 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnseen Cost of Space Computing: Quantifying LEO Battery Aging via Physics-Driven Modeling
Mar 04, 2026Low Earth Orbit (LEO) satellite constellations in the 6G era are evolving into intelligent in-orbit computational platforms, forming Space Computing Power Networks (SCPNs) to deliver global-scale computing services. However, the intensive computation within SCPN incurs a significant ``unseen cost'': the frequent charge-discharge cycles accelerate the physical degradation of satellites' life-limiting and high-cost batteries, thereby threatening the long-term operational viability of such a system. Existing approaches, often relying on indirect metrics like Depth of Discharge (DoD) and neglecting the complex, nonlinear degradation process of battery aging, fail to accurately quantify this cost. To address this, we introduce a high-fidelity, physics-driven model that quantitatively links computational workload parameters to the nonlinear battery degradation. Building on this model, we formulate a degradation-aware scheduling problem and analyze heuristic policies across different energy regimes. Simulations reveal that the optimal strategy should be adaptive: in solar-rich conditions, a myopic policy maximizing instantaneous solar utilization is superior, whereas under energy scarcity, a reactive policy leveraging real-time battery state significantly extends lifetime.
Service Function Chain Routing in LEO Networks Using Shortest-Path Delay Statistical Stability
Mar 04, 2026Low Earth orbit (LEO) satellite constellations have become a critical enabler for global coverage, utilizing numerous satellites orbiting Earth at high speeds. By decomposing complex network services into lightweight service functions, network function virtualization (NFV) transforms global network services into diverse service function chains (SFCs), coordinated by resource-constrained LEOs. However, the dynamic topology of satellite networks, marked by highly variable inter-satellite link delays, poses significant challenges for designing efficient routing strategies that ensure reliable and low-latency communication. Many existing routing methods suffer from poor scalability and degraded performance, limiting their practical implementation. To address these challenges, this paper proposes a novel SFC routing approach that leverages the statistical properties of network link states to mitigate instability caused by instantaneous modeling in dynamic satellite networks. Through comprehensive simulations on end-to-end shortest-path propagation delays in LEO networks, we identify and validate the statistical stability of multi-hop routes. Building on this insight, we introduce the Stability-Aware Multi-Stage Graph Routing (SA-MSGR) algorithm, which incorporates pre-computed average delays into a multi-stage graph optimization framework. Extensive simulations demonstrate the superior performance of SA-MSGR, achieving significantly lower and more predictable end-to-end SFC delays compared to representative baseline strategies.
DocMEdit: Towards Document-Level Model Editing
May 26, 2025Model editing aims to correct errors and outdated knowledge in the Large language models (LLMs) with minimal cost. Prior research has proposed a variety of datasets to assess the effectiveness of these model editing methods. However, most existing datasets only require models to output short phrases or sentences, overlooks the widespread existence of document-level tasks in the real world, raising doubts about their practical usability. Aimed at addressing this limitation and promoting the application of model editing in real-world scenarios, we propose the task of document-level model editing. To tackle such challenges and enhance model capabilities in practical settings, we introduce \benchmarkname, a dataset focused on document-level model editing, characterized by document-level inputs and outputs, extrapolative, and multiple facts within a single edit. We propose a series of evaluation metrics and experiments. The results show that the difficulties in document-level model editing pose challenges for existing model editing methods.
EDBench: Large-Scale Electron Density Data for Molecular Modeling
May 14, 2025



Existing molecular machine learning force fields (MLFFs) generally focus on the learning of atoms, molecules, and simple quantum chemical properties (such as energy and force), but ignore the importance of electron density (ED) $\rho(r)$ in accurately understanding molecular force fields (MFFs). ED describes the probability of finding electrons at specific locations around atoms or molecules, which uniquely determines all ground state properties (such as energy, molecular structure, etc.) of interactive multi-particle systems according to the Hohenberg-Kohn theorem. However, the calculation of ED relies on the time-consuming first-principles density functional theory (DFT) which leads to the lack of large-scale ED data and limits its application in MLFFs. In this paper, we introduce EDBench, a large-scale, high-quality dataset of ED designed to advance learning-based research at the electronic scale. Built upon the PCQM4Mv2, EDBench provides accurate ED data, covering 3.3 million molecules. To comprehensively evaluate the ability of models to understand and utilize electronic information, we design a suite of ED-centric benchmark tasks spanning prediction, retrieval, and generation. Our evaluation on several state-of-the-art methods demonstrates that learning from EDBench is not only feasible but also achieves high accuracy. Moreover, we show that learning-based method can efficiently calculate ED with comparable precision while significantly reducing the computational cost relative to traditional DFT calculations. All data and benchmarks from EDBench will be freely available, laying a robust foundation for ED-driven drug discovery and materials science.
High-Throughput LLM inference on Heterogeneous Clusters
Apr 18, 2025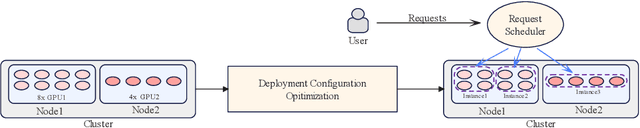
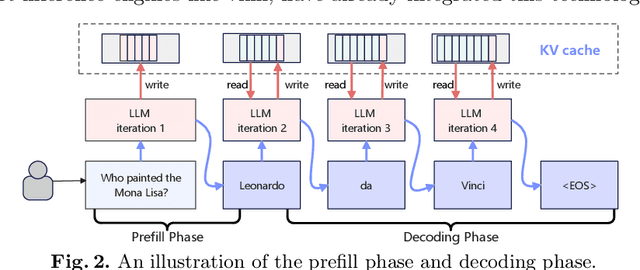


Nowadays, many companies possess various types of AI accelerators, forming heterogeneous clusters. Efficiently leveraging these clusters for high-throughput large language model (LLM) inference services can significantly reduce costs and expedite task processing. However, LLM inference on heterogeneous clusters presents two main challenges. Firstly, different deployment configurations can result in vastly different performance. The number of possible configurations is large, and evaluating the effectiveness of a specific setup is complex. Thus, finding an optimal configuration is not an easy task. Secondly, LLM inference instances within a heterogeneous cluster possess varying processing capacities, leading to different processing speeds for handling inference requests. Evaluating these capacities and designing a request scheduling algorithm that fully maximizes the potential of each instance is challenging. In this paper, we propose a high-throughput inference service system on heterogeneous clusters. First, the deployment configuration is optimized by modeling the resource amount and expected throughput and using the exhaustive search method. Second, a novel mechanism is proposed to schedule requests among instances, which fully considers the different processing capabilities of various instances. Extensive experiments show that the proposed scheduler improves throughput by 122.5% and 33.6% on two heterogeneous clusters, respectively.
FAME: Towards Factual Multi-Task Model Editing
Oct 07, 2024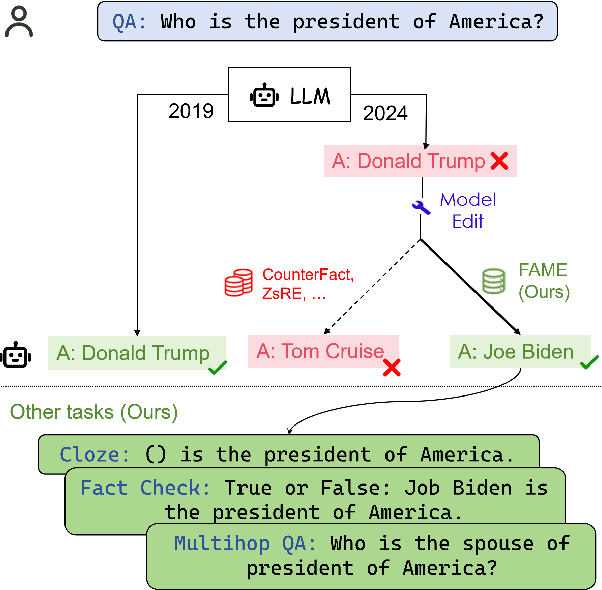
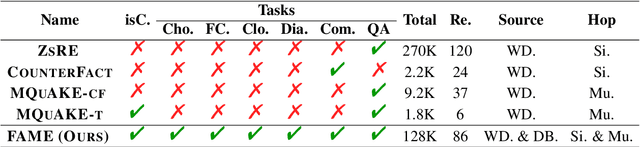
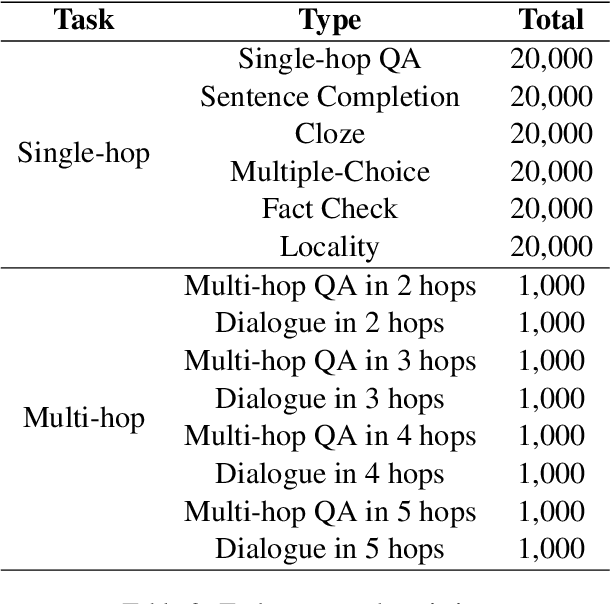
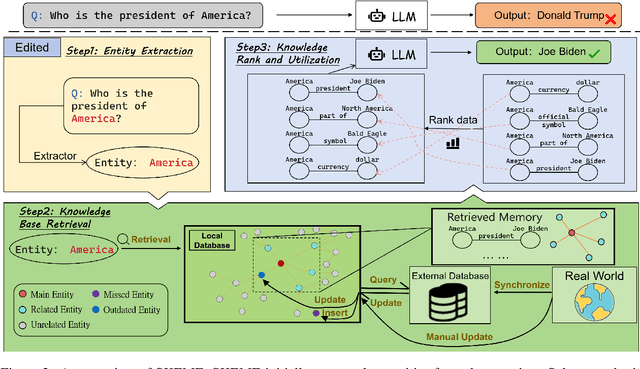
Large language models (LLMs) embed extensive knowledge and utilize it to perform exceptionally well across various tasks. Nevertheless, outdated knowledge or factual errors within LLMs can lead to misleading or incorrect responses, causing significant issues in practical applications. To rectify the fatal flaw without the necessity for costly model retraining, various model editing approaches have been proposed to correct inaccurate knowledge within LLMs in a cost-efficient way. To evaluate these model editing methods, previous work introduced a series of datasets. However, most of the previous datasets only contain fabricated data in a single format, which diverges from real-world model editing scenarios, raising doubts about their usability in practice. To facilitate the application of model editing in real-world scenarios, we propose the challenge of practicality. To resolve such challenges and effectively enhance the capabilities of LLMs, we present FAME, an factual, comprehensive, and multi-task dataset, which is designed to enhance the practicality of model editing. We then propose SKEME, a model editing method that uses a novel caching mechanism to ensure synchronization with the real world. The experiments demonstrate that SKEME performs excellently across various tasks and scenarios, confirming its practicality.
LocMoE+: Enhanced Router with Token Feature Awareness for Efficient LLM Pre-Training
May 24, 2024Mixture-of-Experts (MoE) architectures have recently gained increasing popularity within the domain of large language models (LLMs) due to their ability to significantly reduce training and inference overhead. However, MoE architectures face challenges, such as significant disparities in the number of tokens assigned to each expert and a tendency toward homogenization among experts, which adversely affects the model's semantic generation capabilities. In this paper, we introduce LocMoE+, a refined version of the low-overhead LocMoE, incorporating the following enhancements: (1) Quantification and definition of the affinity between experts and tokens. (2) Implementation of a global-level adaptive routing strategy to rearrange tokens based on their affinity scores. (3) Reestimation of the lower bound for expert capacity, which has been shown to progressively decrease as the token feature distribution evolves. Experimental results demonstrate that, without compromising model convergence or efficacy, the number of tokens each expert processes can be reduced by over 60%. Combined with communication optimizations, this leads to an average improvement in training efficiency ranging from 5.4% to 46.6%. After fine-tuning, LocMoE+ exhibits a performance improvement of 9.7% to 14.1% across the GDAD, C-Eval, and TeleQnA datasets.
EFSA: Towards Event-Level Financial Sentiment Analysis
Apr 08, 2024In this paper, we extend financial sentiment analysis~(FSA) to event-level since events usually serve as the subject of the sentiment in financial text. Though extracting events from the financial text may be conducive to accurate sentiment predictions, it has specialized challenges due to the lengthy and discontinuity of events in a financial text. To this end, we reconceptualize the event extraction as a classification task by designing a categorization comprising coarse-grained and fine-grained event categories. Under this setting, we formulate the \textbf{E}vent-Level \textbf{F}inancial \textbf{S}entiment \textbf{A}nalysis~(\textbf{EFSA} for short) task that outputs quintuples consisting of (company, industry, coarse-grained event, fine-grained event, sentiment) from financial text. A large-scale Chinese dataset containing $12,160$ news articles and $13,725$ quintuples is publicized as a brand new testbed for our task. A four-hop Chain-of-Thought LLM-based approach is devised for this task. Systematically investigations are conducted on our dataset, and the empirical results demonstrate the benchmarking scores of existing methods and our proposed method can reach the current state-of-the-art. Our dataset and framework implementation are available at https://anonymous.4open.science/r/EFSA-645E
Transform then Explore: a Simple and Effective Technique for Exploratory Combinatorial Optimization with Reinforcement Learning
Apr 06, 2024Many complex problems encountered in both production and daily life can be conceptualized as combinatorial optimization problems (COPs) over graphs. Recent years, reinforcement learning (RL) based models have emerged as a promising direction, which treat the COPs solving as a heuristic learning problem. However, current finite-horizon-MDP based RL models have inherent limitations. They are not allowed to explore adquately for improving solutions at test time, which may be necessary given the complexity of NP-hard optimization tasks. Some recent attempts solve this issue by focusing on reward design and state feature engineering, which are tedious and ad-hoc. In this work, we instead propose a much simpler but more effective technique, named gauge transformation (GT). The technique is originated from physics, but is very effective in enabling RL agents to explore to continuously improve the solutions during test. Morever, GT is very simple, which can be implemented with less than 10 lines of Python codes, and can be applied to a vast majority of RL models. Experimentally, we show that traditional RL models with GT technique produce the state-of-the-art performances on the MaxCut problem. Furthermore, since GT is independent of any RL models, it can be seamlessly integrated into various RL frameworks, paving the way of these models for more effective explorations in the solving of general COPs.
Satellite Federated Edge Learning: Architecture Design and Convergence Analysis
Apr 02, 2024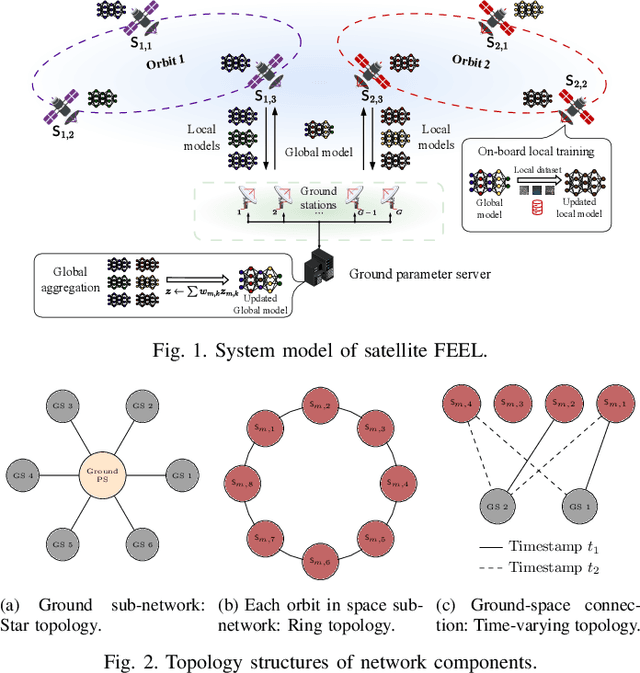
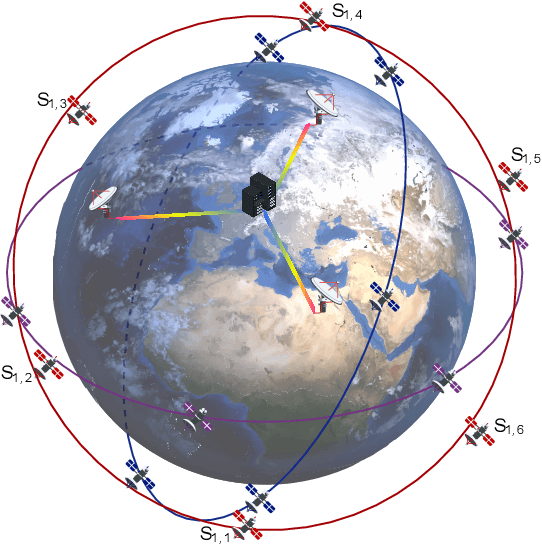
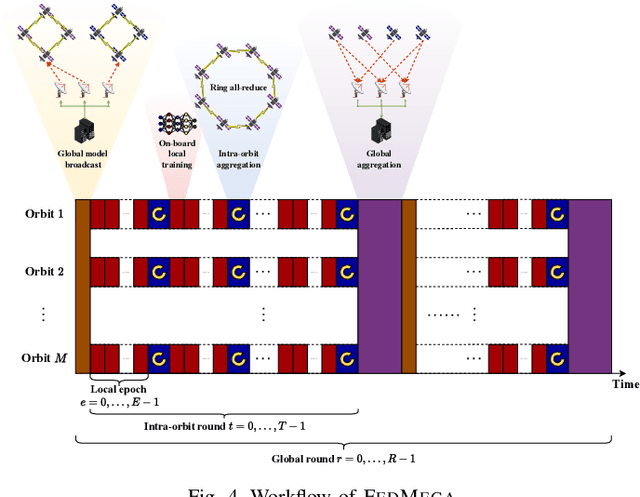
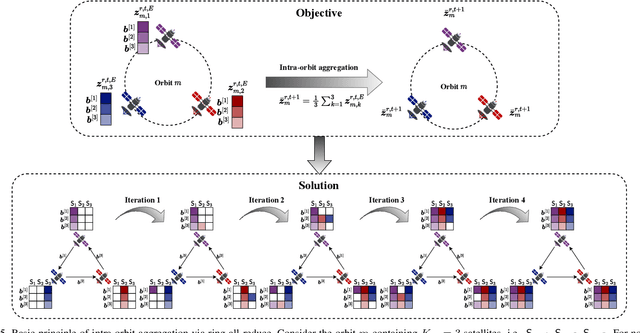
The proliferation of low-earth-orbit (LEO) satellite networks leads to the generation of vast volumes of remote sensing data which is traditionally transferred to the ground server for centralized processing, raising privacy and bandwidth concerns. Federated edge learning (FEEL), as a distributed machine learning approach, has the potential to address these challenges by sharing only model parameters instead of raw data. Although promising, the dynamics of LEO networks, characterized by the high mobility of satellites and short ground-to-satellite link (GSL) duration, pose unique challenges for FEEL. Notably, frequent model transmission between the satellites and ground incurs prolonged waiting time and large transmission latency. This paper introduces a novel FEEL algorithm, named FEDMEGA, tailored to LEO mega-constellation networks. By integrating inter-satellite links (ISL) for intra-orbit model aggregation, the proposed algorithm significantly reduces the usage of low data rate and intermittent GSL. Our proposed method includes a ring all-reduce based intra-orbit aggregation mechanism, coupled with a network flow-based transmission scheme for global model aggregation, which enhances transmission efficiency. Theoretical convergence analysis is provided to characterize the algorithm performance. Extensive simulations show that our FEDMEGA algorithm outperforms existing satellite FEEL algorithms, exhibiting an approximate 30% improvement in convergence rate.