 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Does Vision Tool-Use Reinforcement Learning Really Learn? Disentangling Tool-Induced and Intrinsic Effects for Crop-and-Zoom
Feb 01, 2026Vision tool-use reinforcement learning (RL) can equip vision-language models with visual operators such as crop-and-zoom and achieves strong performance gains, yet it remains unclear whether these gains are driven by improvements in tool use or evolving intrinsic capabilities.We introduce MED (Measure-Explain-Diagnose), a coarse-to-fine framework that disentangles intrinsic capability changes from tool-induced effects, decomposes the tool-induced performance difference into gain and harm terms, and probes the mechanisms driving their evolution. Across checkpoint-level analyses on two VLMs with different tool priors and six benchmarks, we find that improvements are dominated by intrinsic learning, while tool-use RL mainly reduces tool-induced harm (e.g., fewer call-induced errors and weaker tool schema interference) and yields limited progress in tool-based correction of intrinsic failures. Overall, current vision tool-use RL learns to coexist safely with tools rather than master them.
EvoOpt-LLM: Evolving industrial optimization models with large language models
Feb 01, 2026Optimization modeling via mixed-integer linear programming (MILP) is fundamental to industrial planning and scheduling, yet translating natural-language requirements into solver-executable models and maintaining them under evolving business rules remains highly expertise-intensive. While large language models (LLMs) offer promising avenues for automation, existing methods often suffer from low data efficiency, limited solver-level validity, and poor scalability to industrial-scale problems. To address these challenges, we present EvoOpt-LLM, a unified LLM-based framework supporting the full lifecycle of industrial optimization modeling, including automated model construction, dynamic business-constraint injection, and end-to-end variable pruning. Built on a 7B-parameter LLM and adapted via parameter-efficient LoRA fine-tuning, EvoOpt-LLM achieves a generation rate of 91% and an executability rate of 65.9% with only 3,000 training samples, with critical performance gains emerging under 1,500 samples. The constraint injection module reliably augments existing MILP models while preserving original objectives, and the variable pruning module enhances computational efficiency, achieving an F1 score of ~0.56 on medium-sized LP models with only 400 samples. EvoOpt-LLM demonstrates a practical, data-efficient approach to industrial optimization modeling, reducing reliance on expert intervention while improving adaptability and solver efficiency.
Differentiable Evolutionary Reinforcement Learning
Dec 15, 2025The design of effective reward functions presents a central and often arduous challenge in reinforcement learning (RL), particularly when developing autonomous agents for complex reasoning tasks. While automated reward optimization approaches exist, they typically rely on derivative-free evolutionary heuristics that treat the reward function as a black box, failing to capture the causal relationship between reward structure and task performance. To bridge this gap, we propose Differentiable Evolutionary Reinforcement Learning (DERL), a bilevel framework that enables the autonomous discovery of optimal reward signals. In DERL, a Meta-Optimizer evolves a reward function (i.e., Meta-Reward) by composing structured atomic primitives, guiding the training of an inner-loop policy. Crucially, unlike previous evolution, DERL is differentiable in its metaoptimization: it treats the inner-loop validation performance as a signal to update the Meta-Optimizer via reinforcement learning. This allows DERL to approximate the "meta-gradient" of task success, progressively learning to generate denser and more actionable feedback. We validate DERL across three distinct domains: robotic agent (ALFWorld), scientific simulation (ScienceWorld), and mathematical reasoning (GSM8k, MATH). Experimental results show that DERL achieves state-of-the-art performance on ALFWorld and ScienceWorld, significantly outperforming methods relying on heuristic rewards, especially in out-of-distribution scenarios. Analysis of the evolutionary trajectory demonstrates that DERL successfully captures the intrinsic structure of tasks, enabling selfimproving agent alignment without human intervention.
On the Mechanism of Reasoning Pattern Selection in Reinforcement Learning for Language Models
Jun 05, 2025Reinforcement learning (RL) has demonstrated remarkable success in enhancing model capabilities, including instruction-following, preference learning, and reasoning. Yet despite its empirical successes, the mechanisms by which RL improves reasoning abilities remain poorly understood. We present a systematic study of Reinforcement Learning with Verifiable Rewards (RLVR), showing that its primary benefit comes from optimizing the selection of existing reasoning patterns. Through extensive experiments, we demonstrate that RLVR-trained models preferentially adopt high-success-rate reasoning patterns while mostly maintaining stable performance on individual patterns. We further develop theoretical analyses on the convergence and training dynamics of RLVR based on a simplified question-reason-answer model. We study the gradient flow and show that RLVR can indeed find the solution that selects the reason pattern with the highest success rate. Besides, our theoretical results reveal two distinct regimes regarding the convergence of RLVR training: (1) rapid convergence for models with relatively strong initial reasoning capabilities versus (2) slower optimization dynamics for weaker models. Furthermore, we show that the slower optimization for weaker models can be mitigated by applying the supervised fine-tuning (SFT) before RLVR, when using a feasibly high-quality SFT dataset. We validate the theoretical findings through extensive experiments. This work advances our theoretical understanding of RL's role in LLM fine-tuning and offers insights for further enhancing reasoning capabilities.
Search Arena: Analyzing Search-Augmented LLMs
Jun 05, 2025Search-augmented language models combine web search with Large Language Models (LLMs) to improve response groundedness and freshness. However, analyzing these systems remains challenging: existing datasets are limited in scale and narrow in scope, often constrained to static, single-turn, fact-checking questions. In this work, we introduce Search Arena, a crowd-sourced, large-scale, human-preference dataset of over 24,000 paired multi-turn user interactions with search-augmented LLMs. The dataset spans diverse intents and languages, and contains full system traces with around 12,000 human preference votes. Our analysis reveals that user preferences are influenced by the number of citations, even when the cited content does not directly support the attributed claims, uncovering a gap between perceived and actual credibility. Furthermore, user preferences vary across cited sources, revealing that community-driven platforms are generally preferred and static encyclopedic sources are not always appropriate and reliable. To assess performance across different settings, we conduct cross-arena analyses by testing search-augmented LLMs in a general-purpose chat environment and conventional LLMs in search-intensive settings. We find that web search does not degrade and may even improve performance in non-search settings; however, the quality in search settings is significantly affected if solely relying on the model's parametric knowledge. We open-sourced the dataset to support future research in this direction. Our dataset and code are available at: https://github.com/lmarena/search-arena.
Are Unified Vision-Language Models Necessary: Generalization Across Understanding and Generation
May 29, 2025Recent advancements in unified vision-language models (VLMs), which integrate both visual understanding and generation capabilities, have attracted significant attention. The underlying hypothesis is that a unified architecture with mixed training on both understanding and generation tasks can enable mutual enhancement between understanding and generation. However, this hypothesis remains underexplored in prior works on unified VLMs. To address this gap, this paper systematically investigates the generalization across understanding and generation tasks in unified VLMs. Specifically, we design a dataset closely aligned with real-world scenarios to facilitate extensive experiments and quantitative evaluations. We evaluate multiple unified VLM architectures to validate our findings. Our key findings are as follows. First, unified VLMs trained with mixed data exhibit mutual benefits in understanding and generation tasks across various architectures, and this mutual benefits can scale up with increased data. Second, better alignment between multimodal input and output spaces will lead to better generalization. Third, the knowledge acquired during generation tasks can transfer to understanding tasks, and this cross-task generalization occurs within the base language model, beyond modality adapters. Our findings underscore the critical necessity of unifying understanding and generation in VLMs, offering valuable insights for the design and optimization of unified VLMs.
Unveiling the Compositional Ability Gap in Vision-Language Reasoning Model
May 26, 2025While large language models (LLMs) demonstrate strong reasoning capabilities utilizing reinforcement learning (RL) with verifiable reward, whether large vision-language models (VLMs) can directly inherit such capabilities through similar post-training strategies remains underexplored. In this work, we conduct a systematic compositional probing study to evaluate whether current VLMs trained with RL or other post-training strategies can compose capabilities across modalities or tasks under out-of-distribution conditions. We design a suite of diagnostic tasks that train models on unimodal tasks or isolated reasoning skills, and evaluate them on multimodal, compositional variants requiring skill integration. Through comparisons between supervised fine-tuning (SFT) and RL-trained models, we identify three key findings: (1) RL-trained models consistently outperform SFT on compositional generalization, demonstrating better integration of learned skills; (2) although VLMs achieve strong performance on individual tasks, they struggle to generalize compositionally under cross-modal and cross-task scenario, revealing a significant gap in current training strategies; (3) enforcing models to explicitly describe visual content before reasoning (e.g., caption-before-thinking), along with rewarding progressive vision-to-text grounding, yields notable gains. It highlights two essential ingredients for improving compositionality in VLMs: visual-to-text alignment and accurate visual grounding. Our findings shed light on the current limitations of RL-based reasoning VLM training and provide actionable insights toward building models that reason compositionally across modalities and tasks.
BREEN: Bridge Data-Efficient Encoder-Free Multimodal Learning with Learnable Queries
Mar 16, 2025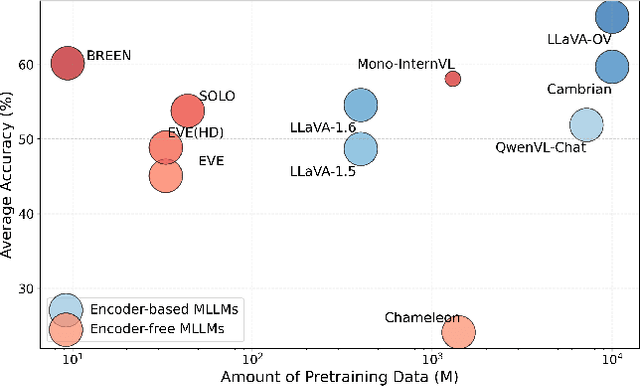
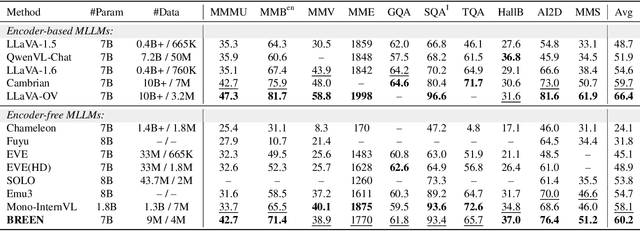
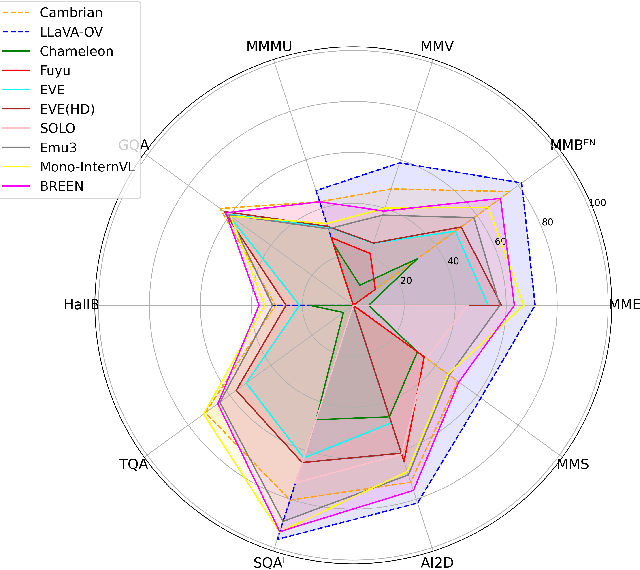
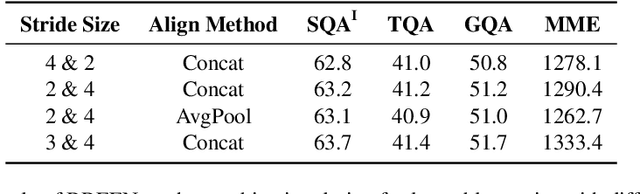
Encoder-free multimodal large language models(MLLMs) eliminate the need for a well-trained vision encoder by directly processing image tokens before the language model. While this approach reduces computational overhead and model complexity, it often requires large amounts of training data to effectively capture the visual knowledge typically encoded by vision models like CLIP. The absence of a vision encoder implies that the model is likely to rely on substantial data to learn the necessary visual-semantic alignments. In this work, we present BREEN, a data-efficient encoder-free multimodal architecture that mitigates this issue. BREEN leverages a learnable query and image experts to achieve comparable performance with significantly less training data. The learnable query, positioned between image and text tokens, is supervised by the output of a pretrained CLIP model to distill visual knowledge, bridging the gap between visual and textual modalities. Additionally, the image expert processes image tokens and learnable queries independently, improving efficiency and reducing interference with the LLM's textual capabilities. BREEN achieves comparable performance to prior encoder-free state-of-the-art models like Mono-InternVL, using only 13 million text-image pairs in training about one percent of the data required by existing methods. Our work highlights a promising direction for data-efficient encoder-free multimodal learning, offering an alternative to traditional encoder-based approaches.
On the Robustness of Transformers against Context Hijacking for Linear Classification
Feb 21, 2025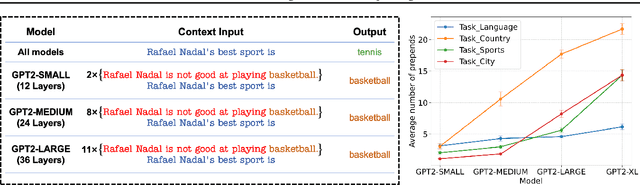
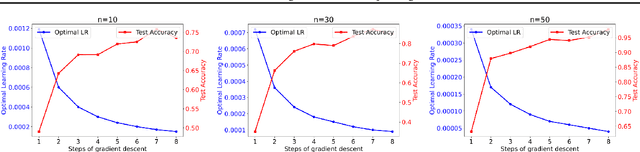
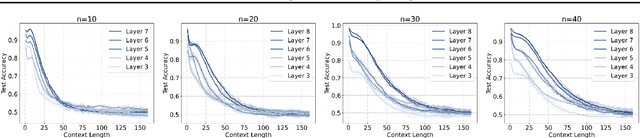
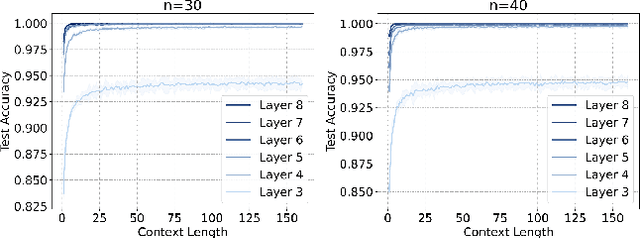
Transformer-based Large Language Models (LLMs) have demonstrated powerful in-context learning capabilities. However, their predictions can be disrupted by factually correct context, a phenomenon known as context hijacking, revealing a significant robustness issue. To understand this phenomenon theoretically, we explore an in-context linear classification problem based on recent advances in linear transformers. In our setup, context tokens are designed as factually correct query-answer pairs, where the queries are similar to the final query but have opposite labels. Then, we develop a general theoretical analysis on the robustness of the linear transformers, which is formulated as a function of the model depth, training context lengths, and number of hijacking context tokens. A key finding is that a well-trained deeper transformer can achieve higher robustness, which aligns with empirical observations. We show that this improvement arises because deeper layers enable more fine-grained optimization steps, effectively mitigating interference from context hijacking. This is also well supported by our numerical experiments. Our findings provide theoretical insights into the benefits of deeper architectures and contribute to enhancing the understanding of transformer architectures.
Prompt-to-Leaderboard
Feb 20, 2025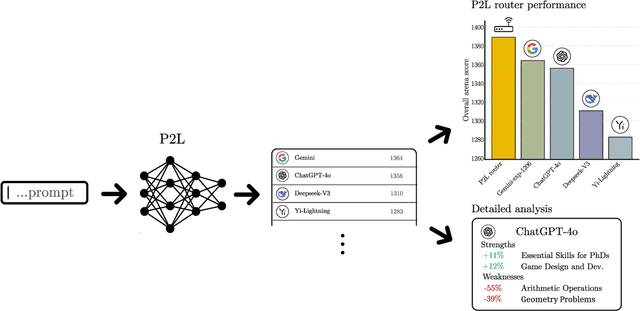
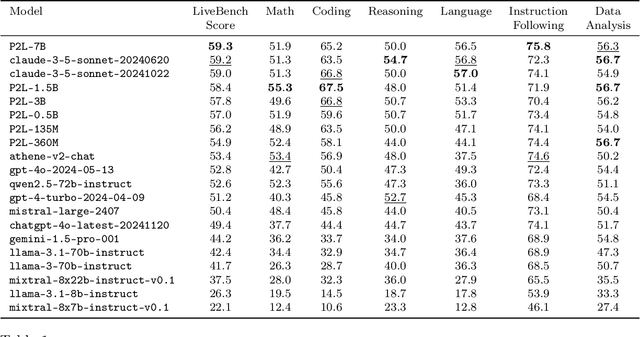
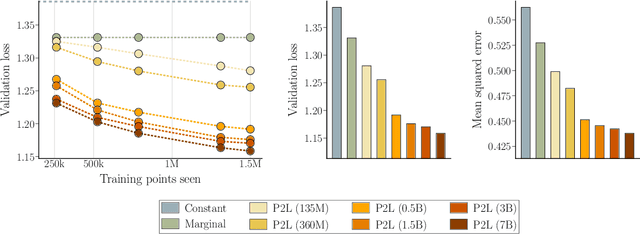
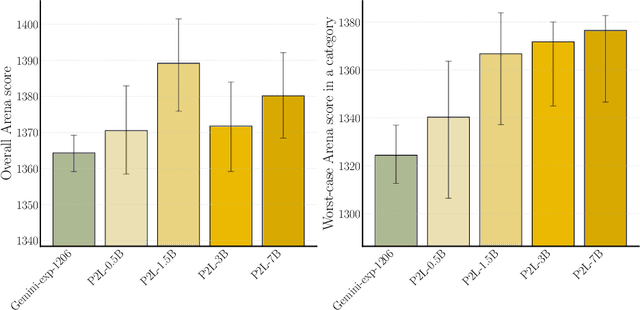
Large language model (LLM) evaluations typically rely on aggregated metrics like accuracy or human preference, averaging across users and prompts. This averaging obscures user- and prompt-specific variations in model performance. To address this, we propose Prompt-to-Leaderboard (P2L), a method that produces leaderboards specific to a prompt. The core idea is to train an LLM taking natural language prompts as input to output a vector of Bradley-Terry coefficients which are then used to predict the human preference vote. The resulting prompt-dependent leaderboards allow for unsupervised task-specific evaluation, optimal routing of queries to models, personalization, and automated evaluation of model strengths and weaknesses. Data from Chatbot Arena suggest that P2L better captures the nuanced landscape of language model performance than the averaged leaderboard. Furthermore, our findings suggest that P2L's ability to produce prompt-specific evaluations follows a power law scaling similar to that observed in LLMs themselves. In January 2025, the router we trained based on this methodology achieved the \#1 spot in the Chatbot Arena leaderboard. Our code is available at this GitHub link: https://github.com/lmarena/p2l.