 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthenticated Delegation and Authorized AI Agents
Jan 16, 2025



The rapid deployment of autonomous AI agents creates urgent challenges around authorization, accountability, and access control in digital spaces. New standards are needed to know whom AI agents act on behalf of and guide their use appropriately, protecting online spaces while unlocking the value of task delegation to autonomous agents. We introduce a novel framework for authenticated, authorized, and auditable delegation of authority to AI agents, where human users can securely delegate and restrict the permissions and scope of agents while maintaining clear chains of accountability. This framework builds on existing identification and access management protocols, extending OAuth 2.0 and OpenID Connect with agent-specific credentials and metadata, maintaining compatibility with established authentication and web infrastructure. Further, we propose a framework for translating flexible, natural language permissions into auditable access control configurations, enabling robust scoping of AI agent capabilities across diverse interaction modalities. Taken together, this practical approach facilitates immediate deployment of AI agents while addressing key security and accountability concerns, working toward ensuring agentic AI systems perform only appropriate actions and providing a tool for digital service providers to enable AI agent interactions without risking harm from scalable interaction.
Bridging the Data Provenance Gap Across Text, Speech and Video
Dec 19, 2024



Progress in AI is driven largely by the scale and quality of training data. Despite this, there is a deficit of empirical analysis examining the attributes of well-established datasets beyond text. In this work we conduct the largest and first-of-its-kind longitudinal audit across modalities--popular text, speech, and video datasets--from their detailed sourcing trends and use restrictions to their geographical and linguistic representation. Our manual analysis covers nearly 4000 public datasets between 1990-2024, spanning 608 languages, 798 sources, 659 organizations, and 67 countries. We find that multimodal machine learning applications have overwhelmingly turned to web-crawled, synthetic, and social media platforms, such as YouTube, for their training sets, eclipsing all other sources since 2019. Secondly, tracing the chain of dataset derivations we find that while less than 33% of datasets are restrictively licensed, over 80% of the source content in widely-used text, speech, and video datasets, carry non-commercial restrictions. Finally, counter to the rising number of languages and geographies represented in public AI training datasets, our audit demonstrates measures of relative geographical and multilingual representation have failed to significantly improve their coverage since 2013. We believe the breadth of our audit enables us to empirically examine trends in data sourcing, restrictions, and Western-centricity at an ecosystem-level, and that visibility into these questions are essential to progress in responsible AI. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire multimodal audit, allowing practitioners to trace data provenance across text, speech, and video.
Consent in Crisis: The Rapid Decline of the AI Data Commons
Jul 24, 2024


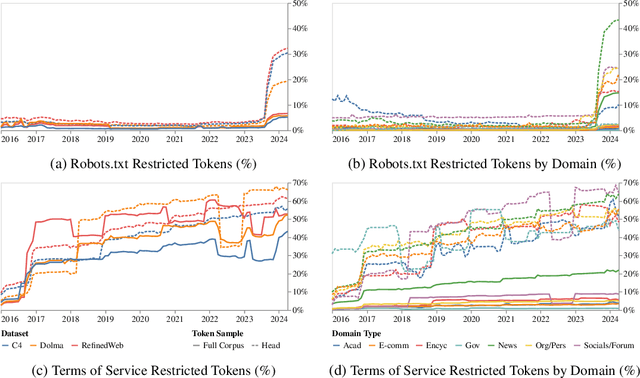
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the first, large-scale, longitudinal audit of the consent protocols for the web domains underlying AI training corpora. Our audit of 14,000 web domains provides an expansive view of crawlable web data and how codified data use preferences are changing over time. We observe a proliferation of AI-specific clauses to limit use, acute differences in restrictions on AI developers, as well as general inconsistencies between websites' expressed intentions in their Terms of Service and their robots.txt. We diagnose these as symptoms of ineffective web protocols, not designed to cope with the widespread re-purposing of the internet for AI. Our longitudinal analyses show that in a single year (2023-2024) there has been a rapid crescendo of data restrictions from web sources, rendering ~5%+ of all tokens in C4, or 28%+ of the most actively maintained, critical sources in C4, fully restricted from use. For Terms of Service crawling restrictions, a full 45% of C4 is now restricted. If respected or enforced, these restrictions are rapidly biasing the diversity, freshness, and scaling laws for general-purpose AI systems. We hope to illustrate the emerging crises in data consent, for both developers and creators. The foreclosure of much of the open web will impact not only commercial AI, but also non-commercial AI and academic research.
Data Authenticity, Consent, & Provenance for AI are all broken: what will it take to fix them?
Apr 19, 2024

New capabilities in foundation models are owed in large part to massive, widely-sourced, and under-documented training data collections. Existing practices in data collection have led to challenges in documenting data transparency, tracing authenticity, verifying consent, privacy, representation, bias, copyright infringement, and the overall development of ethical and trustworthy foundation models. In response, regulation is emphasizing the need for training data transparency to understand foundation models' limitations. Based on a large-scale analysis of the foundation model training data landscape and existing solutions, we identify the missing infrastructure to facilitate responsible foundation model development practices. We examine the current shortcomings of common tools for tracing data authenticity, consent, and documentation, and outline how policymakers, developers, and data creators can facilitate responsible foundation model development by adopting universal data provenance standards.
Leveraging Large Language Models for Learning Complex Legal Concepts through Storytelling
Feb 26, 2024



Making legal knowledge accessible to non-experts is crucial for enhancing general legal literacy and encouraging civic participation in democracy. However, legal documents are often challenging to understand for people without legal backgrounds. In this paper, we present a novel application of large language models (LLMs) in legal education to help non-experts learn intricate legal concepts through storytelling, an effective pedagogical tool in conveying complex and abstract concepts. We also introduce a new dataset LegalStories, which consists of 295 complex legal doctrines, each accompanied by a story and a set of multiple-choice questions generated by LLMs. To construct the dataset, we experiment with various LLMs to generate legal stories explaining these concepts. Furthermore, we use an expert-in-the-loop method to iteratively design multiple-choice questions. Then, we evaluate the effectiveness of storytelling with LLMs through an RCT experiment with legal novices on 10 samples from the dataset. We find that LLM-generated stories enhance comprehension of legal concepts and interest in law among non-native speakers compared to only definitions. Moreover, stories consistently help participants relate legal concepts to their lives. Finally, we find that learning with stories shows a higher retention rate for non-native speakers in the follow-up assessment. Our work has strong implications for using LLMs in promoting teaching and learning in the legal field and beyond.
Verifiable evaluations of machine learning models using zkSNARKs
Feb 05, 2024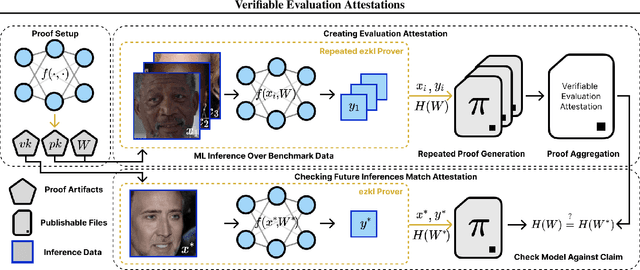

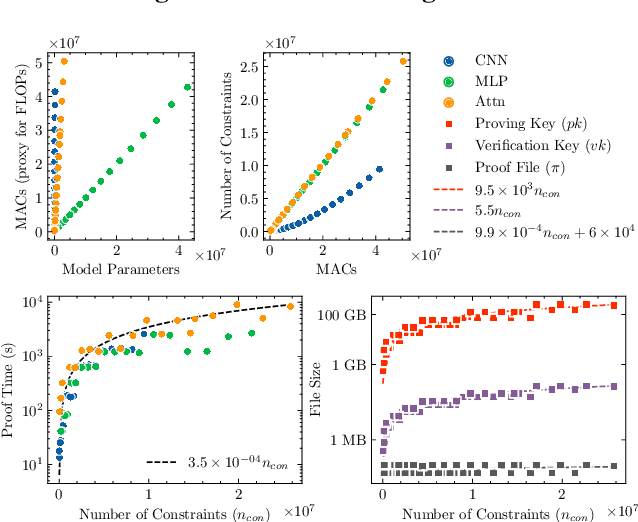
In a world of increasing closed-source commercial machine learning models, model evaluations from developers must be taken at face value. These benchmark results, whether over task accuracy, bias evaluations, or safety checks, are traditionally impossible to verify by a model end-user without the costly or impossible process of re-performing the benchmark on black-box model outputs. This work presents a method of verifiable model evaluation using model inference through zkSNARKs. The resulting zero-knowledge computational proofs of model outputs over datasets can be packaged into verifiable evaluation attestations showing that models with fixed private weights achieve stated performance or fairness metrics over public inputs. These verifiable attestations can be performed on any standard neural network model with varying compute requirements. For the first time, we demonstrate this across a sample of real-world models and highlight key challenges and design solutions. This presents a new transparency paradigm in the verifiable evaluation of private models.
LePaRD: A Large-Scale Dataset of Judges Citing Precedents
Nov 15, 2023



We present the Legal Passage Retrieval Dataset LePaRD. LePaRD is a massive collection of U.S. federal judicial citations to precedent in context. The dataset aims to facilitate work on legal passage prediction, a challenging practice-oriented legal retrieval and reasoning task. Legal passage prediction seeks to predict relevant passages from precedential court decisions given the context of a legal argument. We extensively evaluate various retrieval approaches on LePaRD, and find that classification appears to work best. However, we note that legal precedent prediction is a difficult task, and there remains significant room for improvement. We hope that by publishing LePaRD, we will encourage others to engage with a legal NLP task that promises to help expand access to justice by reducing the burden associated with legal research. A subset of the LePaRD dataset is freely available and the whole dataset will be released upon publication.
The Data Provenance Initiative: A Large Scale Audit of Dataset Licensing & Attribution in AI
Nov 04, 2023



The race to train language models on vast, diverse, and inconsistently documented datasets has raised pressing concerns about the legal and ethical risks for practitioners. To remedy these practices threatening data transparency and understanding, we convene a multi-disciplinary effort between legal and machine learning experts to systematically audit and trace 1800+ text datasets. We develop tools and standards to trace the lineage of these datasets, from their source, creators, series of license conditions, properties, and subsequent use. Our landscape analysis highlights the sharp divides in composition and focus of commercially open vs closed datasets, with closed datasets monopolizing important categories: lower resource languages, more creative tasks, richer topic variety, newer and more synthetic training data. This points to a deepening divide in the types of data that are made available under different license conditions, and heightened implications for jurisdictional legal interpretations of copyright and fair use. We also observe frequent miscategorization of licenses on widely used dataset hosting sites, with license omission of 70%+ and error rates of 50%+. This points to a crisis in misattribution and informed use of the most popular datasets driving many recent breakthroughs. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire audit, with an interactive UI, the Data Provenance Explorer, which allows practitioners to trace and filter on data provenance for the most popular open source finetuning data collections: www.dataprovenance.org.
The Law and NLP: Bridging Disciplinary Disconnects
Oct 22, 2023

Legal practice is intrinsically rooted in the fabric of language, yet legal practitioners and scholars have been slow to adopt tools from natural language processing (NLP). At the same time, the legal system is experiencing an access to justice crisis, which could be partially alleviated with NLP. In this position paper, we argue that the slow uptake of NLP in legal practice is exacerbated by a disconnect between the needs of the legal community and the focus of NLP researchers. In a review of recent trends in the legal NLP literature, we find limited overlap between the legal NLP community and legal academia. Our interpretation is that some of the most popular legal NLP tasks fail to address the needs of legal practitioners. We discuss examples of legal NLP tasks that promise to bridge disciplinary disconnects and highlight interesting areas for legal NLP research that remain underexplored.
Art and the science of generative AI: A deeper dive
Jun 07, 2023A new class of tools, colloquially called generative AI, can produce high-quality artistic media for visual arts, concept art, music, fiction, literature, video, and animation. The generative capabilities of these tools are likely to fundamentally alter the creative processes by which creators formulate ideas and put them into production. As creativity is reimagined, so too may be many sectors of society. Understanding the impact of generative AI - and making policy decisions around it - requires new interdisciplinary scientific inquiry into culture, economics, law, algorithms, and the interaction of technology and creativity. We argue that generative AI is not the harbinger of art's demise, but rather is a new medium with its own distinct affordances. In this vein, we consider the impacts of this new medium on creators across four themes: aesthetics and culture, legal questions of ownership and credit, the future of creative work, and impacts on the contemporary media ecosystem. Across these themes, we highlight key research questions and directions to inform policy and beneficial uses of the technology.