 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUST-DUB-IT: Video Dubbing via Joint Audio-Visual Diffusion
Jan 29, 2026Audio-Visual Foundation Models, which are pretrained to jointly generate sound and visual content, have recently shown an unprecedented ability to model multi-modal generation and editing, opening new opportunities for downstream tasks. Among these tasks, video dubbing could greatly benefit from such priors, yet most existing solutions still rely on complex, task-specific pipelines that struggle in real-world settings. In this work, we introduce a single-model approach that adapts a foundational audio-video diffusion model for video-to-video dubbing via a lightweight LoRA. The LoRA enables the model to condition on an input audio-video while jointly generating translated audio and synchronized facial motion. To train this LoRA, we leverage the generative model itself to synthesize paired multilingual videos of the same speaker. Specifically, we generate multilingual videos with language switches within a single clip, and then inpaint the face and audio in each half to match the language of the other half. By leveraging the rich generative prior of the audio-visual model, our approach preserves speaker identity and lip synchronization while remaining robust to complex motion and real-world dynamics. We demonstrate that our approach produces high-quality dubbed videos with improved visual fidelity, lip synchronization, and robustness compared to existing dubbing pipelines.
Saliency Driven Imagery Preprocessing for Efficient Compression -- Industrial Paper
Jan 24, 2026The compression of satellite imagery remains an important research area as hundreds of terabytes of images are collected every day, which drives up storage and bandwidth costs. Although progress has been made in increasing the resolution of these satellite images, many downstream tasks are only interested in small regions of any given image. These areas of interest vary by task but, once known, can be used to optimize how information within the image is encoded. Whereas standard image encoding methods, even those optimized for remote sensing, work on the whole image equally, there are emerging methods that can be guided by saliency maps to focus on important areas. In this work we show how imagery preprocessing techniques driven by saliency maps can be used with traditional lossy compression coding standards to create variable rate image compression within a single large satellite image. Specifically, we use variable sized smoothing kernels that map to different quantized saliency levels to process imagery pixels in order to optimize downstream compression and encoding schemes.
Relating Word Embedding Gender Biases to Gender Gaps: A Cross-Cultural Analysis
Jan 23, 2026Modern models for common NLP tasks often employ machine learning techniques and train on journalistic, social media, or other culturally-derived text. These have recently been scrutinized for racial and gender biases, rooting from inherent bias in their training text. These biases are often sub-optimal and recent work poses methods to rectify them; however, these biases may shed light on actual racial or gender gaps in the culture(s) that produced the training text, thereby helping us understand cultural context through big data. This paper presents an approach for quantifying gender bias in word embeddings, and then using them to characterize statistical gender gaps in education, politics, economics, and health. We validate these metrics on 2018 Twitter data spanning 51 U.S. regions and 99 countries. We correlate state and country word embedding biases with 18 international and 5 U.S.-based statistical gender gaps, characterizing regularities and predictive strength.
* 7 pages, 5 figures. Presented at the First Workshop on Gender Bias in Natural Language Processing (GeBNLP 2019)
WoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control
May 29, 2025Recent advancements in world models have revolutionized dynamic environment simulation, allowing systems to foresee future states and assess potential actions. In autonomous driving, these capabilities help vehicles anticipate the behavior of other road users, perform risk-aware planning, accelerate training in simulation, and adapt to novel scenarios, thereby enhancing safety and reliability. Current approaches exhibit deficiencies in maintaining robust 3D geometric consistency or accumulating artifacts during occlusion handling, both critical for reliable safety assessment in autonomous navigation tasks. To address this, we introduce GeoDrive, which explicitly integrates robust 3D geometry conditions into driving world models to enhance spatial understanding and action controllability. Specifically, we first extract a 3D representation from the input frame and then obtain its 2D rendering based on the user-specified ego-car trajectory. To enable dynamic modeling, we propose a dynamic editing module during training to enhance the renderings by editing the positions of the vehicles. Extensive experiments demonstrate that our method significantly outperforms existing models in both action accuracy and 3D spatial awareness, leading to more realistic, adaptable, and reliable scene modeling for safer autonomous driving. Additionally, our model can generalize to novel trajectories and offers interactive scene editing capabilities, such as object editing and object trajectory control.
Critical Foreign Policy Decisions (CFPD)-Benchmark: Measuring Diplomatic Preferences in Large Language Models
Mar 08, 2025As national security institutions increasingly integrate Artificial Intelligence (AI) into decision-making and content generation processes, understanding the inherent biases of large language models (LLMs) is crucial. This study presents a novel benchmark designed to evaluate the biases and preferences of seven prominent foundation models-Llama 3.1 8B Instruct, Llama 3.1 70B Instruct, GPT-4o, Gemini 1.5 Pro-002, Mixtral 8x22B, Claude 3.5 Sonnet, and Qwen2 72B-in the context of international relations (IR). We designed a bias discovery study around core topics in IR using 400-expert crafted scenarios to analyze results from our selected models. These scenarios focused on four topical domains including: military escalation, military and humanitarian intervention, cooperative behavior in the international system, and alliance dynamics. Our analysis reveals noteworthy variation among model recommendations based on scenarios designed for the four tested domains. Particularly, Qwen2 72B, Gemini 1.5 Pro-002 and Llama 3.1 8B Instruct models offered significantly more escalatory recommendations than Claude 3.5 Sonnet and GPT-4o models. All models exhibit some degree of country-specific biases, often recommending less escalatory and interventionist actions for China and Russia compared to the United States and the United Kingdom. These findings highlight the necessity for controlled deployment of LLMs in high-stakes environments, emphasizing the need for domain-specific evaluations and model fine-tuning to align with institutional objectives.
Training-free Regional Prompting for Diffusion Transformers
Nov 04, 2024



Diffusion models have demonstrated excellent capabilities in text-to-image generation. Their semantic understanding (i.e., prompt following) ability has also been greatly improved with large language models (e.g., T5, Llama). However, existing models cannot perfectly handle long and complex text prompts, especially when the text prompts contain various objects with numerous attributes and interrelated spatial relationships. While many regional prompting methods have been proposed for UNet-based models (SD1.5, SDXL), but there are still no implementations based on the recent Diffusion Transformer (DiT) architecture, such as SD3 and FLUX.1.In this report, we propose and implement regional prompting for FLUX.1 based on attention manipulation, which enables DiT with fined-grained compositional text-to-image generation capability in a training-free manner. Code is available at https://github.com/antonioo-c/Regional-Prompting-FLUX.
EVA: An Embodied World Model for Future Video Anticipation
Oct 20, 2024



World models integrate raw data from various modalities, such as images and language to simulate comprehensive interactions in the world, thereby displaying crucial roles in fields like mixed reality and robotics. Yet, applying the world model for accurate video prediction is quite challenging due to the complex and dynamic intentions of the various scenes in practice. In this paper, inspired by the human rethinking process, we decompose the complex video prediction into four meta-tasks that enable the world model to handle this issue in a more fine-grained manner. Alongside these tasks, we introduce a new benchmark named Embodied Video Anticipation Benchmark (EVA-Bench) to provide a well-rounded evaluation. EVA-Bench focused on evaluating the video prediction ability of human and robot actions, presenting significant challenges for both the language model and the generation model. Targeting embodied video prediction, we propose the Embodied Video Anticipator (EVA), a unified framework aiming at video understanding and generation. EVA integrates a video generation model with a visual language model, effectively combining reasoning capabilities with high-quality generation. Moreover, to enhance the generalization of our framework, we tailor-designed a multi-stage pretraining paradigm that adaptatively ensembles LoRA to produce high-fidelity results. Extensive experiments on EVA-Bench highlight the potential of EVA to significantly improve performance in embodied scenes, paving the way for large-scale pre-trained models in real-world prediction tasks.
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Jun 19, 2024


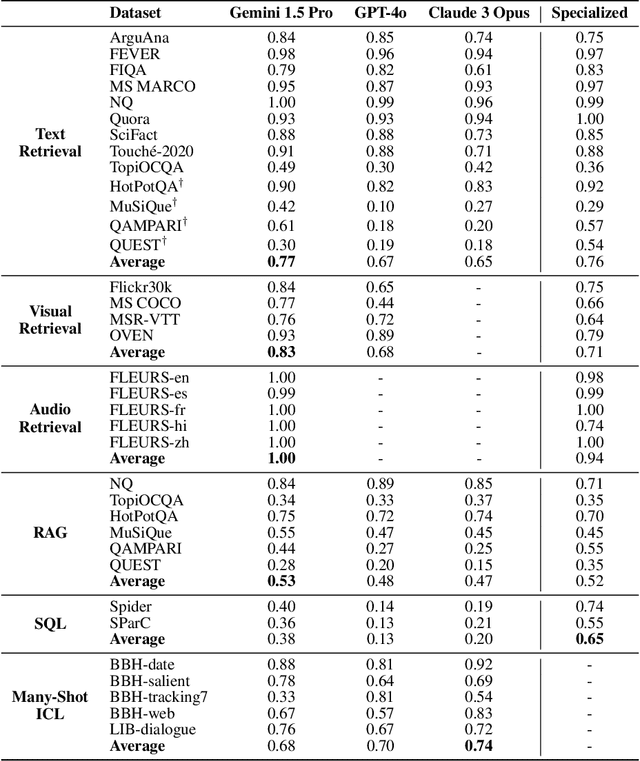
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.
InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation
Apr 04, 2024Tuning-free diffusion-based models have demonstrated significant potential in the realm of image personalization and customization. However, despite this notable progress, current models continue to grapple with several complex challenges in producing style-consistent image generation. Firstly, the concept of style is inherently underdetermined, encompassing a multitude of elements such as color, material, atmosphere, design, and structure, among others. Secondly, inversion-based methods are prone to style degradation, often resulting in the loss of fine-grained details. Lastly, adapter-based approaches frequently require meticulous weight tuning for each reference image to achieve a balance between style intensity and text controllability. In this paper, we commence by examining several compelling yet frequently overlooked observations. We then proceed to introduce InstantStyle, a framework designed to address these issues through the implementation of two key strategies: 1) A straightforward mechanism that decouples style and content from reference images within the feature space, predicated on the assumption that features within the same space can be either added to or subtracted from one another. 2) The injection of reference image features exclusively into style-specific blocks, thereby preventing style leaks and eschewing the need for cumbersome weight tuning, which often characterizes more parameter-heavy designs.Our work demonstrates superior visual stylization outcomes, striking an optimal balance between the intensity of style and the controllability of textual elements. Our codes will be available at https://github.com/InstantStyle/InstantStyle.