 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewarding the Scientific Process: Process-Level Reward Modeling for Agentic Data Analysis
Apr 27, 2026Process Reward Models (PRMs) have achieved remarkable success in augmenting the reasoning capabilities of Large Language Models (LLMs) within static domains such as mathematics. However, their potential in dynamic data analysis tasks remains underexplored. In this work, we first present a empirical study revealing that general-domain PRMs struggle to supervise data analysis agents. Specifically, they fail to detect silent errors, logical flaws that yield incorrect results without triggering interpreter exceptions, and erroneously penalize exploratory actions, mistaking necessary trial-and-error exploration for grounding failures. To bridge this gap, we introduce DataPRM, a novel environment-aware generative process reward model that (1) can serve as an active verifier, autonomously interacting with the environment to probe intermediate execution states and uncover silent errors, and (2) employs a reflection-aware ternary reward strategy that distinguishes between correctable grounding errors and irrecoverable mistakes. We design a scalable pipeline to construct over 8K high-quality training instances for DataPRM via diversity-driven trajectory generation and knowledge-augmented step-level annotation. Experimental results demonstrate that DataPRM improves downstream policy LLMs by 7.21% on ScienceAgentBench and 11.28% on DABStep using Best-of-N inference. Notably, with only 4B parameters, DataPRM outperforms strong baselines, and exhibits robust generalizability across diverse Test-Time Scaling strategies. Furthermore, integrating DataPRM into Reinforcement Learning yields substantial gains over outcome-reward baselines, achieving 78.73% on DABench and 64.84% on TableBench, validating the effectiveness of process reward supervision. Code is available at https://github.com/zjunlp/DataMind.
StructMem: Structured Memory for Long-Horizon Behavior in LLMs
Apr 23, 2026Long-term conversational agents need memory systems that capture relationships between events, not merely isolated facts, to support temporal reasoning and multi-hop question answering. Current approaches face a fundamental trade-off: flat memory is efficient but fails to model relational structure, while graph-based memory enables structured reasoning at the cost of expensive and fragile construction. To address these issues, we propose \textbf{StructMem}, a structure-enriched hierarchical memory framework that preserves event-level bindings and induces cross-event connections. By temporally anchoring dual perspectives and performing periodic semantic consolidation, StructMem improves temporal reasoning and multi-hop performance on \texttt{LoCoMo}, while substantially reducing token usage, API calls, and runtime compared to prior memory systems, see https://github.com/zjunlp/LightMem .
LLaDA2.1: Speeding Up Text Diffusion via Token Editing
Feb 09, 2026While LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization, the delicate equilibrium between decoding speed and generation quality has remained an elusive frontier. Today, we unveil LLaDA2.1, a paradigm shift designed to transcend this trade-off. By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme, we introduce a joint, configurable threshold-decoding scheme. This structural innovation gives rise to two distinct personas: the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output; and the Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade. Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs, anchored by specialized techniques for stable gradient estimation. This alignment not only sharpens reasoning precision but also elevates instruction-following fidelity, bridging the chasm between diffusion dynamics and complex human intent. We culminate this work by releasing LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B). Across 33 rigorous benchmarks, LLaDA2.1 delivers strong task performance and lightning-fast decoding speed. Despite its 100B volume, on coding tasks it attains an astounding 892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench.
Can We Predict Before Executing Machine Learning Agents?
Jan 09, 2026Autonomous machine learning agents have revolutionized scientific discovery, yet they remain constrained by a Generate-Execute-Feedback paradigm. Previous approaches suffer from a severe Execution Bottleneck, as hypothesis evaluation relies strictly on expensive physical execution. To bypass these physical constraints, we internalize execution priors to substitute costly runtime checks with instantaneous predictive reasoning, drawing inspiration from World Models. In this work, we formalize the task of Data-centric Solution Preference and construct a comprehensive corpus of 18,438 pairwise comparisons. We demonstrate that LLMs exhibit significant predictive capabilities when primed with a Verified Data Analysis Report, achieving 61.5% accuracy and robust confidence calibration. Finally, we instantiate this framework in FOREAGENT, an agent that employs a Predict-then-Verify loop, achieving a 6x acceleration in convergence while surpassing execution-based baselines by +6%. Our code and dataset will be publicly available soon at https://github.com/zjunlp/predict-before-execute.
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
MSC-180: A Benchmark for Automated Formal Theorem Proving from Mathematical Subject Classification
Dec 20, 2025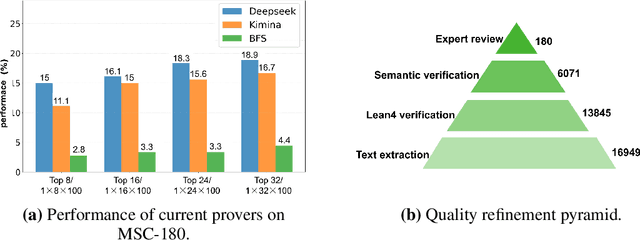



Automated Theorem Proving (ATP) represents a core research direction in artificial intelligence for achieving formal reasoning and verification, playing a significant role in advancing machine intelligence. However, current large language model (LLM)-based theorem provers suffer from limitations such as restricted domain coverage and weak generalization in mathematical reasoning. To address these issues, we propose MSC-180, a benchmark for evaluation based on the MSC2020 mathematical subject classification. It comprises 180 formal verification problems, 3 advanced problems from each of 60 mathematical branches, spanning from undergraduate to graduate levels. Each problem has undergone multiple rounds of verification and refinement by domain experts to ensure formal accuracy. Evaluations of state-of-the-art LLM-based theorem provers under the pass@32 setting reveal that the best model achieves only an 18.89% overall pass rate, with prominent issues including significant domain bias (maximum domain coverage 41.7%) and a difficulty gap (significantly lower pass rates on graduate-level problems). To further quantify performance variability across mathematical domains, we introduce the coefficient of variation (CV) as an evaluation metric. The observed CV values are 4-6 times higher than the statistical high-variability threshold, indicating that the models still rely on pattern matching from training corpora rather than possessing transferable reasoning mechanisms and systematic generalization capabilities. MSC-180, together with its multi-dimensional evaluation framework, provides a discriminative and systematic benchmark for driving the development of next-generation AI systems with genuine mathematical reasoning abilities.
Task-Aware Retrieval Augmentation for Dynamic Recommendation
Nov 16, 2025Dynamic recommendation systems aim to provide personalized suggestions by modeling temporal user-item interactions across time-series behavioral data. Recent studies have leveraged pre-trained dynamic graph neural networks (GNNs) to learn user-item representations over temporal snapshot graphs. However, fine-tuning GNNs on these graphs often results in generalization issues due to temporal discrepancies between pre-training and fine-tuning stages, limiting the model's ability to capture evolving user preferences. To address this, we propose TarDGR, a task-aware retrieval-augmented framework designed to enhance generalization capability by incorporating task-aware model and retrieval-augmentation. Specifically, TarDGR introduces a Task-Aware Evaluation Mechanism to identify semantically relevant historical subgraphs, enabling the construction of task-specific datasets without manual labeling. It also presents a Graph Transformer-based Task-Aware Model that integrates semantic and structural encodings to assess subgraph relevance. During inference, TarDGR retrieves and fuses task-aware subgraphs with the query subgraph, enriching its representation and mitigating temporal generalization issues. Experiments on multiple large-scale dynamic graph datasets demonstrate that TarDGR consistently outperforms state-of-the-art methods, with extensive empirical evidence underscoring its superior accuracy and generalization capabilities.
EvolProver: Advancing Automated Theorem Proving by Evolving Formalized Problems via Symmetry and Difficulty
Oct 01, 2025



Large Language Models (LLMs) for formal theorem proving have shown significant promise, yet they often lack generalizability and are fragile to even minor transformations of problem statements. To address this limitation, we introduce a novel data augmentation pipeline designed to enhance model robustness from two perspectives: symmetry and difficulty. From the symmetry perspective, we propose two complementary methods: EvolAST, an Abstract Syntax Tree (AST) based approach that targets syntactic symmetry to generate semantically equivalent problem variants, and EvolDomain, which leverages LLMs to address semantic symmetry by translating theorems across mathematical domains. From the difficulty perspective, we propose EvolDifficulty, which uses carefully designed evolutionary instructions to guide LLMs in generating new theorems with a wider range of difficulty. We then use the evolved data to train EvolProver, a 7B-parameter non-reasoning theorem prover. EvolProver establishes a new state-of-the-art (SOTA) on FormalMATH-Lite with a 53.8% pass@32 rate, surpassing all models of comparable size, including reasoning-based models. It also sets new SOTA records for non-reasoning models on MiniF2F-Test (69.8% pass@32), Ineq-Comp-Seed (52.2% pass@32), and Ineq-Comp-Transformed (34.0% pass@32). Ablation studies further confirm our data augmentation pipeline's effectiveness across multiple benchmarks.
Automated Formalization via Conceptual Retrieval-Augmented LLMs
Aug 09, 2025



Interactive theorem provers (ITPs) require manual formalization, which is labor-intensive and demands expert knowledge. While automated formalization offers a potential solution, it faces two major challenges: model hallucination (e.g., undefined predicates, symbol misuse, and version incompatibility) and the semantic gap caused by ambiguous or missing premises in natural language descriptions. To address these issues, we propose CRAMF, a Concept-driven Retrieval-Augmented Mathematical Formalization framework. CRAMF enhances LLM-based autoformalization by retrieving formal definitions of core mathematical concepts, providing contextual grounding during code generation. However, applying retrieval-augmented generation (RAG) in this setting is non-trivial due to the lack of structured knowledge bases, the polymorphic nature of mathematical concepts, and the high precision required in formal retrieval. We introduce a framework for automatically constructing a concept-definition knowledge base from Mathlib4, the standard mathematical library for the Lean 4 theorem prover, indexing over 26,000 formal definitions and 1,000+ core mathematical concepts. To address conceptual polymorphism, we propose contextual query augmentation with domain- and application-level signals. In addition, we design a dual-channel hybrid retrieval strategy with reranking to ensure accurate and relevant definition retrieval. Experiments on miniF2F, ProofNet, and our newly proposed AdvancedMath benchmark show that CRAMF can be seamlessly integrated into LLM-based autoformalizers, yielding consistent improvements in translation accuracy, achieving up to 62.1% and an average of 29.9% relative improvement.
Why Do Open-Source LLMs Struggle with Data Analysis? A Systematic Empirical Study
Jun 24, 2025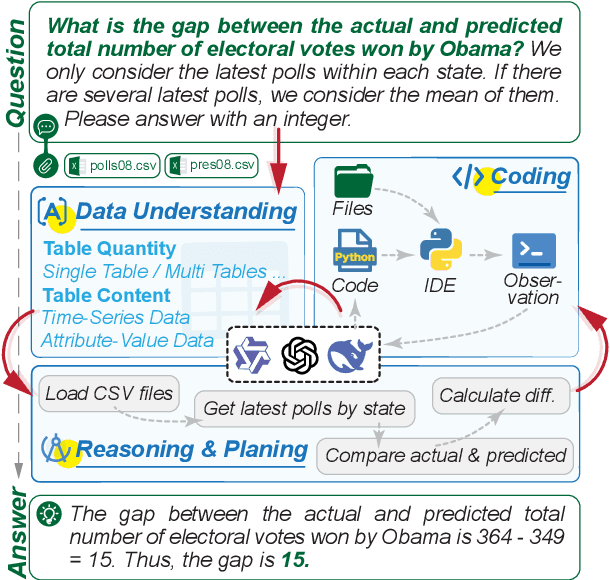
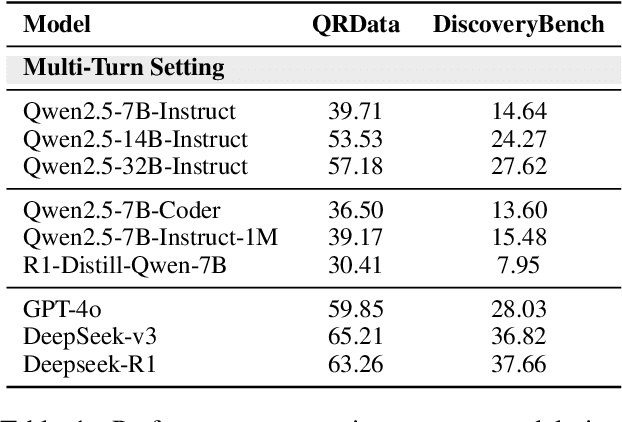
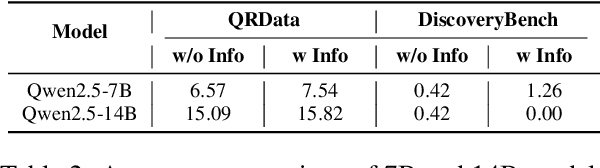
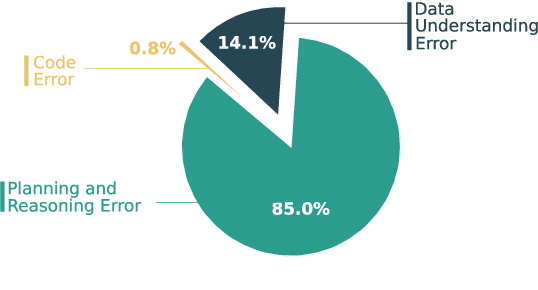
Large Language Models (LLMs) hold promise in automating data analysis tasks, yet open-source models face significant limitations in these kinds of reasoning-intensive scenarios. In this work, we investigate strategies to enhance the data analysis capabilities of open-source LLMs. By curating a seed dataset of diverse, realistic scenarios, we evaluate models across three dimensions: data understanding, code generation, and strategic planning. Our analysis reveals three key findings: (1) Strategic planning quality serves as the primary determinant of model performance; (2) Interaction design and task complexity significantly influence reasoning capabilities; (3) Data quality demonstrates a greater impact than diversity in achieving optimal performance. We leverage these insights to develop a data synthesis methodology, demonstrating significant improvements in open-source LLMs' analytical reasoning capabilities.