 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchicalKV: A GPU Hash Table with Cache Semantics for Continuous Online Embedding Storage
Mar 17, 2026Traditional GPU hash tables preserve every inserted key -- a dictionary assumption that wastes scarce High Bandwidth Memory (HBM) when embedding tables routinely exceed single-GPU capacity. We challenge this assumption with cache semantics, where policy-driven eviction is a first-class operation. We introduce HierarchicalKV (HKV), the first general-purpose GPU hash table library whose normal full-capacity operating contract is cache-semantic: each full-bucket upsert (update-or-insert) is resolved in place by eviction or admission rejection rather than by rehashing or capacity-induced failure. HKV co-designs four core mechanisms -- cache-line-aligned buckets, in-line score-driven upsert, score-based dynamic dual-bucket selection, and triple-group concurrency -- and uses tiered key-value separation as a scaling enabler beyond HBM. On an NVIDIA H100 NVL GPU, HKV achieves up to 3.9 billion key-value pairs per second (B-KV/s) find throughput, stable across load factors 0.50-1.00 (<5% variation), and delivers 1.4x higher find throughput than WarpCore (the strongest dictionary-semantic GPU baseline at lambda=0.50) and up to 2.6-9.4x over indirection-based GPU baselines. Since its open-source release in October 2022, HKV has been integrated into multiple open-source recommendation frameworks.
Echo: Towards Advanced Audio Comprehension via Audio-Interleaved Reasoning
Feb 12, 2026The maturation of Large Audio Language Models (LALMs) has raised growing expectations for them to comprehend complex audio much like humans. Current efforts primarily replicate text-based reasoning by contextualizing audio content through a one-time encoding, which introduces a critical information bottleneck. Drawing inspiration from human cognition, we propose audio-interleaved reasoning to break through this bottleneck. It treats audio as an active reasoning component, enabling sustained audio engagement and perception-grounded analysis. To instantiate it, we introduce a two-stage training framework, first teaching LALMs to localize salient audio segments through supervised fine-tuning, and then incentivizing proficient re-listening via reinforcement learning. In parallel, a structured data generation pipeline is developed to produce high-quality training data. Consequently, we present Echo, a LALM capable of dynamically re-listening to audio in demand during reasoning. On audio comprehension benchmarks, Echo achieves overall superiority in both challenging expert-level and general-purpose tasks. Comprehensive analysis further confirms the efficiency and generalizability of audio-interleaved reasoning, establishing it as a promising direction for advancing audio comprehension. Project page: https://github.com/wdqqdw/Echo.
HomeBench: Evaluating LLMs in Smart Homes with Valid and Invalid Instructions Across Single and Multiple Devices
May 26, 2025Large language models (LLMs) have the potential to revolutionize smart home assistants by enhancing their ability to accurately understand user needs and respond appropriately, which is extremely beneficial for building a smarter home environment. While recent studies have explored integrating LLMs into smart home systems, they primarily focus on handling straightforward, valid single-device operation instructions. However, real-world scenarios are far more complex and often involve users issuing invalid instructions or controlling multiple devices simultaneously. These have two main challenges: LLMs must accurately identify and rectify errors in user instructions and execute multiple user instructions perfectly. To address these challenges and advance the development of LLM-based smart home assistants, we introduce HomeBench, the first smart home dataset with valid and invalid instructions across single and multiple devices in this paper. We have experimental results on 13 distinct LLMs; e.g., GPT-4o achieves only a 0.0% success rate in the scenario of invalid multi-device instructions, revealing that the existing state-of-the-art LLMs still cannot perform well in this situation even with the help of in-context learning, retrieval-augmented generation, and fine-tuning. Our code and dataset are publicly available at https://github.com/BITHLP/HomeBench.
ReFF: Reinforcing Format Faithfulness in Language Models across Varied Tasks
Dec 12, 2024Following formatting instructions to generate well-structured content is a fundamental yet often unmet capability for large language models (LLMs). To study this capability, which we refer to as format faithfulness, we present FormatBench, a comprehensive format-related benchmark. Compared to previous format-related benchmarks, FormatBench involves a greater variety of tasks in terms of application scenes (traditional NLP tasks, creative works, autonomous agency tasks), human-LLM interaction styles (single-turn instruction, multi-turn chat), and format types (inclusion, wrapping, length, coding). Moreover, each task in FormatBench is attached with a format checker program. Extensive experiments on the benchmark reveal that state-of-the-art open- and closed-source LLMs still suffer from severe deficiency in format faithfulness. By virtue of the decidable nature of formats, we propose to Reinforce Format Faithfulness (ReFF) to help LLMs generate formatted output as instructed without compromising general quality. Without any annotated data, ReFF can substantially improve the format faithfulness rate (e.g., from 21.6% in original LLaMA3 to 95.0% on caption segmentation task), while keep the general quality comparable (e.g., from 47.3 to 46.4 in F1 scores). Combined with labeled training data, ReFF can simultaneously improve both format faithfulness (e.g., from 21.6% in original LLaMA3 to 75.5%) and general quality (e.g., from 47.3 to 61.6 in F1 scores). We further offer an interpretability analysis to explain how ReFF improves both format faithfulness and general quality.
Optimizing Chain-of-Thought Reasoning: Tackling Arranging Bottleneck via Plan Augmentation
Oct 22, 2024
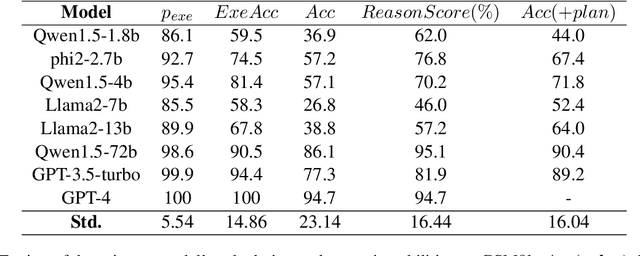
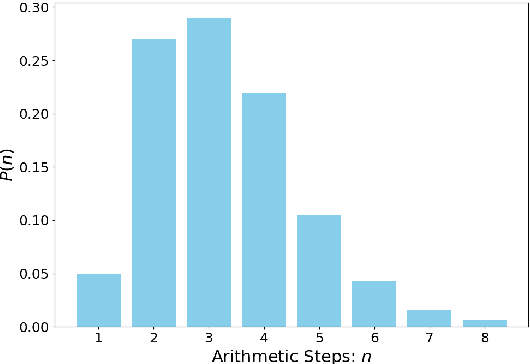
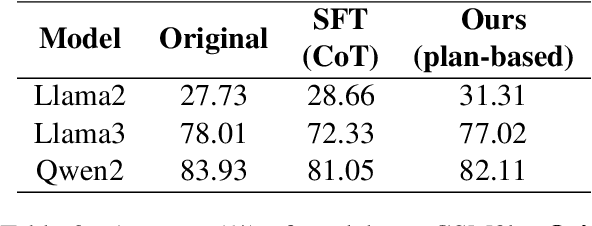
Multi-step reasoning ability of large language models is crucial in tasks such as math and tool utilization. Current researches predominantly focus on enhancing model performance in these multi-step reasoning tasks through fine-tuning with Chain-of-Thought (CoT) steps, yet these methods tend to be heuristic, without exploring nor resolving the bottleneck. In this study, we subdivide CoT reasoning into two parts: arranging and executing, and identify that the bottleneck of models mainly lies in arranging rather than executing. Based on this finding, we propose a plan-based training and reasoning method that guides models to generate arranging steps through abstract plans. We experiment on both math (GSM8k) and tool utilization (ToolBench) benchmarks. Results show that compared to fine-tuning directly with CoT data, our approach achieves a better performance on alleviating arranging bottleneck, particularly excelling in long-distance reasoning generalization.
FAME: Towards Factual Multi-Task Model Editing
Oct 07, 2024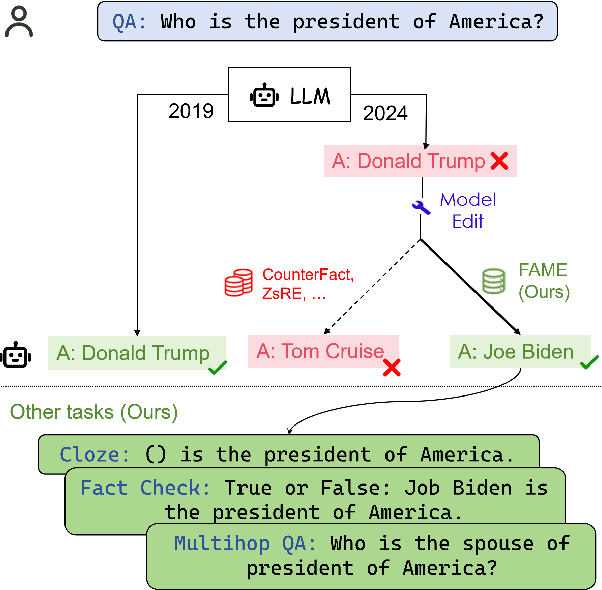
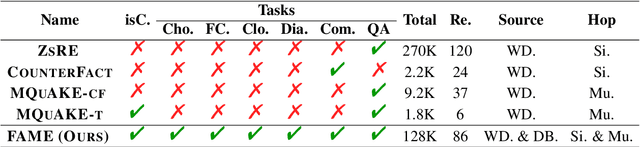
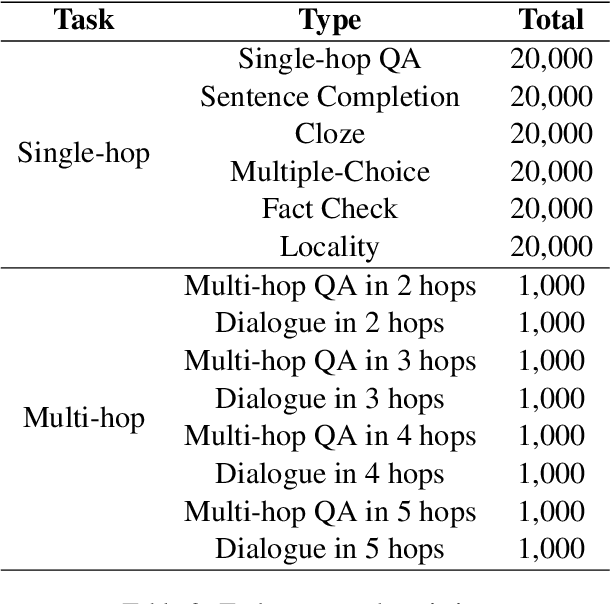
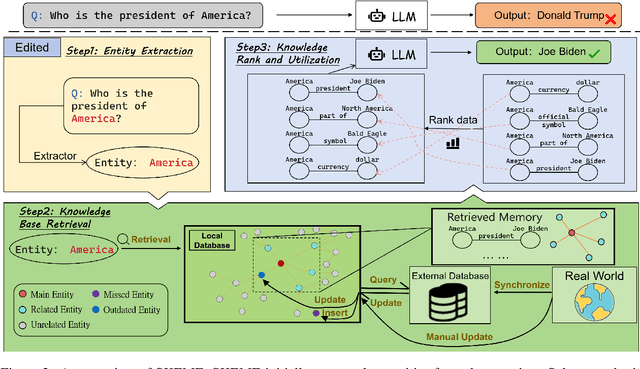
Large language models (LLMs) embed extensive knowledge and utilize it to perform exceptionally well across various tasks. Nevertheless, outdated knowledge or factual errors within LLMs can lead to misleading or incorrect responses, causing significant issues in practical applications. To rectify the fatal flaw without the necessity for costly model retraining, various model editing approaches have been proposed to correct inaccurate knowledge within LLMs in a cost-efficient way. To evaluate these model editing methods, previous work introduced a series of datasets. However, most of the previous datasets only contain fabricated data in a single format, which diverges from real-world model editing scenarios, raising doubts about their usability in practice. To facilitate the application of model editing in real-world scenarios, we propose the challenge of practicality. To resolve such challenges and effectively enhance the capabilities of LLMs, we present FAME, an factual, comprehensive, and multi-task dataset, which is designed to enhance the practicality of model editing. We then propose SKEME, a model editing method that uses a novel caching mechanism to ensure synchronization with the real world. The experiments demonstrate that SKEME performs excellently across various tasks and scenarios, confirming its practicality.
Deterministic Reversible Data Augmentation for Neural Machine Translation
Jun 04, 2024Data augmentation is an effective way to diversify corpora in machine translation, but previous methods may introduce semantic inconsistency between original and augmented data because of irreversible operations and random subword sampling procedures. To generate both symbolically diverse and semantically consistent augmentation data, we propose Deterministic Reversible Data Augmentation (DRDA), a simple but effective data augmentation method for neural machine translation. DRDA adopts deterministic segmentations and reversible operations to generate multi-granularity subword representations and pulls them closer together with multi-view techniques. With no extra corpora or model changes required, DRDA outperforms strong baselines on several translation tasks with a clear margin (up to 4.3 BLEU gain over Transformer) and exhibits good robustness in noisy, low-resource, and cross-domain datasets.