 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Cognitive Task Generation for In-Situ Evaluation of Embodied Agents
Feb 05, 2026As general intelligent agents are poised for widespread deployment in diverse households, evaluation tailored to each unique unseen 3D environment has become a critical prerequisite. However, existing benchmarks suffer from severe data contamination and a lack of scene specificity, inadequate for assessing agent capabilities in unseen settings. To address this, we propose a dynamic in-situ task generation method for unseen environments inspired by human cognition. We define tasks through a structured graph representation and construct a two-stage interaction-evolution task generation system for embodied agents (TEA). In the interaction stage, the agent actively interacts with the environment, creating a loop between task execution and generation that allows for continuous task generation. In the evolution stage, task graph modeling allows us to recombine and reuse existing tasks to generate new ones without external data. Experiments across 10 unseen scenes demonstrate that TEA automatically generated 87,876 tasks in two cycles, which human verification confirmed to be physically reasonable and encompassing essential daily cognitive capabilities. Benchmarking SOTA models against humans on our in-situ tasks reveals that models, despite excelling on public benchmarks, perform surprisingly poorly on basic perception tasks, severely lack 3D interaction awareness and show high sensitivity to task types in reasoning. These sobering findings highlight the necessity of in-situ evaluation before deploying agents into real-world human environments.
TongSIM: A General Platform for Simulating Intelligent Machines
Dec 23, 2025As artificial intelligence (AI) rapidly advances, especially in multimodal large language models (MLLMs), research focus is shifting from single-modality text processing to the more complex domains of multimodal and embodied AI. Embodied intelligence focuses on training agents within realistic simulated environments, leveraging physical interaction and action feedback rather than conventionally labeled datasets. Yet, most existing simulation platforms remain narrowly designed, each tailored to specific tasks. A versatile, general-purpose training environment that can support everything from low-level embodied navigation to high-level composite activities, such as multi-agent social simulation and human-AI collaboration, remains largely unavailable. To bridge this gap, we introduce TongSIM, a high-fidelity, general-purpose platform for training and evaluating embodied agents. TongSIM offers practical advantages by providing over 100 diverse, multi-room indoor scenarios as well as an open-ended, interaction-rich outdoor town simulation, ensuring broad applicability across research needs. Its comprehensive evaluation framework and benchmarks enable precise assessment of agent capabilities, such as perception, cognition, decision-making, human-robot cooperation, and spatial and social reasoning. With features like customized scenes, task-adaptive fidelity, diverse agent types, and dynamic environmental simulation, TongSIM delivers flexibility and scalability for researchers, serving as a unified platform that accelerates training, evaluation, and advancement toward general embodied intelligence.
Afterburner: Reinforcement Learning Facilitates Self-Improving Code Efficiency Optimization
May 29, 2025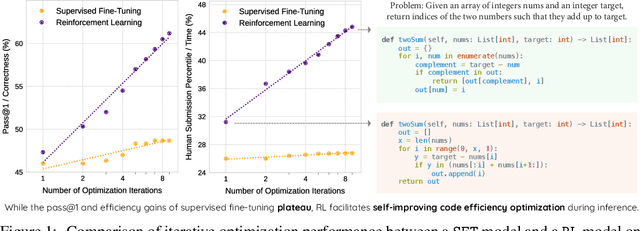
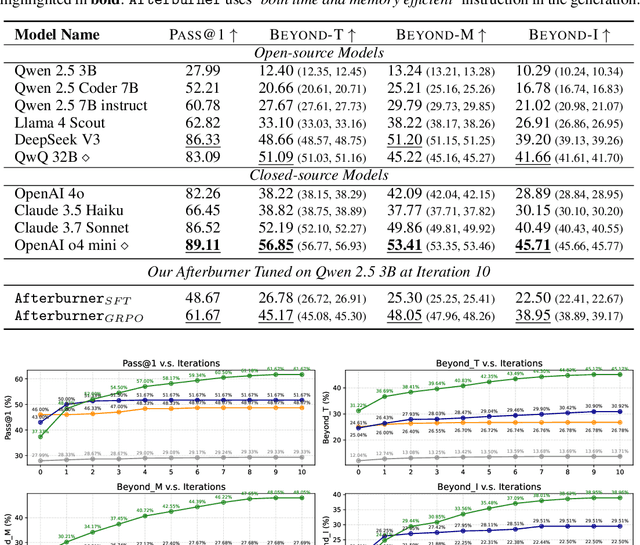
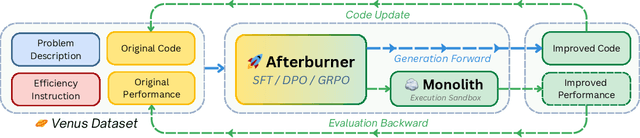
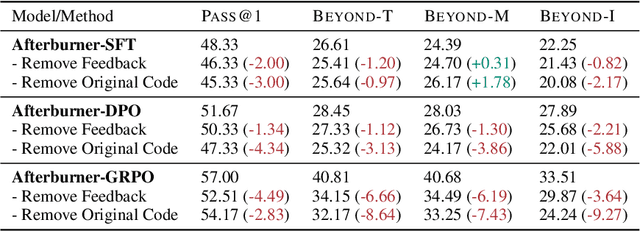
Large Language Models (LLMs) generate functionally correct solutions but often fall short in code efficiency, a critical bottleneck for real-world deployment. In this paper, we introduce a novel test-time iterative optimization framework to address this, employing a closed-loop system where LLMs iteratively refine code based on empirical performance feedback from an execution sandbox. We explore three training strategies: Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Group Relative Policy Optimization~(GRPO). Experiments on our Venus dataset and the APPS benchmark show that SFT and DPO rapidly saturate in efficiency gains. In contrast, GRPO, using reinforcement learning (RL) with execution feedback, continuously optimizes code performance, significantly boosting both pass@1 (from 47% to 62%) and the likelihood of outperforming human submissions in efficiency (from 31% to 45%). Our work demonstrates effective test-time code efficiency improvement and critically reveals the power of RL in teaching LLMs to truly self-improve code efficiency.
TableLoRA: Low-rank Adaptation on Table Structure Understanding for Large Language Models
Mar 06, 2025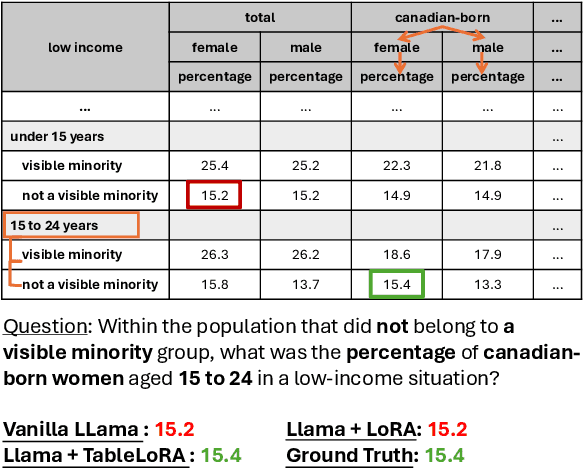
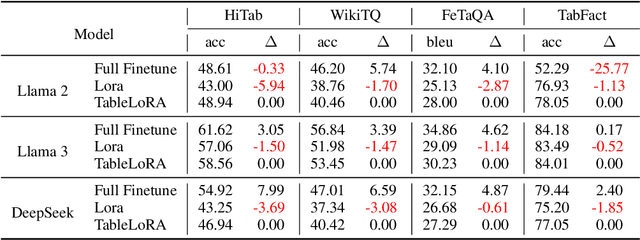
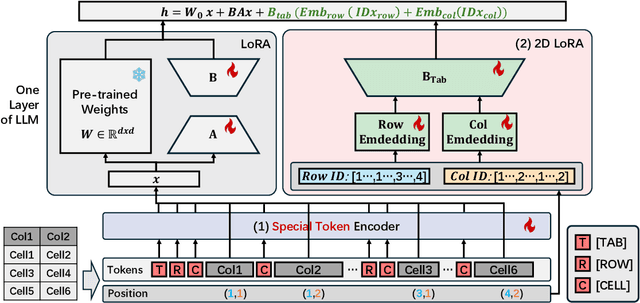
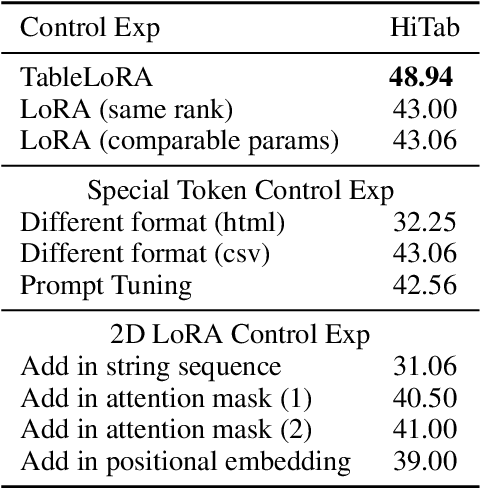
Tabular data are crucial in many fields and their understanding by large language models (LLMs) under high parameter efficiency paradigm is important. However, directly applying parameter-efficient fine-tuning (PEFT) techniques to tabular tasks presents significant challenges, particularly in terms of better table serialization and the representation of two-dimensional structured information within a one-dimensional sequence. To address this, we propose TableLoRA, a module designed to improve LLMs' understanding of table structure during PEFT. It incorporates special tokens for serializing tables with special token encoder and uses 2D LoRA to encode low-rank information on cell positions. Experiments on four tabular-related datasets demonstrate that TableLoRA consistently outperforms vanilla LoRA and surpasses various table encoding methods tested in control experiments. These findings reveal that TableLoRA, as a table-specific LoRA, enhances the ability of LLMs to process tabular data effectively, especially in low-parameter settings, demonstrating its potential as a robust solution for handling table-related tasks.
Diffusion Suction Grasping with Large-Scale Parcel Dataset
Feb 11, 2025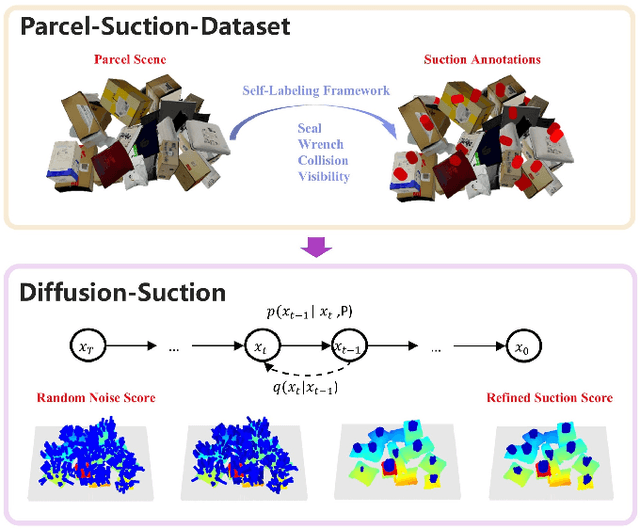

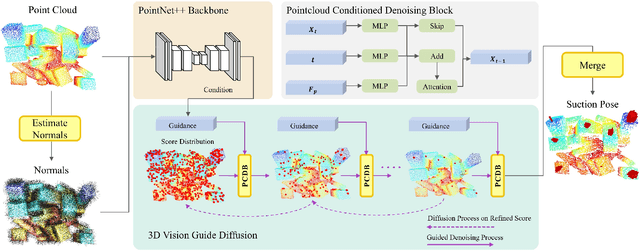

While recent advances in object suction grasping have shown remarkable progress, significant challenges persist particularly in cluttered and complex parcel handling scenarios. Two fundamental limitations hinder current approaches: (1) the lack of a comprehensive suction grasp dataset tailored for parcel manipulation tasks, and (2) insufficient adaptability to diverse object characteristics including size variations, geometric complexity, and textural diversity. To address these challenges, we present Parcel-Suction-Dataset, a large-scale synthetic dataset containing 25 thousand cluttered scenes with 410 million precision-annotated suction grasp poses. This dataset is generated through our novel geometric sampling algorithm that enables efficient generation of optimal suction grasps incorporating both physical constraints and material properties. We further propose Diffusion-Suction, an innovative framework that reformulates suction grasp prediction as a conditional generation task through denoising diffusion probabilistic models. Our method iteratively refines random noise into suction grasp score maps through visual-conditioned guidance from point cloud observations, effectively learning spatial point-wise affordances from our synthetic dataset. Extensive experiments demonstrate that the simple yet efficient Diffusion-Suction achieves new state-of-the-art performance compared to previous models on both Parcel-Suction-Dataset and the public SuctionNet-1Billion benchmark.
CONLINE: Complex Code Generation and Refinement with Online Searching and Correctness Testing
Mar 20, 2024Large Language Models (LLMs) have revolutionized code generation ability by converting natural language descriptions into executable code. However, generating complex code within real-world scenarios remains challenging due to intricate structures, subtle bugs, understanding of advanced data types, and lack of supplementary contents. To address these challenges, we introduce the CONLINE framework, which enhances code generation by incorporating planned online searches for information retrieval and automated correctness testing for iterative refinement. CONLINE also serializes the complex inputs and outputs to improve comprehension and generate test case to ensure the framework's adaptability for real-world applications. CONLINE is validated through rigorous experiments on the DS-1000 and ClassEval datasets. It shows that CONLINE substantially improves the quality of complex code generation, highlighting its potential to enhance the practicality and reliability of LLMs in generating intricate code.
Text2Analysis: A Benchmark of Table Question Answering with Advanced Data Analysis and Unclear Queries
Dec 21, 2023Tabular data analysis is crucial in various fields, and large language models show promise in this area. However, current research mostly focuses on rudimentary tasks like Text2SQL and TableQA, neglecting advanced analysis like forecasting and chart generation. To address this gap, we developed the Text2Analysis benchmark, incorporating advanced analysis tasks that go beyond the SQL-compatible operations and require more in-depth analysis. We also develop five innovative and effective annotation methods, harnessing the capabilities of large language models to enhance data quality and quantity. Additionally, we include unclear queries that resemble real-world user questions to test how well models can understand and tackle such challenges. Finally, we collect 2249 query-result pairs with 347 tables. We evaluate five state-of-the-art models using three different metrics and the results show that our benchmark presents introduces considerable challenge in the field of tabular data analysis, paving the way for more advanced research opportunities.
TAP4LLM: Table Provider on Sampling, Augmenting, and Packing Semi-structured Data for Large Language Model Reasoning
Dec 14, 2023



Table reasoning has shown remarkable progress in a wide range of table-based tasks. These challenging tasks require reasoning over both free-form natural language (NL) questions and semi-structured tabular data. However, previous table reasoning solutions suffer from significant performance degradation on "huge" tables. In addition, most existing methods struggle to reason over complex questions since they lack essential information or they are scattered in different places. To alleviate these challenges, we exploit a table provider, namely TAP4LLM, on versatile sampling, augmentation, and packing methods to achieve effective semi-structured data reasoning using large language models (LLMs), which 1) decompose raw tables into sub-tables with specific rows or columns based on the rules or semantic similarity; 2) augment table information by extracting semantic and statistical metadata from raw tables while retrieving relevant knowledge from trustworthy knowledge sources (e.g., Wolfram Alpha, Wikipedia); 3) pack sampled tables with augmented knowledge into sequence prompts for LLMs reasoning while balancing the token allocation trade-off. We show that TAP4LLM allows for different components as plug-ins, enhancing LLMs' understanding of structured data in diverse tabular tasks.
Towards Robust Numerical Question Answering: Diagnosing Numerical Capabilities of NLP Systems
Nov 14, 2022Numerical Question Answering is the task of answering questions that require numerical capabilities. Previous works introduce general adversarial attacks to Numerical Question Answering, while not systematically exploring numerical capabilities specific to the topic. In this paper, we propose to conduct numerical capability diagnosis on a series of Numerical Question Answering systems and datasets. A series of numerical capabilities are highlighted, and corresponding dataset perturbations are designed. Empirical results indicate that existing systems are severely challenged by these perturbations. E.g., Graph2Tree experienced a 53.83% absolute accuracy drop against the ``Extra'' perturbation on ASDiv-a, and BART experienced 13.80% accuracy drop against the ``Language'' perturbation on the numerical subset of DROP. As a counteracting approach, we also investigate the effectiveness of applying perturbations as data augmentation to relieve systems' lack of robust numerical capabilities. With experiment analysis and empirical studies, it is demonstrated that Numerical Question Answering with robust numerical capabilities is still to a large extent an open question. We discuss future directions of Numerical Question Answering and summarize guidelines on future dataset collection and system design.
Inferring Tabular Analysis Metadata by Infusing Distribution and Knowledge Information
Sep 02, 2022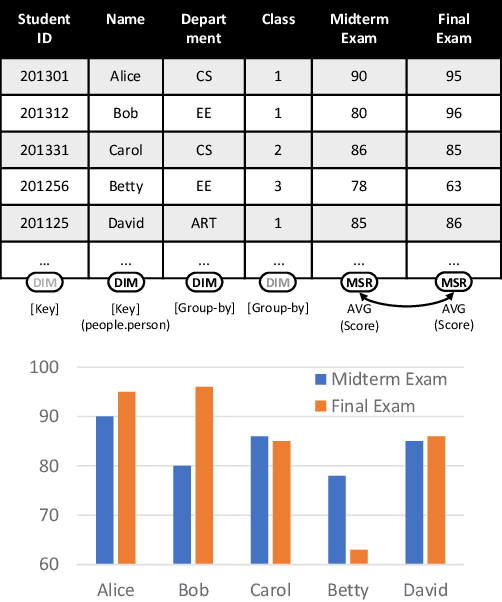
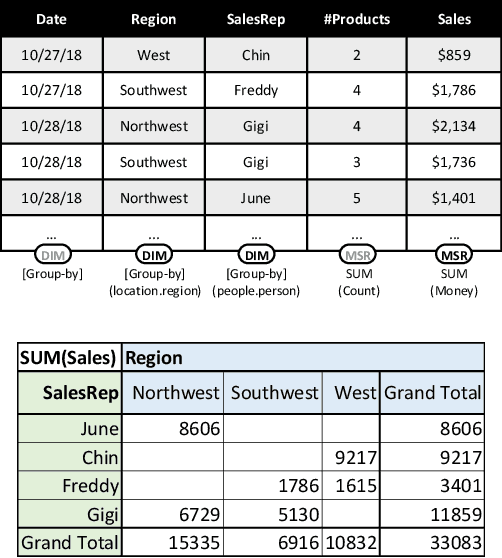
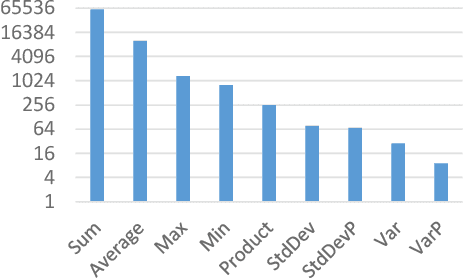
Many data analysis tasks heavily rely on a deep understanding of tables (multi-dimensional data). Across the tasks, there exist comonly used metadata attributes of table fields / columns. In this paper, we identify four such analysis metadata: Measure/dimension dichotomy, common field roles, semantic field type, and default aggregation function. While those metadata face challenges of insufficient supervision signals, utilizing existing knowledge and understanding distribution. To inference these metadata for a raw table, we propose our multi-tasking Metadata model which fuses field distribution and knowledge graph information into pre-trained tabular models. For model training and evaluation, we collect a large corpus (~582k tables from private spreadsheet and public tabular datasets) of analysis metadata by using diverse smart supervisions from downstream tasks. Our best model has accuracy = 98%, hit rate at top-1 > 67%, accuracy > 80%, and accuracy = 88% for the four analysis metadata inference tasks, respectively. It outperforms a series of baselines that are based on rules, traditional machine learning methods, and pre-trained tabular models. Analysis metadata models are deployed in a popular data analysis product, helping downstream intelligent features such as insights mining, chart / pivot table recommendation, and natural language QA...