 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrune Redundancy, Preserve Essence: Vision Token Compression in VLMs via Synergistic Importance-Diversity
Mar 11, 2026Vision-language models (VLMs) face significant computational inefficiencies caused by excessive generation of visual tokens. While prior work shows that a large fraction of visual tokens are redundant, existing compression methods struggle to balance importance preservation and information diversity. To address this, we propose PruneSID, a training-free Synergistic Importance-Diversity approach featuring a two-stage pipeline: (1) Principal Semantic Components Analysis (PSCA) for clustering tokens into semantically coherent groups, ensuring comprehensive concept coverage, and (2) Intra-group Non-Maximum Suppression (NMS) for pruning redundant tokens while preserving key representative tokens within each group. Additionally, PruneSID incorporates an information-aware dynamic compression ratio mechanism that optimizes token compression rates based on image complexity, enabling more effective average information preservation across diverse scenes. Extensive experiments demonstrate state-of-the-art performance, achieving 96.3% accuracy on LLaVA-1.5 with only 11.1% token retention, and 92.8% accuracy at extreme compression rates (5.6%) on LLaVA-NeXT, outperforming prior methods by 2.5% with 7.8 $\times$ faster prefilling speed compared to the original model. Our framework generalizes across diverse VLMs and both image and video modalities, showcasing strong cross-modal versatility. Code is available at https://github.com/ZhengyaoFang/PruneSID.
Too Vivid to Be Real? Benchmarking and Calibrating Generative Color Fidelity
Mar 11, 2026Recent advances in text-to-image (T2I) generation have greatly improved visual quality, yet producing images that appear visually authentic to real-world photography remains challenging. This is partly due to biases in existing evaluation paradigms: human ratings and preference-trained metrics often favor visually vivid images with exaggerated saturation and contrast, which make generations often too vivid to be real even when prompted for realistic-style images. To address this issue, we present Color Fidelity Dataset (CFD) and Color Fidelity Metric (CFM) for objective evaluation of color fidelity in realistic-style generations. CFD contains over 1.3M real and synthetic images with ordered levels of color realism, while CFM employs a multimodal encoder to learn perceptual color fidelity. In addition, we propose a training-free Color Fidelity Refinement (CFR) that adaptively modulates spatial-temporal guidance scale in generation, thereby enhancing color authenticity. Together, CFD supports CFM for assessment, whose learned attention further guides CFR to refine T2I fidelity, forming a progressive framework for assessing and improving color fidelity in realistic-style T2I generation. The dataset and code are available at https://github.com/ZhengyaoFang/CFM.
DiffTrans: Differentiable Geometry-Materials Decomposition for Reconstructing Transparent Objects
Feb 28, 2026Reconstructing transparent objects from a set of multi-view images is a challenging task due to the complicated nature and indeterminate behavior of light propagation. Typical methods are primarily tailored to specific scenarios, such as objects following a uniform topology, exhibiting ideal transparency and surface specular reflections, or with only surface materials, which substantially constrains their practical applicability in real-world settings. In this work, we propose a differentiable rendering framework for transparent objects, dubbed DiffTrans, which allows for efficient decomposition and reconstruction of the geometry and materials of transparent objects, thereby reconstructing transparent objects accurately in intricate scenes with diverse topology and complex texture. Specifically, we first utilize FlexiCubes with dilation and smoothness regularization as the iso-surface representation to reconstruct an initial geometry efficiently from the multi-view object silhouette. Meanwhile, we employ the environment light radiance field to recover the environment of the scene. Then we devise a recursive differentiable ray tracer to further optimize the geometry, index of refraction and absorption rate simultaneously in a unified and end-to-end manner, leading to high-quality reconstruction of transparent objects in intricate scenes. A prominent advantage of the designed ray tracer is that it can be implemented in CUDA, enabling a significantly reduced computational cost. Extensive experiments on multiple benchmarks demonstrate the superior reconstruction performance of our DiffTrans compared with other methods, especially in intricate scenes involving transparent objects with diverse topology and complex texture. The code is available at https://github.com/lcp29/DiffTrans.
Prompt Tuning for CLIP on the Pretrained Manifold
Feb 22, 2026Prompt tuning introduces learnable prompt vectors that adapt pretrained vision-language models to downstream tasks in a parameter-efficient manner. However, under limited supervision, prompt tuning alters pretrained representations and drives downstream features away from the pretrained manifold toward directions that are unfavorable for transfer. This drift degrades generalization. To address this limitation, we propose ManiPT, a framework that performs prompt tuning on the pretrained manifold. ManiPT introduces cosine consistency constraints in both the text and image modalities to confine the learned representations within the pretrained geometric neighborhood. Furthermore, we introduce a structural bias that enforces incremental corrections, guiding the adaptation along transferable directions to mitigate reliance on shortcut learning. From a theoretical perspective, ManiPT alleviates overfitting tendencies under limited data. Our experiments cover four downstream settings: unseen-class generalization, few-shot classification, cross-dataset transfer, and domain generalization. Across these settings, ManiPT achieves higher average performance than baseline methods. Notably, ManiPT provides an explicit perspective on how prompt tuning overfits under limited supervision.
Learning Compatible Multi-Prize Subnetworks for Asymmetric Retrieval
Apr 16, 2025Asymmetric retrieval is a typical scenario in real-world retrieval systems, where compatible models of varying capacities are deployed on platforms with different resource configurations. Existing methods generally train pre-defined networks or subnetworks with capacities specifically designed for pre-determined platforms, using compatible learning. Nevertheless, these methods suffer from limited flexibility for multi-platform deployment. For example, when introducing a new platform into the retrieval systems, developers have to train an additional model at an appropriate capacity that is compatible with existing models via backward-compatible learning. In this paper, we propose a Prunable Network with self-compatibility, which allows developers to generate compatible subnetworks at any desired capacity through post-training pruning. Thus it allows the creation of a sparse subnetwork matching the resources of the new platform without additional training. Specifically, we optimize both the architecture and weight of subnetworks at different capacities within a dense network in compatible learning. We also design a conflict-aware gradient integration scheme to handle the gradient conflicts between the dense network and subnetworks during compatible learning. Extensive experiments on diverse benchmarks and visual backbones demonstrate the effectiveness of our method. Our code and model are available at https://github.com/Bunny-Black/PrunNet.
Recognition-Synergistic Scene Text Editing
Mar 11, 2025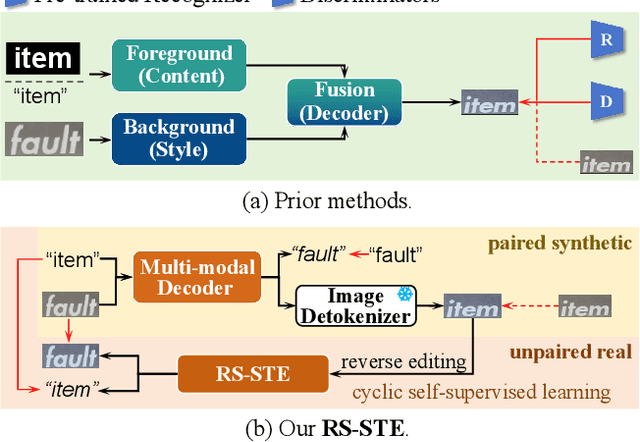
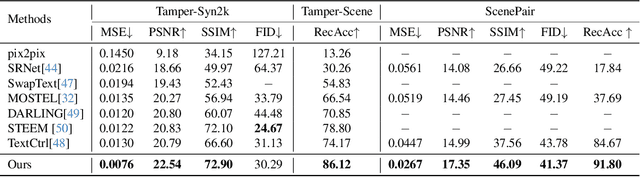
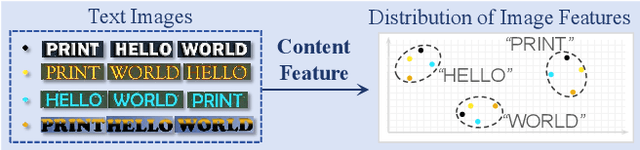
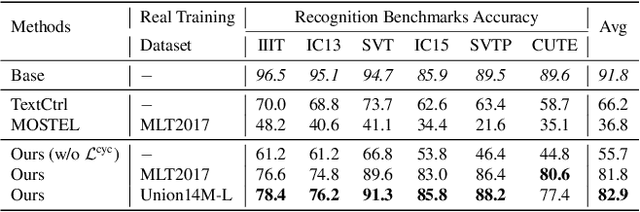
Scene text editing aims to modify text content within scene images while maintaining style consistency. Traditional methods achieve this by explicitly disentangling style and content from the source image and then fusing the style with the target content, while ensuring content consistency using a pre-trained recognition model. Despite notable progress, these methods suffer from complex pipelines, leading to suboptimal performance in complex scenarios. In this work, we introduce Recognition-Synergistic Scene Text Editing (RS-STE), a novel approach that fully exploits the intrinsic synergy of text recognition for editing. Our model seamlessly integrates text recognition with text editing within a unified framework, and leverages the recognition model's ability to implicitly disentangle style and content while ensuring content consistency. Specifically, our approach employs a multi-modal parallel decoder based on transformer architecture, which predicts both text content and stylized images in parallel. Additionally, our cyclic self-supervised fine-tuning strategy enables effective training on unpaired real-world data without ground truth, enhancing style and content consistency through a twice-cyclic generation process. Built on a relatively simple architecture, \mymodel achieves state-of-the-art performance on both synthetic and real-world benchmarks, and further demonstrates the effectiveness of leveraging the generated hard cases to boost the performance of downstream recognition tasks. Code is available at https://github.com/ZhengyaoFang/RS-STE.
UniVoxel: Fast Inverse Rendering by Unified Voxelization of Scene Representation
Jul 28, 2024



Typical inverse rendering methods focus on learning implicit neural scene representations by modeling the geometry, materials and illumination separately, which entails significant computations for optimization. In this work we design a Unified Voxelization framework for explicit learning of scene representations, dubbed UniVoxel, which allows for efficient modeling of the geometry, materials and illumination jointly, thereby accelerating the inverse rendering significantly. To be specific, we propose to encode a scene into a latent volumetric representation, based on which the geometry, materials and illumination can be readily learned via lightweight neural networks in a unified manner. Particularly, an essential design of UniVoxel is that we leverage local Spherical Gaussians to represent the incident light radiance, which enables the seamless integration of modeling illumination into the unified voxelization framework. Such novel design enables our UniVoxel to model the joint effects of direct lighting, indirect lighting and light visibility efficiently without expensive multi-bounce ray tracing. Extensive experiments on multiple benchmarks covering diverse scenes demonstrate that UniVoxel boosts the optimization efficiency significantly compared to other methods, reducing the per-scene training time from hours to 18 minutes, while achieving favorable reconstruction quality. Code is available at https://github.com/freemantom/UniVoxel.
WeCromCL: Weakly Supervised Cross-Modality Contrastive Learning for Transcription-only Supervised Text Spotting
Jul 28, 2024Transcription-only Supervised Text Spotting aims to learn text spotters relying only on transcriptions but no text boundaries for supervision, thus eliminating expensive boundary annotation. The crux of this task lies in locating each transcription in scene text images without location annotations. In this work, we formulate this challenging problem as a Weakly Supervised Cross-modality Contrastive Learning problem, and design a simple yet effective model dubbed WeCromCL that is able to detect each transcription in a scene image in a weakly supervised manner. Unlike typical methods for cross-modality contrastive learning that focus on modeling the holistic semantic correlation between an entire image and a text description, our WeCromCL conducts atomistic contrastive learning to model the character-wise appearance consistency between a text transcription and its correlated region in a scene image to detect an anchor point for the transcription in a weakly supervised manner. The detected anchor points by WeCromCL are further used as pseudo location labels to guide the learning of text spotting. Extensive experiments on four challenging benchmarks demonstrate the superior performance of our model over other methods. Code will be released.
Domain-Rectifying Adapter for Cross-Domain Few-Shot Segmentation
Apr 16, 2024



Few-shot semantic segmentation (FSS) has achieved great success on segmenting objects of novel classes, supported by only a few annotated samples. However, existing FSS methods often underperform in the presence of domain shifts, especially when encountering new domain styles that are unseen during training. It is suboptimal to directly adapt or generalize the entire model to new domains in the few-shot scenario. Instead, our key idea is to adapt a small adapter for rectifying diverse target domain styles to the source domain. Consequently, the rectified target domain features can fittingly benefit from the well-optimized source domain segmentation model, which is intently trained on sufficient source domain data. Training domain-rectifying adapter requires sufficiently diverse target domains. We thus propose a novel local-global style perturbation method to simulate diverse potential target domains by perturbating the feature channel statistics of the individual images and collective statistics of the entire source domain, respectively. Additionally, we propose a cyclic domain alignment module to facilitate the adapter effectively rectifying domains using a reverse domain rectification supervision. The adapter is trained to rectify the image features from diverse synthesized target domains to align with the source domain. During testing on target domains, we start by rectifying the image features and then conduct few-shot segmentation on the domain-rectified features. Extensive experiments demonstrate the effectiveness of our method, achieving promising results on cross-domain few-shot semantic segmentation tasks. Our code is available at https://github.com/Matt-Su/DR-Adapter.
BiTA: Bi-Directional Tuning for Lossless Acceleration in Large Language Models
Jan 25, 2024Large language models (LLMs) commonly employ autoregressive generation during inference, leading to high memory bandwidth demand and consequently extended latency. To mitigate this inefficiency, we present Bi-directional Tuning for lossless Acceleration (BiTA), an innovative method expediting LLMs via streamlined semi-autoregressive generation and draft verification. Inspired by the concept of prompt tuning, we enhance LLMs with a parameter-efficient design called bi-directional tuning for the capability in semi-autoregressive generation. Employing efficient tree-based decoding, the models perform draft candidate generation and verification in parallel, ensuring outputs identical to their autoregressive counterparts under greedy sampling. BiTA serves as a lightweight plug-in module, seamlessly boosting the inference efficiency of existing LLMs without requiring additional assistance models or incurring significant extra memory costs. Applying the proposed BiTA, LLaMA-2-70B-Chat achieves a 2.7$\times$ speedup on the MT-Bench benchmark. Extensive experiments confirm our method surpasses state-of-the-art acceleration techniques.