 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch Before You Answer: Learning from Visually Grounded Post-Training
Apr 06, 2026It is critical for vision-language models (VLMs) to comprehensively understand visual, temporal, and textual cues. However, despite rapid progress in multimodal modeling, video understanding performance still lags behind text-based reasoning. In this work, we find that progress is even worse than previously assumed: commonly reported long video understanding benchmarks contain 40-60% of questions that can be answered using text cues alone. Furthermore, we find that these issues are also pervasive in widely used post-training datasets, potentially undercutting the ability of post-training to improve VLM video understanding performance. Guided by this observation, we introduce VidGround as a simple yet effective solution: using only the actual visually grounded questions without any linguistic biases for post-training. When used in tandem with RL-based post-training algorithms, this simple technique improves performance by up to 6.2 points relative to using the full dataset, while using only 69.1% of the original post-training data. Moreover, we show that data curation with a simple post-training algorithm outperforms several more complex post-training techniques, highlighting that data quality is a major bottleneck for improving video understanding in VLMs. These results underscore the importance of curating post-training data and evaluation benchmarks that truly require visual grounding to advance the development of more capable VLMs. Project page: http://vidground.etuagi.com.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Scaling Laws of Machine Learning for Optimal Power Flow
Jan 06, 2026Optimal power flow (OPF) is one of the fundamental tasks for power system operations. While machine learning (ML) approaches such as deep neural networks (DNNs) have been widely studied to enhance OPF solution speed and performance, their practical deployment faces two critical scaling questions: What is the minimum training data volume required for reliable results? How should ML models' complexity balance accuracy with real-time computational limits? Existing studies evaluate discrete scenarios without quantifying these scaling relationships, leading to trial-and-error-based ML development in real-world applications. This work presents the first systematic scaling study for ML-based OPF across two dimensions: data scale (0.1K-40K training samples) and compute scale (multiple NN architectures with varying FLOPs). Our results reveal consistent power-law relationships on both DNNs and physics-informed NNs (PINNs) between each resource dimension and three core performance metrics: prediction error (MAE), constraint violations and speed. We find that for ACOPF, the accuracy metric scales with dataset size and training compute. These scaling laws enable predictable and principled ML pipeline design for OPF. We further identify the divergence between prediction accuracy and constraint feasibility and characterize the compute-optimal frontier. This work provides quantitative guidance for ML-OPF design and deployments.
HierDAMap: Towards Universal Domain Adaptive BEV Mapping via Hierarchical Perspective Priors
Mar 10, 2025The exploration of Bird's-Eye View (BEV) mapping technology has driven significant innovation in visual perception technology for autonomous driving. BEV mapping models need to be applied to the unlabeled real world, making the study of unsupervised domain adaptation models an essential path. However, research on unsupervised domain adaptation for BEV mapping remains limited and cannot perfectly accommodate all BEV mapping tasks. To address this gap, this paper proposes HierDAMap, a universal and holistic BEV domain adaptation framework with hierarchical perspective priors. Unlike existing research that solely focuses on image-level learning using prior knowledge, this paper explores the guiding role of perspective prior knowledge across three distinct levels: global, sparse, and instance levels. With these priors, HierDA consists of three essential components, including Semantic-Guided Pseudo Supervision (SGPS), Dynamic-Aware Coherence Learning (DACL), and Cross-Domain Frustum Mixing (CDFM). SGPS constrains the cross-domain consistency of perspective feature distribution through pseudo labels generated by vision foundation models in 2D space. To mitigate feature distribution discrepancies caused by spatial variations, DACL employs uncertainty-aware predicted depth as an intermediary to derive dynamic BEV labels from perspective pseudo-labels, thereby constraining the coarse BEV features derived from corresponding perspective features. CDFM, on the other hand, leverages perspective masks of view frustum to mix multi-view perspective images from both domains, which guides cross-domain view transformation and encoding learning through mixed BEV labels. The proposed method is verified on multiple BEV mapping tasks, such as BEV semantic segmentation, high-definition semantic, and vectorized mapping. The source code will be made publicly available at https://github.com/lynn-yu/HierDAMap.
CovNet: Covariance Information-Assisted CSI Feedback for FDD Massive MIMO Systems
Dec 17, 2024



In this paper, we propose a novel covariance information-assisted channel state information (CSI) feedback scheme for frequency-division duplex (FDD) massive multi-input multi-output (MIMO) systems. Unlike most existing CSI feedback schemes, which rely on instantaneous CSI only, the proposed CovNet leverages CSI covariance information to achieve high-performance CSI reconstruction, primarily consisting of convolutional neural network (CNN) and Transformer architecture. To efficiently utilize covariance information, we propose a covariance information processing procedure and sophisticatedly design the covariance information processing network (CIPN) to further process it. Moreover, the feed-forward network (FFN) in CovNet is designed to jointly leverage the 2D characteristics of the CSI matrix in the angle and delay domains. Simulation results demonstrate that the proposed network effectively leverages covariance information and outperforms the state-of-the-art (SOTA) scheme across the full compression ratio (CR) range.
Is Locational Marginal Price All You Need for Locational Marginal Emission?
Nov 18, 2024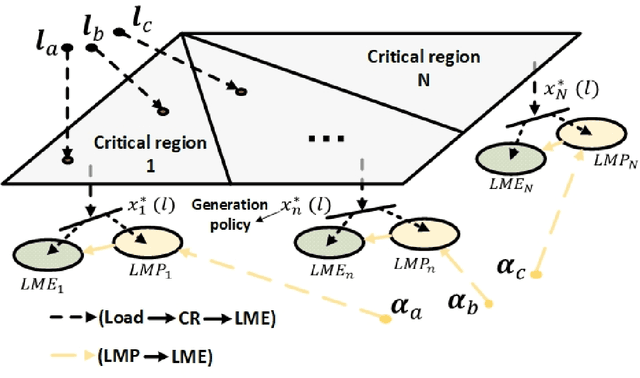
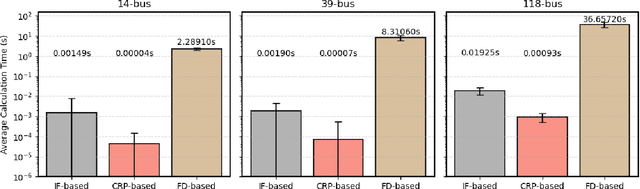
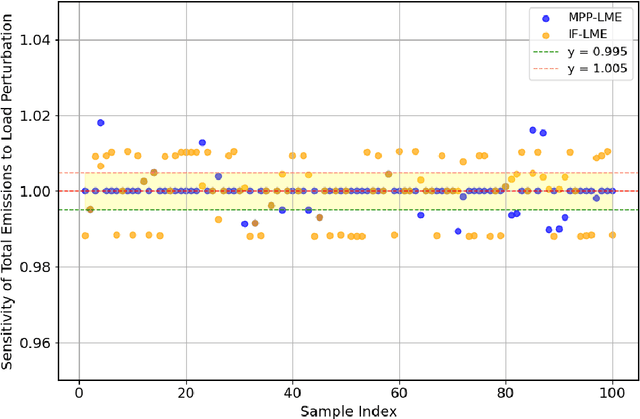
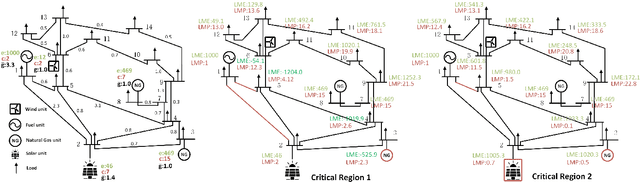
Growing concerns over climate change call for improved techniques for estimating and quantifying the greenhouse gas emissions associated with electricity generation and transmission. Among the emission metrics designated for power grids, locational marginal emission (LME) can provide system operators and electricity market participants with valuable information on the emissions associated with electricity usage at various locations in the power network. In this paper, by investigating the operating patterns and physical interpretations of marginal emissions and costs in the security-constrained economic dispatch (SCED) problem, we identify and draw the exact connection between locational marginal price (LMP) and LME. Such interpretation helps instantly derive LME given nodal demand vectors or LMP, and also reveals the interplay between network congestion and nodal emission pattern. Our proposed approach helps reduce the computation time of LME by an order of magnitude compared to analytical approaches, while it can also serve as a plug-and-play module accompanied by an off-the-shelf market clearing and LMP calculation process.
Guiding Through Complexity: What Makes Good Supervision for Hard Reasoning Tasks?
Oct 27, 2024

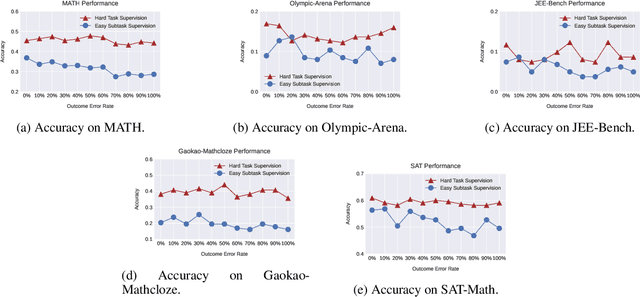
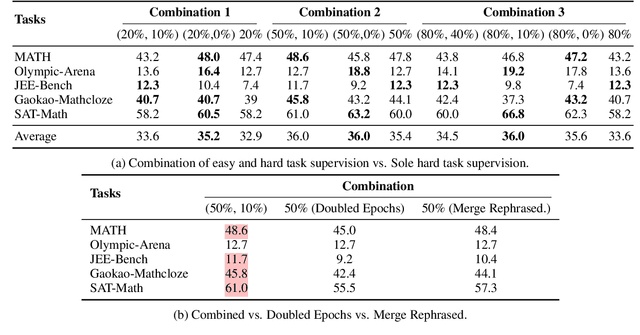
How can "weak teacher models" such as average human annotators or existing AI systems, effectively supervise LLMs to improve performance on hard reasoning tasks, especially those that challenge and requires expertise or daily practice from the teacher models? In this paper, we seek for empirical answers to this question by investigating various data-driven strategies that offer supervision data at different quality levels upon tasks of varying complexity. Two intuitive strategies emerge for teacher models to provide supervision during alignment training: 1) using lower-quality supervision from complete tasks that match the difficulty of the target reasoning tasks, and 2) leveraging higher-quality supervision from easier subtasks that are less challenging. Interestingly, we find that even when the outcome error rate for hard task supervision is high (e.g., 90\%), training on such data can outperform perfectly correct supervision on easier subtasks on multiple hard math benchmarks. We further identify a more critical factor influencing training performance: step-wise error rates, which indicate the severity of errors in solutions. Specifically, training on hard task supervision with the same outcome error rates but disparate step-wise error rates can lead to a 30\% accuracy gap on MATH benchmark. Our results also reveal that supplementing hard task supervision with the corresponding subtask supervision can yield notable performance improvements than simply combining rephrased hard full task supervision, suggesting new avenues for data augmentation. Data and code are released at \url{https://github.com/hexuan21/Weak-to-Strong}.
MEGA-Bench: Scaling Multimodal Evaluation to over 500 Real-World Tasks
Oct 14, 2024



We present MEGA-Bench, an evaluation suite that scales multimodal evaluation to over 500 real-world tasks, to address the highly heterogeneous daily use cases of end users. Our objective is to optimize for a set of high-quality data samples that cover a highly diverse and rich set of multimodal tasks, while enabling cost-effective and accurate model evaluation. In particular, we collected 505 realistic tasks encompassing over 8,000 samples from 16 expert annotators to extensively cover the multimodal task space. Instead of unifying these problems into standard multi-choice questions (like MMMU, MMBench, and MMT-Bench), we embrace a wide range of output formats like numbers, phrases, code, \LaTeX, coordinates, JSON, free-form, etc. To accommodate these formats, we developed over 40 metrics to evaluate these tasks. Unlike existing benchmarks, MEGA-Bench offers a fine-grained capability report across multiple dimensions (e.g., application, input type, output format, skill), allowing users to interact with and visualize model capabilities in depth. We evaluate a wide variety of frontier vision-language models on MEGA-Bench to understand their capabilities across these dimensions.
VideoScore: Building Automatic Metrics to Simulate Fine-grained Human Feedback for Video Generation
Jun 24, 2024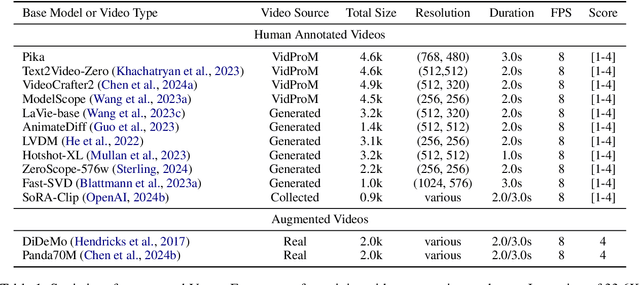

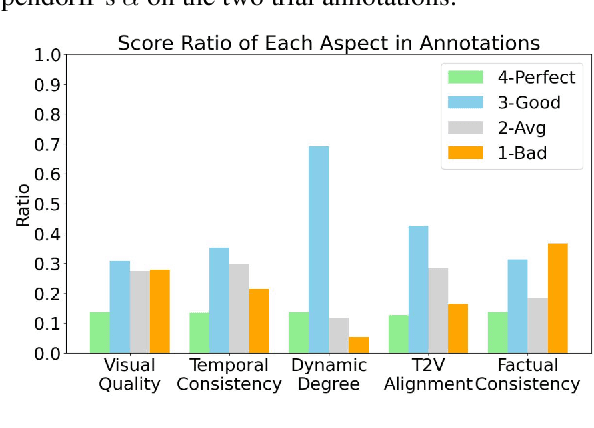

The recent years have witnessed great advances in video generation. However, the development of automatic video metrics is lagging significantly behind. None of the existing metric is able to provide reliable scores over generated videos. The main barrier is the lack of large-scale human-annotated dataset. In this paper, we release VideoFeedback, the first large-scale dataset containing human-provided multi-aspect score over 37.6K synthesized videos from 11 existing video generative models. We train VideoScore (initialized from Mantis) based on VideoFeedback to enable automatic video quality assessment. Experiments show that the Spearman correlation between VideoScore and humans can reach 77.1 on VideoFeedback-test, beating the prior best metrics by about 50 points. Further result on other held-out EvalCrafter, GenAI-Bench, and VBench show that VideoScore has consistently much higher correlation with human judges than other metrics. Due to these results, we believe VideoScore can serve as a great proxy for human raters to (1) rate different video models to track progress (2) simulate fine-grained human feedback in Reinforcement Learning with Human Feedback (RLHF) to improve current video generation models.
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Jun 04, 2024



In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as models continue to improve, their performance on these benchmarks has begun to plateau, making it increasingly difficult to discern differences in model capabilities. This paper introduces MMLU-Pro, an enhanced dataset designed to extend the mostly knowledge-driven MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. Additionally, MMLU-Pro eliminates the trivial and noisy questions in MMLU. Our experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16% to 33% compared to MMLU but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4-5% in MMLU to just 2% in MMLU-Pro. Additionally, we found that models utilizing Chain of Thought (CoT) reasoning achieved better performance on MMLU-Pro compared to direct answering, which is in stark contrast to the findings on the original MMLU, indicating that MMLU-Pro includes more complex reasoning questions. Our assessments confirm that MMLU-Pro is a more discriminative benchmark to better track progress in the field.