 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving from Tool User to Creator via Training-Free Experience Reuse in Multimodal Reasoning
Feb 02, 2026Existing Tool-Integrated Reasoning (TIR) models have effectively extended the question-answering capabilities of LLMs by incorporating external tools. However, real-world scenarios present numerous open-ended problems where fixed tools often fail to meet task requirements. Furthermore, the lack of self-optimization mechanisms means that erroneous tool outputs can mislead the LLM's responses. Additionally, the construction of existing tools entails significant manual effort, which consequently constrains their applicability. Recognizing that the reasoning traces of LLMs encapsulate implicit problem-solving capabilities, we propose UCT, a novel training-free framework that transforms agents from tool users to tool creators. This approach harvests reasoning experiences and distills them into reusable assets. This method transforms the agent from a mere tool user into a tool creator, enabling adaptive tool creation and self-updating during the inference process. We also introduce a memory consolidation mechanism to maintain the tool library, ensuring high reusability of retained experiential memory for subsequent reasoning tasks. This novel automated tool construction paradigm continuously improves tool quality during reasoning, allowing the overall agent system to progress without additional training. Extensive experiments demonstrate that our method serves as a novel paradigm for enhancing the capabilities of TIR models. In particular, the significant performance gains achieved +20.86%$\uparrow$ and +23.04%$\uparrow$ on benchmarks across multi-domain mathematical and scientific reasoning tasks validate the self-evolving capability of the agent.
CloudMatch: Weak-to-Strong Consistency Learning for Semi-Supervised Cloud Detection
Jan 07, 2026Due to the high cost of annotating accurate pixel-level labels, semi-supervised learning has emerged as a promising approach for cloud detection. In this paper, we propose CloudMatch, a semi-supervised framework that effectively leverages unlabeled remote sensing imagery through view-consistency learning combined with scene-mixing augmentations. An observation behind CloudMatch is that cloud patterns exhibit structural diversity and contextual variability across different scenes and within the same scene category. Our key insight is that enforcing prediction consistency across diversely augmented views, incorporating both inter-scene and intra-scene mixing, enables the model to capture the structural diversity and contextual richness of cloud patterns. Specifically, CloudMatch generates one weakly augmented view along with two complementary strongly augmented views for each unlabeled image: one integrates inter-scene patches to simulate contextual variety, while the other employs intra-scene mixing to preserve semantic coherence. This approach guides pseudolabel generation and enhances generalization. Extensive experiments show that CloudMatch achieves good performance, demonstrating its capability to utilize unlabeled data efficiently and advance semi-supervised cloud detection.
WorldRFT: Latent World Model Planning with Reinforcement Fine-Tuning for Autonomous Driving
Dec 22, 2025Latent World Models enhance scene representation through temporal self-supervised learning, presenting a perception annotation-free paradigm for end-to-end autonomous driving. However, the reconstruction-oriented representation learning tangles perception with planning tasks, leading to suboptimal optimization for planning. To address this challenge, we propose WorldRFT, a planning-oriented latent world model framework that aligns scene representation learning with planning via a hierarchical planning decomposition and local-aware interactive refinement mechanism, augmented by reinforcement learning fine-tuning (RFT) to enhance safety-critical policy performance. Specifically, WorldRFT integrates a vision-geometry foundation model to improve 3D spatial awareness, employs hierarchical planning task decomposition to guide representation optimization, and utilizes local-aware iterative refinement to derive a planning-oriented driving policy. Furthermore, we introduce Group Relative Policy Optimization (GRPO), which applies trajectory Gaussianization and collision-aware rewards to fine-tune the driving policy, yielding systematic improvements in safety. WorldRFT achieves state-of-the-art (SOTA) performance on both open-loop nuScenes and closed-loop NavSim benchmarks. On nuScenes, it reduces collision rates by 83% (0.30% -> 0.05%). On NavSim, using camera-only sensors input, it attains competitive performance with the LiDAR-based SOTA method DiffusionDrive (87.8 vs. 88.1 PDMS).
OmniGen: Unified Multimodal Sensor Generation for Autonomous Driving
Dec 16, 2025Autonomous driving has seen remarkable advancements, largely driven by extensive real-world data collection. However, acquiring diverse and corner-case data remains costly and inefficient. Generative models have emerged as a promising solution by synthesizing realistic sensor data. However, existing approaches primarily focus on single-modality generation, leading to inefficiencies and misalignment in multimodal sensor data. To address these challenges, we propose OminiGen, which generates aligned multimodal sensor data in a unified framework. Our approach leverages a shared Bird\u2019s Eye View (BEV) space to unify multimodal features and designs a novel generalizable multimodal reconstruction method, UAE, to jointly decode LiDAR and multi-view camera data. UAE achieves multimodal sensor decoding through volume rendering, enabling accurate and flexible reconstruction. Furthermore, we incorporate a Diffusion Transformer (DiT) with a ControlNet branch to enable controllable multimodal sensor generation. Our comprehensive experiments demonstrate that OminiGen achieves desired performances in unified multimodal sensor data generation with multimodal consistency and flexible sensor adjustments.
CorrectAD: A Self-Correcting Agentic System to Improve End-to-end Planning in Autonomous Driving
Nov 17, 2025End-to-end planning methods are the de facto standard of the current autonomous driving system, while the robustness of the data-driven approaches suffers due to the notorious long-tail problem (i.e., rare but safety-critical failure cases). In this work, we explore whether recent diffusion-based video generation methods (a.k.a. world models), paired with structured 3D layouts, can enable a fully automated pipeline to self-correct such failure cases. We first introduce an agent to simulate the role of product manager, dubbed PM-Agent, which formulates data requirements to collect data similar to the failure cases. Then, we use a generative model that can simulate both data collection and annotation. However, existing generative models struggle to generate high-fidelity data conditioned on 3D layouts. To address this, we propose DriveSora, which can generate spatiotemporally consistent videos aligned with the 3D annotations requested by PM-Agent. We integrate these components into our self-correcting agentic system, CorrectAD. Importantly, our pipeline is an end-to-end model-agnostic and can be applied to improve any end-to-end planner. Evaluated on both nuScenes and a more challenging in-house dataset across multiple end-to-end planners, CorrectAD corrects 62.5% and 49.8% of failure cases, reducing collision rates by 39% and 27%, respectively.
DriveLiDAR4D: Sequential and Controllable LiDAR Scene Generation for Autonomous Driving
Nov 17, 2025The generation of realistic LiDAR point clouds plays a crucial role in the development and evaluation of autonomous driving systems. Although recent methods for 3D LiDAR point cloud generation have shown significant improvements, they still face notable limitations, including the lack of sequential generation capabilities and the inability to produce accurately positioned foreground objects and realistic backgrounds. These shortcomings hinder their practical applicability. In this paper, we introduce DriveLiDAR4D, a novel LiDAR generation pipeline consisting of multimodal conditions and a novel sequential noise prediction model LiDAR4DNet, capable of producing temporally consistent LiDAR scenes with highly controllable foreground objects and realistic backgrounds. To the best of our knowledge, this is the first work to address the sequential generation of LiDAR scenes with full scene manipulation capability in an end-to-end manner. We evaluated DriveLiDAR4D on the nuScenes and KITTI datasets, where we achieved an FRD score of 743.13 and an FVD score of 16.96 on the nuScenes dataset, surpassing the current state-of-the-art (SOTA) method, UniScene, with an performance boost of 37.2% in FRD and 24.1% in FVD, respectively.
The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning
Sep 16, 2025We present LightVLA, a simple yet effective differentiable token pruning framework for vision-language-action (VLA) models. While VLA models have shown impressive capability in executing real-world robotic tasks, their deployment on resource-constrained platforms is often bottlenecked by the heavy attention-based computation over large sets of visual tokens. LightVLA addresses this challenge through adaptive, performance-driven pruning of visual tokens: It generates dynamic queries to evaluate visual token importance, and adopts Gumbel softmax to enable differentiable token selection. Through fine-tuning, LightVLA learns to preserve the most informative visual tokens while pruning tokens which do not contribute to task execution, thereby improving efficiency and performance simultaneously. Notably, LightVLA requires no heuristic magic numbers and introduces no additional trainable parameters, making it compatible with modern inference frameworks. Experimental results demonstrate that LightVLA outperforms different VLA models and existing token pruning methods across diverse tasks on the LIBERO benchmark, achieving higher success rates with substantially reduced computational overhead. Specifically, LightVLA reduces FLOPs and latency by 59.1% and 38.2% respectively, with a 2.9% improvement in task success rate. Meanwhile, we also investigate the learnable query-based token pruning method LightVLA* with additional trainable parameters, which also achieves satisfactory performance. Our work reveals that as VLA pursues optimal performance, LightVLA spontaneously learns to prune tokens from a performance-driven perspective. To the best of our knowledge, LightVLA is the first work to apply adaptive visual token pruning to VLA tasks with the collateral goals of efficiency and performance, marking a significant step toward more efficient, powerful and practical real-time robotic systems.
CD-Mamba: Cloud detection with long-range spatial dependency modeling
Sep 05, 2025
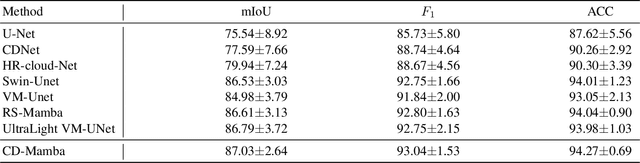
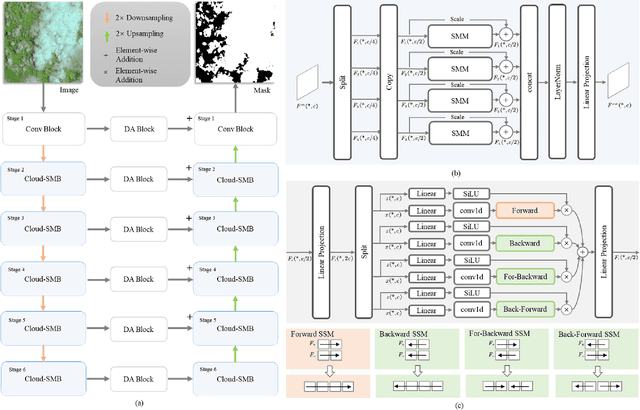
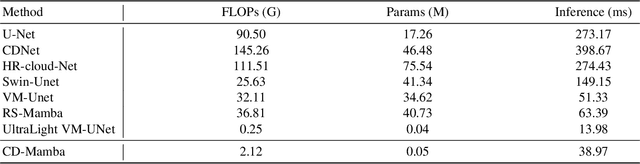
Remote sensing images are frequently obscured by cloud cover, posing significant challenges to data integrity and reliability. Effective cloud detection requires addressing both short-range spatial redundancies and long-range atmospheric similarities among cloud patches. Convolutional neural networks are effective at capturing local spatial dependencies, while Mamba has strong capabilities in modeling long-range dependencies. To fully leverage both local spatial relations and long-range dependencies, we propose CD-Mamba, a hybrid model that integrates convolution and Mamba's state-space modeling into a unified cloud detection network. CD-Mamba is designed to comprehensively capture pixelwise textural details and long term patchwise dependencies for cloud detection. This design enables CD-Mamba to manage both pixel-wise interactions and extensive patch-wise dependencies simultaneously, improving detection accuracy across diverse spatial scales. Extensive experiments validate the effectiveness of CD-Mamba and demonstrate its superior performance over existing methods.
DriveAgent-R1: Advancing VLM-based Autonomous Driving with Hybrid Thinking and Active Perception
Jul 28, 2025Vision-Language Models (VLMs) are advancing autonomous driving, yet their potential is constrained by myopic decision-making and passive perception, limiting reliability in complex environments. We introduce DriveAgent-R1 to tackle these challenges in long-horizon, high-level behavioral decision-making. DriveAgent-R1 features two core innovations: a Hybrid-Thinking framework that adaptively switches between efficient text-based and in-depth tool-based reasoning, and an Active Perception mechanism with a vision toolkit to proactively resolve uncertainties, thereby balancing decision-making efficiency and reliability. The agent is trained using a novel, three-stage progressive reinforcement learning strategy designed to master these hybrid capabilities. Extensive experiments demonstrate that DriveAgent-R1 achieves state-of-the-art performance, outperforming even leading proprietary large multimodal models, such as Claude Sonnet 4. Ablation studies validate our approach and confirm that the agent's decisions are robustly grounded in actively perceived visual evidence, paving a path toward safer and more intelligent autonomous systems.
GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control
May 29, 2025Recent advancements in world models have revolutionized dynamic environment simulation, allowing systems to foresee future states and assess potential actions. In autonomous driving, these capabilities help vehicles anticipate the behavior of other road users, perform risk-aware planning, accelerate training in simulation, and adapt to novel scenarios, thereby enhancing safety and reliability. Current approaches exhibit deficiencies in maintaining robust 3D geometric consistency or accumulating artifacts during occlusion handling, both critical for reliable safety assessment in autonomous navigation tasks. To address this, we introduce GeoDrive, which explicitly integrates robust 3D geometry conditions into driving world models to enhance spatial understanding and action controllability. Specifically, we first extract a 3D representation from the input frame and then obtain its 2D rendering based on the user-specified ego-car trajectory. To enable dynamic modeling, we propose a dynamic editing module during training to enhance the renderings by editing the positions of the vehicles. Extensive experiments demonstrate that our method significantly outperforms existing models in both action accuracy and 3D spatial awareness, leading to more realistic, adaptable, and reliable scene modeling for safer autonomous driving. Additionally, our model can generalize to novel trajectories and offers interactive scene editing capabilities, such as object editing and object trajectory control.