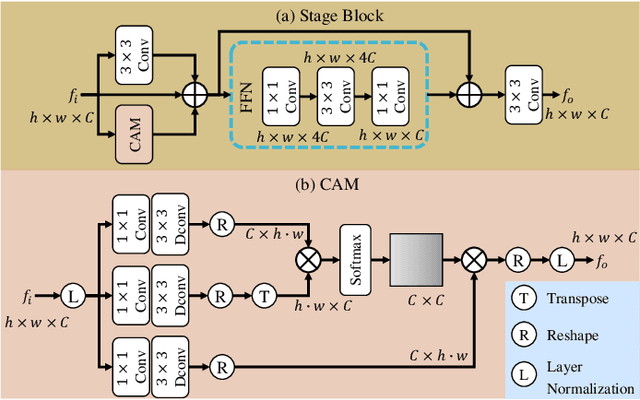
The radio map represents the spatial distribution of spectrum resources within a region, supporting efficient resource allocation and interference mitigation. However, it is difficult to construct a dense radio map as a limited number of samples can be measured in practical scenarios. While existing works have used deep learning to estimate dense radio maps from sparse samples, they are hard to integrate with the physical characteristics of the radio map. To address this challenge, we cast radio map estimation as the sparse signal recovery problem. A physical propagation model is further incorporated to decompose the problem into multiple factor optimization sub-problems, thereby reducing recovery complexity. Inspired by the existing compressive sensing methods, we propose the Radio Deep Unfolding Network (RadioDUN) to unfold the optimization process, achieving adaptive parameter adjusting and prior fitting in a learnable manner. To account for the radio propagation characteristics, we develop a dynamic reweighting module (DRM) to adaptively model the importance of each factor for the radio map. Inspired by the shadowing factor in the physical propagation model, we integrate obstacle-related factors to express the obstacle-induced signal stochastic decay. The shadowing loss is further designed to constrain the factor prediction and act as a supplementary supervised objective, which enhances the performance of RadioDUN. Extensive experiments have been conducted to demonstrate that the proposed method outperforms the state-of-the-art methods. Our code will be made publicly available upon publication.
High Quality Underwater Image Compression with Adaptive Correction and Codebook-based Augmentation
May 15, 2025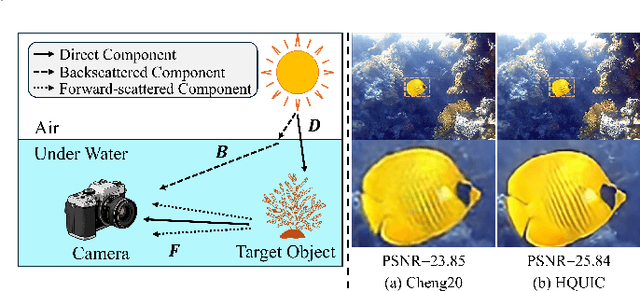
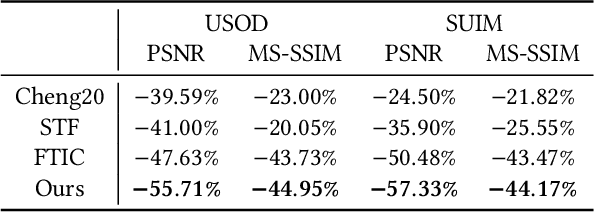
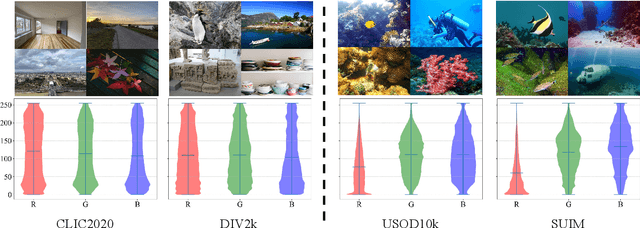
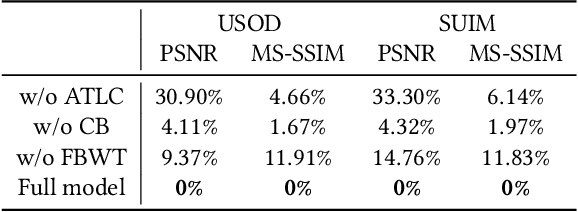
With the increasing exploration and exploitation of the underwater world, underwater images have become a critical medium for human interaction with marine environments, driving extensive research into their efficient transmission and storage. However, contemporary underwater image compression algorithms fail to fully leverage the unique characteristics distinguishing underwater scenes from terrestrial images, resulting in suboptimal performance. To address this limitation, we introduce HQUIC, designed to exploit underwater-image-specific features for enhanced compression efficiency. HQUIC employs an ALTC module to adaptively predict the attenuation coefficients and global light information of the images, which effectively mitigates the issues caused by the differences in lighting and tone existing in underwater images. Subsequently, HQUIC employs a codebook as an auxiliary branch to extract the common objects within underwater images and enhances the performance of the main branch. Furthermore, HQUIC dynamically weights multi-scale frequency components, prioritizing information critical for distortion quality while discarding redundant details. Extensive evaluations on diverse underwater datasets demonstrate that HQUIC outperforms state-of-the-art compression methods.
Towards Facial Image Compression with Consistency Preserving Diffusion Prior
May 09, 2025With the widespread application of facial image data across various domains, the efficient storage and transmission of facial images has garnered significant attention. However, the existing learned face image compression methods often produce unsatisfactory reconstructed image quality at low bit rates. Simply adapting diffusion-based compression methods to facial compression tasks results in reconstructed images that perform poorly in downstream applications due to insufficient preservation of high-frequency information. To further explore the diffusion prior in facial image compression, we propose Facial Image Compression with a Stable Diffusion Prior (FaSDiff), a method that preserves consistency through frequency enhancement. FaSDiff employs a high-frequency-sensitive compressor in an end-to-end framework to capture fine image details and produce robust visual prompts. Additionally, we introduce a hybrid low-frequency enhancement module that disentangles low-frequency facial semantics and stably modulates the diffusion prior alongside visual prompts. The proposed modules allow FaSDiff to leverage diffusion priors for superior human visual perception while minimizing performance loss in machine vision due to semantic inconsistency. Extensive experiments show that FaSDiff outperforms state-of-the-art methods in balancing human visual quality and machine vision accuracy. The code will be released after the paper is accepted.
Learning Compatible Multi-Prize Subnetworks for Asymmetric Retrieval
Apr 16, 2025Asymmetric retrieval is a typical scenario in real-world retrieval systems, where compatible models of varying capacities are deployed on platforms with different resource configurations. Existing methods generally train pre-defined networks or subnetworks with capacities specifically designed for pre-determined platforms, using compatible learning. Nevertheless, these methods suffer from limited flexibility for multi-platform deployment. For example, when introducing a new platform into the retrieval systems, developers have to train an additional model at an appropriate capacity that is compatible with existing models via backward-compatible learning. In this paper, we propose a Prunable Network with self-compatibility, which allows developers to generate compatible subnetworks at any desired capacity through post-training pruning. Thus it allows the creation of a sparse subnetwork matching the resources of the new platform without additional training. Specifically, we optimize both the architecture and weight of subnetworks at different capacities within a dense network in compatible learning. We also design a conflict-aware gradient integration scheme to handle the gradient conflicts between the dense network and subnetworks during compatible learning. Extensive experiments on diverse benchmarks and visual backbones demonstrate the effectiveness of our method. Our code and model are available at https://github.com/Bunny-Black/PrunNet.
Prototype Perturbation for Relaxing Alignment Constraints in Backward-Compatible Learning
Mar 19, 2025The traditional paradigm to update retrieval models requires re-computing the embeddings of the gallery data, a time-consuming and computationally intensive process known as backfilling. To circumvent backfilling, Backward-Compatible Learning (BCL) has been widely explored, which aims to train a new model compatible with the old one. Many previous works focus on effectively aligning the embeddings of the new model with those of the old one to enhance the backward-compatibility. Nevertheless, such strong alignment constraints would compromise the discriminative ability of the new model, particularly when different classes are closely clustered and hard to distinguish in the old feature space. To address this issue, we propose to relax the constraints by introducing perturbations to the old feature prototypes. This allows us to align the new feature space with a pseudo-old feature space defined by these perturbed prototypes, thereby preserving the discriminative ability of the new model in backward-compatible learning. We have developed two approaches for calculating the perturbations: Neighbor-Driven Prototype Perturbation (NDPP) and Optimization-Driven Prototype Perturbation (ODPP). Particularly, they take into account the feature distributions of not only the old but also the new models to obtain proper perturbations along with new model updating. Extensive experiments on the landmark and commodity datasets demonstrate that our approaches perform favorably against state-of-the-art BCL algorithms.
ZeroBP: Learning Position-Aware Correspondence for Zero-shot 6D Pose Estimation in Bin-Picking
Feb 03, 2025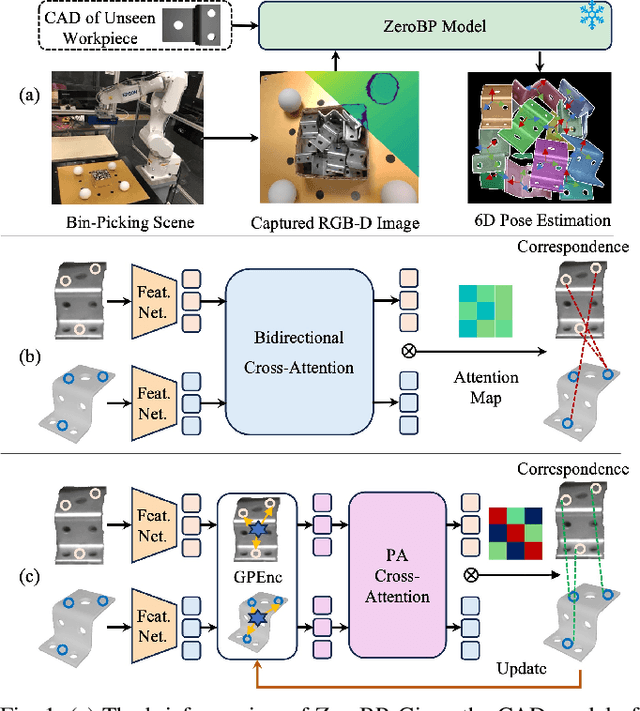



Bin-picking is a practical and challenging robotic manipulation task, where accurate 6D pose estimation plays a pivotal role. The workpieces in bin-picking are typically textureless and randomly stacked in a bin, which poses a significant challenge to 6D pose estimation. Existing solutions are typically learning-based methods, which require object-specific training. Their efficiency of practical deployment for novel workpieces is highly limited by data collection and model retraining. Zero-shot 6D pose estimation is a potential approach to address the issue of deployment efficiency. Nevertheless, existing zero-shot 6D pose estimation methods are designed to leverage feature matching to establish point-to-point correspondences for pose estimation, which is less effective for workpieces with textureless appearances and ambiguous local regions. In this paper, we propose ZeroBP, a zero-shot pose estimation framework designed specifically for the bin-picking task. ZeroBP learns Position-Aware Correspondence (PAC) between the scene instance and its CAD model, leveraging both local features and global positions to resolve the mismatch issue caused by ambiguous regions with similar shapes and appearances. Extensive experiments on the ROBI dataset demonstrate that ZeroBP outperforms state-of-the-art zero-shot pose estimation methods, achieving an improvement of 9.1% in average recall of correct poses.
MambaVLT: Time-Evolving Multimodal State Space Model for Vision-Language Tracking
Nov 23, 2024



The vision-language tracking task aims to perform object tracking based on various modality references. Existing Transformer-based vision-language tracking methods have made remarkable progress by leveraging the global modeling ability of self-attention. However, current approaches still face challenges in effectively exploiting the temporal information and dynamically updating reference features during tracking. Recently, the State Space Model (SSM), known as Mamba, has shown astonishing ability in efficient long-sequence modeling. Particularly, its state space evolving process demonstrates promising capabilities in memorizing multimodal temporal information with linear complexity. Witnessing its success, we propose a Mamba-based vision-language tracking model to exploit its state space evolving ability in temporal space for robust multimodal tracking, dubbed MambaVLT. In particular, our approach mainly integrates a time-evolving hybrid state space block and a selective locality enhancement block, to capture contextual information for multimodal modeling and adaptive reference feature update. Besides, we introduce a modality-selection module that dynamically adjusts the weighting between visual and language references, mitigating potential ambiguities from either reference type. Extensive experimental results show that our method performs favorably against state-of-the-art trackers across diverse benchmarks.
Driving Referring Video Object Segmentation with Vision-Language Pre-trained Models
May 17, 2024



The crux of Referring Video Object Segmentation (RVOS) lies in modeling dense text-video relations to associate abstract linguistic concepts with dynamic visual contents at pixel-level. Current RVOS methods typically use vision and language models pre-trained independently as backbones. As images and texts are mapped to uncoupled feature spaces, they face the arduous task of learning Vision-Language~(VL) relation modeling from scratch. Witnessing the success of Vision-Language Pre-trained (VLP) models, we propose to learn relation modeling for RVOS based on their aligned VL feature space. Nevertheless, transferring VLP models to RVOS is a deceptively challenging task due to the substantial gap between the pre-training task (image/region-level prediction) and the RVOS task (pixel-level prediction in videos). In this work, we introduce a framework named VLP-RVOS to address this transfer challenge. We first propose a temporal-aware prompt-tuning method, which not only adapts pre-trained representations for pixel-level prediction but also empowers the vision encoder to model temporal clues. We further propose to perform multi-stage VL relation modeling while and after feature extraction for comprehensive VL understanding. Besides, we customize a cube-frame attention mechanism for spatial-temporal reasoning. Extensive experiments demonstrate that our method outperforms state-of-the-art algorithms and exhibits strong generalization abilities.