 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGI-Bench: A Panoramic Benchmark Revealing the Knowledge-Experience Dissociation of Multimodal Large Language Models in Gastrointestinal Endoscopy Against Clinical Standards
Jan 13, 2026Multimodal Large Language Models (MLLMs) show promise in gastroenterology, yet their performance against comprehensive clinical workflows and human benchmarks remains unverified. To systematically evaluate state-of-the-art MLLMs across a panoramic gastrointestinal endoscopy workflow and determine their clinical utility compared with human endoscopists. We constructed GI-Bench, a benchmark encompassing 20 fine-grained lesion categories. Twelve MLLMs were evaluated across a five-stage clinical workflow: anatomical localization, lesion identification, diagnosis, findings description, and management. Model performance was benchmarked against three junior endoscopists and three residency trainees using Macro-F1, mean Intersection-over-Union (mIoU), and multi-dimensional Likert scale. Gemini-3-Pro achieved state-of-the-art performance. In diagnostic reasoning, top-tier models (Macro-F1 0.641) outperformed trainees (0.492) and rivaled junior endoscopists (0.727; p>0.05). However, a critical "spatial grounding bottleneck" persisted; human lesion localization (mIoU >0.506) significantly outperformed the best model (0.345; p<0.05). Furthermore, qualitative analysis revealed a "fluency-accuracy paradox": models generated reports with superior linguistic readability compared with humans (p<0.05) but exhibited significantly lower factual correctness (p<0.05) due to "over-interpretation" and hallucination of visual features.GI-Bench maintains a dynamic leaderboard that tracks the evolving performance of MLLMs in clinical endoscopy. The current rankings and benchmark results are available at https://roterdl.github.io/GIBench/.
Dynamic-DINO: Fine-Grained Mixture of Experts Tuning for Real-time Open-Vocabulary Object Detection
Jul 23, 2025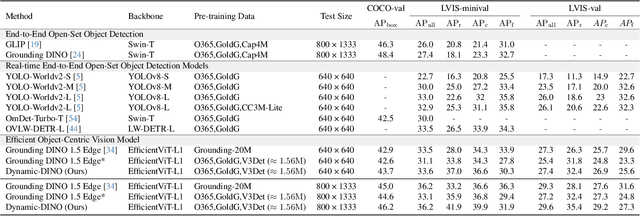
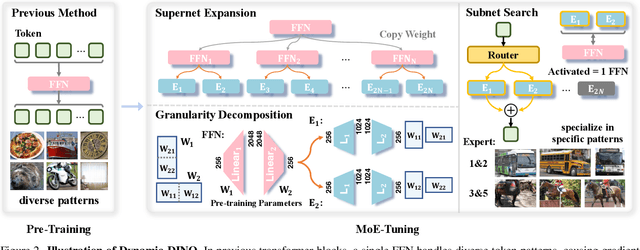

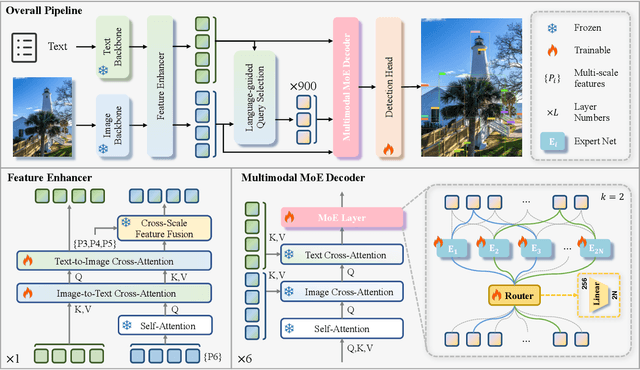
The Mixture of Experts (MoE) architecture has excelled in Large Vision-Language Models (LVLMs), yet its potential in real-time open-vocabulary object detectors, which also leverage large-scale vision-language datasets but smaller models, remains unexplored. This work investigates this domain, revealing intriguing insights. In the shallow layers, experts tend to cooperate with diverse peers to expand the search space. While in the deeper layers, fixed collaborative structures emerge, where each expert maintains 2-3 fixed partners and distinct expert combinations are specialized in processing specific patterns. Concretely, we propose Dynamic-DINO, which extends Grounding DINO 1.5 Edge from a dense model to a dynamic inference framework via an efficient MoE-Tuning strategy. Additionally, we design a granularity decomposition mechanism to decompose the Feed-Forward Network (FFN) of base model into multiple smaller expert networks, expanding the subnet search space. To prevent performance degradation at the start of fine-tuning, we further propose a pre-trained weight allocation strategy for the experts, coupled with a specific router initialization. During inference, only the input-relevant experts are activated to form a compact subnet. Experiments show that, pretrained with merely 1.56M open-source data, Dynamic-DINO outperforms Grounding DINO 1.5 Edge, pretrained on the private Grounding20M dataset.
TransBench: Breaking Barriers for Transferable Graphical User Interface Agents in Dynamic Digital Environments
May 23, 2025Graphical User Interface (GUI) agents, which autonomously operate on digital interfaces through natural language instructions, hold transformative potential for accessibility, automation, and user experience. A critical aspect of their functionality is grounding - the ability to map linguistic intents to visual and structural interface elements. However, existing GUI agents often struggle to adapt to the dynamic and interconnected nature of real-world digital environments, where tasks frequently span multiple platforms and applications while also being impacted by version updates. To address this, we introduce TransBench, the first benchmark designed to systematically evaluate and enhance the transferability of GUI agents across three key dimensions: cross-version transferability (adapting to version updates), cross-platform transferability (generalizing across platforms like iOS, Android, and Web), and cross-application transferability (handling tasks spanning functionally distinct apps). TransBench includes 15 app categories with diverse functionalities, capturing essential pages across versions and platforms to enable robust evaluation. Our experiments demonstrate significant improvements in grounding accuracy, showcasing the practical utility of GUI agents in dynamic, real-world environments. Our code and data will be publicly available at Github.
ReFF: Reinforcing Format Faithfulness in Language Models across Varied Tasks
Dec 12, 2024Following formatting instructions to generate well-structured content is a fundamental yet often unmet capability for large language models (LLMs). To study this capability, which we refer to as format faithfulness, we present FormatBench, a comprehensive format-related benchmark. Compared to previous format-related benchmarks, FormatBench involves a greater variety of tasks in terms of application scenes (traditional NLP tasks, creative works, autonomous agency tasks), human-LLM interaction styles (single-turn instruction, multi-turn chat), and format types (inclusion, wrapping, length, coding). Moreover, each task in FormatBench is attached with a format checker program. Extensive experiments on the benchmark reveal that state-of-the-art open- and closed-source LLMs still suffer from severe deficiency in format faithfulness. By virtue of the decidable nature of formats, we propose to Reinforce Format Faithfulness (ReFF) to help LLMs generate formatted output as instructed without compromising general quality. Without any annotated data, ReFF can substantially improve the format faithfulness rate (e.g., from 21.6% in original LLaMA3 to 95.0% on caption segmentation task), while keep the general quality comparable (e.g., from 47.3 to 46.4 in F1 scores). Combined with labeled training data, ReFF can simultaneously improve both format faithfulness (e.g., from 21.6% in original LLaMA3 to 75.5%) and general quality (e.g., from 47.3 to 61.6 in F1 scores). We further offer an interpretability analysis to explain how ReFF improves both format faithfulness and general quality.
High-Resolution Cloud Detection Network
Jul 10, 2024



The complexity of clouds, particularly in terms of texture detail at high resolutions, has not been well explored by most existing cloud detection networks. This paper introduces the High-Resolution Cloud Detection Network (HR-cloud-Net), which utilizes a hierarchical high-resolution integration approach. HR-cloud-Net integrates a high-resolution representation module, layer-wise cascaded feature fusion module, and multi-resolution pyramid pooling module to effectively capture complex cloud features. This architecture preserves detailed cloud texture information while facilitating feature exchange across different resolutions, thereby enhancing overall performance in cloud detection. Additionally, a novel approach is introduced wherein a student view, trained on noisy augmented images, is supervised by a teacher view processing normal images. This setup enables the student to learn from cleaner supervisions provided by the teacher, leading to improved performance. Extensive evaluations on three optical satellite image cloud detection datasets validate the superior performance of HR-cloud-Net compared to existing methods.The source code is available at \url{https://github.com/kunzhan/HR-cloud-Net}.
GVDIFF: Grounded Text-to-Video Generation with Diffusion Models
Jul 02, 2024
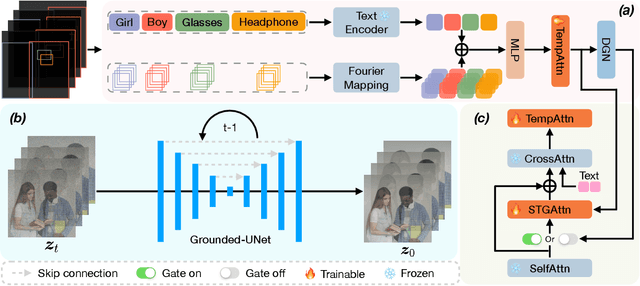

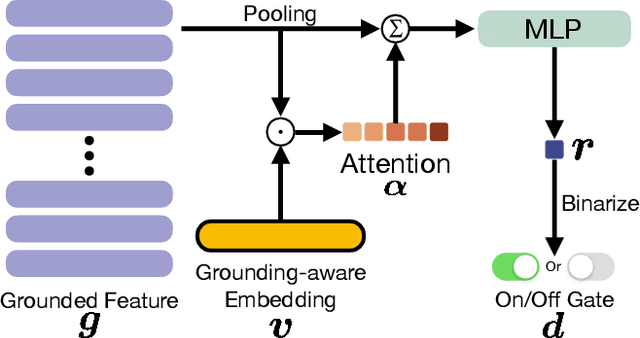
In text-to-video (T2V) generation, significant attention has been directed toward its development, yet unifying discrete and continuous grounding conditions in T2V generation remains under-explored. This paper proposes a Grounded text-to-Video generation framework, termed GVDIFF. First, we inject the grounding condition into the self-attention through an uncertainty-based representation to explicitly guide the focus of the network. Second, we introduce a spatial-temporal grounding layer that connects the grounding condition with target objects and enables the model with the grounded generation capacity in the spatial-temporal domain. Third, our dynamic gate network adaptively skips the redundant grounding process to selectively extract grounding information and semantics while improving efficiency. We extensively evaluate the grounded generation capacity of GVDIFF and demonstrate its versatility in applications, including long-range video generation, sequential prompts, and object-specific editing.
ScanFormer: Referring Expression Comprehension by Iteratively Scanning
Jun 26, 2024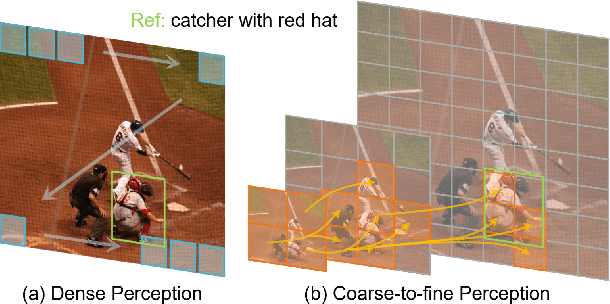
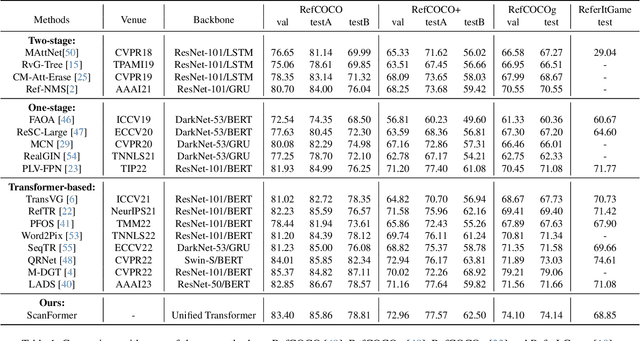
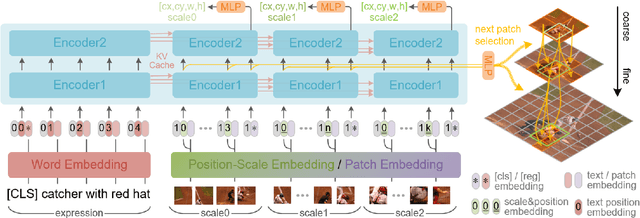
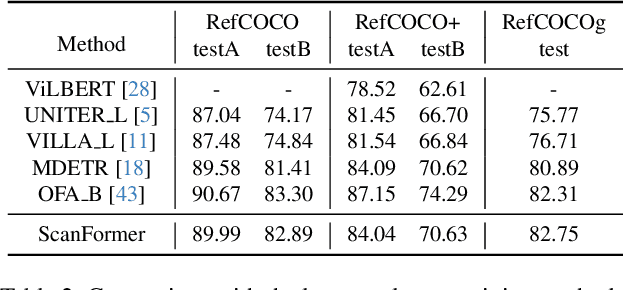
Referring Expression Comprehension (REC) aims to localize the target objects specified by free-form natural language descriptions in images. While state-of-the-art methods achieve impressive performance, they perform a dense perception of images, which incorporates redundant visual regions unrelated to linguistic queries, leading to additional computational overhead. This inspires us to explore a question: can we eliminate linguistic-irrelevant redundant visual regions to improve the efficiency of the model? Existing relevant methods primarily focus on fundamental visual tasks, with limited exploration in vision-language fields. To address this, we propose a coarse-to-fine iterative perception framework, called ScanFormer. It can iteratively exploit the image scale pyramid to extract linguistic-relevant visual patches from top to bottom. In each iteration, irrelevant patches are discarded by our designed informativeness prediction. Furthermore, we propose a patch selection strategy for discarded patches to accelerate inference. Experiments on widely used datasets, namely RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame, verify the effectiveness of our method, which can strike a balance between accuracy and efficiency.
A New Approach to Intuitionistic Fuzzy Decision Making Based on Projection Technology and Cosine Similarity Measure
Nov 20, 2023
For a multi-attribute decision making (MADM) problem, the information of alternatives under different attributes is given in the form of intuitionistic fuzzy number(IFN). Intuitionistic fuzzy set (IFS) plays an important role in dealing with un-certain and incomplete information. The similarity measure of intuitionistic fuzzy sets (IFSs) has always been a research hotspot. A new similarity measure of IFSs based on the projection technology and cosine similarity measure, which con-siders the direction and length of IFSs at the same time, is first proposed in this paper. The objective of the presented pa-per is to develop a MADM method and medical diagnosis method under IFS using the projection technology and cosine similarity measure. Some examples are used to illustrate the comparison results of the proposed algorithm and some exist-ing methods. The comparison result shows that the proposed algorithm is effective and can identify the optimal scheme accurately. In medical diagnosis area, it can be used to quickly diagnose disease. The proposed method enriches the exist-ing similarity measure methods and it can be applied to not only IFSs, but also other interval-valued intuitionistic fuzzy sets(IVIFSs) as well.
GaitGCI: Generative Counterfactual Intervention for Gait Recognition
Jun 06, 2023

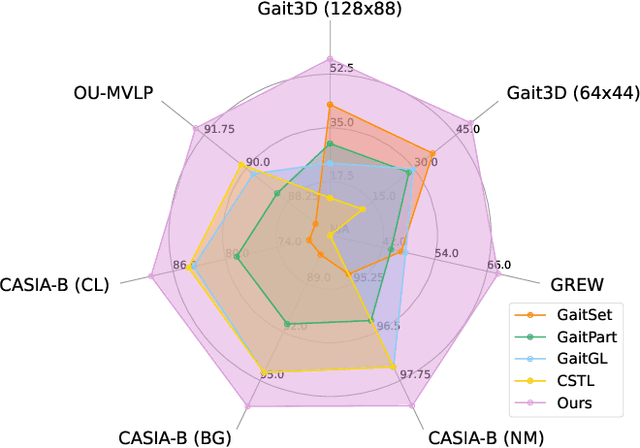
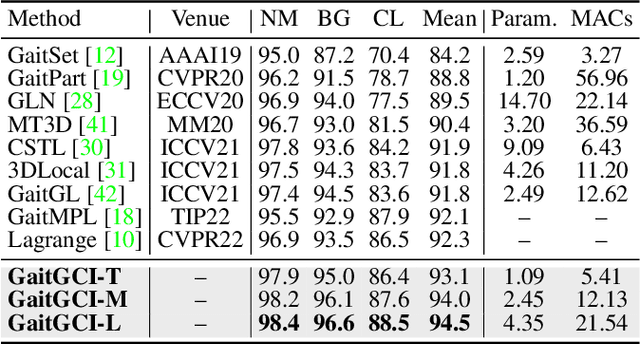
Gait is one of the most promising biometrics that aims to identify pedestrians from their walking patterns. However, prevailing methods are susceptible to confounders, resulting in the networks hardly focusing on the regions that reflect effective walking patterns. To address this fundamental problem in gait recognition, we propose a Generative Counterfactual Intervention framework, dubbed GaitGCI, consisting of Counterfactual Intervention Learning (CIL) and Diversity-Constrained Dynamic Convolution (DCDC). CIL eliminates the impacts of confounders by maximizing the likelihood difference between factual/counterfactual attention while DCDC adaptively generates sample-wise factual/counterfactual attention to efficiently perceive the sample-wise properties. With matrix decomposition and diversity constraint, DCDC guarantees the model to be efficient and effective. Extensive experiments indicate that proposed GaitGCI: 1) could effectively focus on the discriminative and interpretable regions that reflect gait pattern; 2) is model-agnostic and could be plugged into existing models to improve performance with nearly no extra cost; 3) efficiently achieves state-of-the-art performance on arbitrary scenarios (in-the-lab and in-the-wild).
MetaGait: Learning to Learn an Omni Sample Adaptive Representation for Gait Recognition
Jun 06, 2023Gait recognition, which aims at identifying individuals by their walking patterns, has recently drawn increasing research attention. However, gait recognition still suffers from the conflicts between the limited binary visual clues of the silhouette and numerous covariates with diverse scales, which brings challenges to the model's adaptiveness. In this paper, we address this conflict by developing a novel MetaGait that learns to learn an omni sample adaptive representation. Towards this goal, MetaGait injects meta-knowledge, which could guide the model to perceive sample-specific properties, into the calibration network of the attention mechanism to improve the adaptiveness from the omni-scale, omni-dimension, and omni-process perspectives. Specifically, we leverage the meta-knowledge across the entire process, where Meta Triple Attention and Meta Temporal Pooling are presented respectively to adaptively capture omni-scale dependency from spatial/channel/temporal dimensions simultaneously and to adaptively aggregate temporal information through integrating the merits of three complementary temporal aggregation methods. Extensive experiments demonstrate the state-of-the-art performance of the proposed MetaGait. On CASIA-B, we achieve rank-1 accuracy of 98.7%, 96.0%, and 89.3% under three conditions, respectively. On OU-MVLP, we achieve rank-1 accuracy of 92.4%.