 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysiology as Language: Translating Respiration to Sleep EEG
Jan 31, 2026This paper introduces a novel cross-physiology translation task: synthesizing sleep electroencephalography (EEG) from respiration signals. To address the significant complexity gap between the two modalities, we propose a waveform-conditional generative framework that preserves fine-grained respiratory dynamics while constraining the EEG target space through discrete tokenization. Trained on over 28,000 individuals, our model achieves a 7% Mean Absolute Error in EEG spectrogram reconstruction. Beyond reconstruction, the synthesized EEG supports downstream tasks with performance comparable to ground truth EEG on age estimation (MAE 5.0 vs. 5.1 years), sex detection (AUROC 0.81 vs. 0.82), and sleep staging (Accuracy 0.84 vs. 0.88), significantly outperforming baselines trained directly on breathing. Finally, we demonstrate that the framework generalizes to contactless sensing by synthesizing EEG from wireless radio-frequency reflections, highlighting the feasibility of remote, non-contact neurological assessment during sleep.
Distilling to Hybrid Attention Models via KL-Guided Layer Selection
Dec 23, 2025Distilling pretrained softmax attention Transformers into more efficient hybrid architectures that interleave softmax and linear attention layers is a promising approach for improving the inference efficiency of LLMs without requiring expensive pretraining from scratch. A critical factor in the conversion process is layer selection, i.e., deciding on which layers to convert to linear attention variants. This paper describes a simple and efficient recipe for layer selection that uses layer importance scores derived from a small amount of training on generic text data. Once the layers have been selected we use a recent pipeline for the distillation process itself \citep[RADLADS;][]{goldstein2025radlads}, which consists of attention weight transfer, hidden state alignment, KL-based distribution matching, followed by a small amount of finetuning. We find that this approach is more effective than existing approaches for layer selection, including heuristics that uniformly interleave linear attentions based on a fixed ratio, as well as more involved approaches that rely on specialized diagnostic datasets.
MIDI-LLM: Adapting Large Language Models for Text-to-MIDI Music Generation
Nov 06, 2025We present MIDI-LLM, an LLM for generating multitrack MIDI music from free-form text prompts. Our approach expands a text LLM's vocabulary to include MIDI tokens, and uses a two-stage training recipe to endow text-to-MIDI abilities. By preserving the original LLM's parameter structure, we can directly leverage the vLLM library for accelerated inference. Experiments show that MIDI-LLM achieves higher quality, better text control, and faster inference compared to the recent Text2midi model. Live demo at https://midi-llm-demo.vercel.app.
Learning to Interpret Weight Differences in Language Models
Oct 06, 2025Finetuning (pretrained) language models is a standard approach for updating their internal parametric knowledge and specializing them to new tasks and domains. However, the corresponding model weight changes ("weight diffs") are not generally interpretable. While inspecting the finetuning dataset can give a sense of how the model might have changed, these datasets are often not publicly available or are too large to work with directly. Towards the goal of comprehensively understanding weight diffs in natural language, we introduce Diff Interpretation Tuning (DIT), a method that trains models to describe their own finetuning-induced modifications. Our approach uses synthetic, labeled weight diffs to train a DIT adapter, which can be applied to a compatible finetuned model to make it describe how it has changed. We demonstrate in two proof-of-concept settings (reporting hidden behaviors and summarizing finetuned knowledge) that our method enables models to describe their finetuning-induced modifications using accurate natural language descriptions.
On the Same Wavelength? Evaluating Pragmatic Reasoning in Language Models across Broad Concepts
Sep 08, 2025

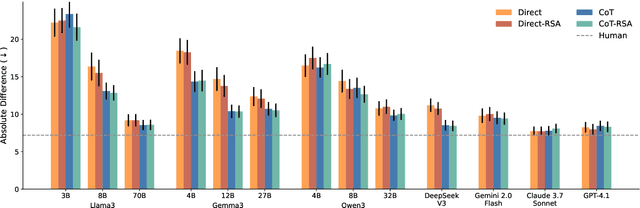
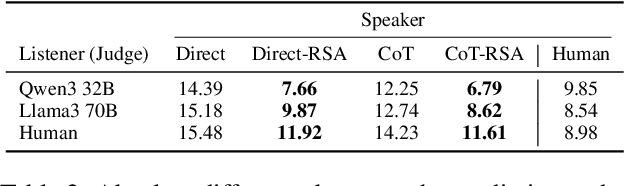
Language use is shaped by pragmatics -- i.e., reasoning about communicative goals and norms in context. As language models (LMs) are increasingly used as conversational agents, it becomes ever more important to understand their pragmatic reasoning abilities. We propose an evaluation framework derived from Wavelength, a popular communication game where a speaker and a listener communicate about a broad range of concepts in a granular manner. We study a range of LMs on both language comprehension and language production using direct and Chain-of-Thought (CoT) prompting, and further explore a Rational Speech Act (RSA) approach to incorporating Bayesian pragmatic reasoning into LM inference. We find that state-of-the-art LMs, but not smaller ones, achieve strong performance on language comprehension, obtaining similar-to-human accuracy and exhibiting high correlations with human judgments even without CoT prompting or RSA. On language production, CoT can outperform direct prompting, and using RSA provides significant improvements over both approaches. Our study helps identify the strengths and limitations in LMs' pragmatic reasoning abilities and demonstrates the potential for improving them with RSA, opening up future avenues for understanding conceptual representation, language understanding, and social reasoning in LMs and humans.
Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Jul 22, 2025When language models (LMs) are trained via reinforcement learning (RL) to generate natural language "reasoning chains", their performance improves on a variety of difficult question answering tasks. Today, almost all successful applications of RL for reasoning use binary reward functions that evaluate the correctness of LM outputs. Because such reward functions do not penalize guessing or low-confidence outputs, they often have the unintended side-effect of degrading calibration and increasing the rate at which LMs generate incorrect responses (or "hallucinate") in other problem domains. This paper describes RLCR (Reinforcement Learning with Calibration Rewards), an approach to training reasoning models that jointly improves accuracy and calibrated confidence estimation. During RLCR, LMs generate both predictions and numerical confidence estimates after reasoning. They are trained to optimize a reward function that augments a binary correctness score with a Brier score -- a scoring rule for confidence estimates that incentivizes calibrated prediction. We first prove that this reward function (or any analogous reward function that uses a bounded, proper scoring rule) yields models whose predictions are both accurate and well-calibrated. We next show that across diverse datasets, RLCR substantially improves calibration with no loss in accuracy, on both in-domain and out-of-domain evaluations -- outperforming both ordinary RL training and classifiers trained to assign post-hoc confidence scores. While ordinary RL hurts calibration, RLCR improves it. Finally, we demonstrate that verbalized confidence can be leveraged at test time to improve accuracy and calibration via confidence-weighted scaling methods. Our results show that explicitly optimizing for calibration can produce more generally reliable reasoning models.
Self-Adapting Language Models
Jun 12, 2025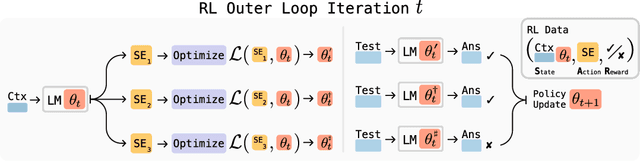


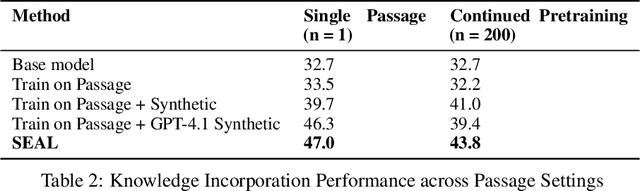
Large language models (LLMs) are powerful but static; they lack mechanisms to adapt their weights in response to new tasks, knowledge, or examples. We introduce Self-Adapting LLMs (SEAL), a framework that enables LLMs to self-adapt by generating their own finetuning data and update directives. Given a new input, the model produces a self-edit-a generation that may restructure the information in different ways, specify optimization hyperparameters, or invoke tools for data augmentation and gradient-based updates. Through supervised finetuning (SFT), these self-edits result in persistent weight updates, enabling lasting adaptation. To train the model to produce effective self-edits, we use a reinforcement learning loop with the downstream performance of the updated model as the reward signal. Unlike prior approaches that rely on separate adaptation modules or auxiliary networks, SEAL directly uses the model's own generation to control its adaptation process. Experiments on knowledge incorporation and few-shot generalization show that SEAL is a promising step toward language models capable of self-directed adaptation. Our website and code is available at https://jyopari.github.io/posts/seal.
Log-Linear Attention
Jun 05, 2025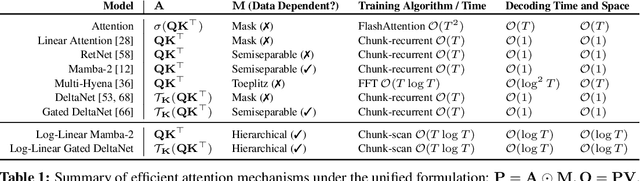
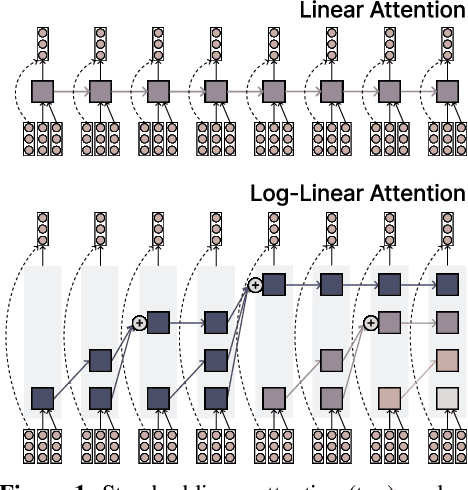
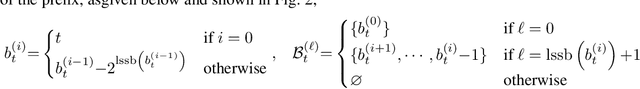
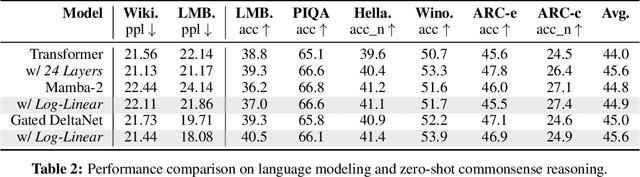
The attention mechanism in Transformers is an important primitive for accurate and scalable sequence modeling. Its quadratic-compute and linear-memory complexity however remain significant bottlenecks. Linear attention and state-space models enable linear-time, constant-memory sequence modeling and can moreover be trained efficiently through matmul-rich parallelization across sequence length. However, at their core these models are still RNNs, and thus their use of a fixed-size hidden state to model the context is a fundamental limitation. This paper develops log-linear attention, an attention mechanism that balances linear attention's efficiency and the expressiveness of softmax attention. Log-linear attention replaces the fixed-size hidden state with a logarithmically growing set of hidden states. We show that with a particular growth function, log-linear attention admits a similarly matmul-rich parallel form whose compute cost is log-linear in sequence length. Log-linear attention is a general framework and can be applied on top of existing linear attention variants. As case studies, we instantiate log-linear variants of two recent architectures -- Mamba-2 and Gated DeltaNet -- and find they perform well compared to their linear-time variants.
FlashFormer: Whole-Model Kernels for Efficient Low-Batch Inference
May 28, 2025The size and compute characteristics of modern large language models have led to an increased interest in developing specialized kernels tailored for training and inference. Existing kernels primarily optimize for compute utilization, targeting the large-batch training and inference settings. However, low-batch inference, where memory bandwidth and kernel launch overheads contribute are significant factors, remains important for many applications of interest such as in edge deployment and latency-sensitive applications. This paper describes FlashFormer, a proof-of-concept kernel for accelerating single-batch inference for transformer-based large language models. Across various model sizes and quantizations settings, we observe nontrivial speedups compared to existing state-of-the-art inference kernels.
PaTH Attention: Position Encoding via Accumulating Householder Transformations
May 22, 2025The attention mechanism is a core primitive in modern large language models (LLMs) and AI more broadly. Since attention by itself is permutation-invariant, position encoding is essential for modeling structured domains such as language. Rotary position encoding (RoPE) has emerged as the de facto standard approach for position encoding and is part of many modern LLMs. However, in RoPE the key/query transformation between two elements in a sequence is only a function of their relative position and otherwise independent of the actual input. This limits the expressivity of RoPE-based transformers. This paper describes PaTH, a flexible data-dependent position encoding scheme based on accumulated products of Householder(like) transformations, where each transformation is data-dependent, i.e., a function of the input. We derive an efficient parallel algorithm for training through exploiting a compact representation of products of Householder matrices, and implement a FlashAttention-style blockwise algorithm that minimizes I/O cost. Across both targeted synthetic benchmarks and moderate-scale real-world language modeling experiments, we find that PaTH demonstrates superior performance compared to RoPE and other recent baselines.