 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashFormer: Whole-Model Kernels for Efficient Low-Batch Inference
May 28, 2025The size and compute characteristics of modern large language models have led to an increased interest in developing specialized kernels tailored for training and inference. Existing kernels primarily optimize for compute utilization, targeting the large-batch training and inference settings. However, low-batch inference, where memory bandwidth and kernel launch overheads contribute are significant factors, remains important for many applications of interest such as in edge deployment and latency-sensitive applications. This paper describes FlashFormer, a proof-of-concept kernel for accelerating single-batch inference for transformer-based large language models. Across various model sizes and quantizations settings, we observe nontrivial speedups compared to existing state-of-the-art inference kernels.
Ladder-residual: parallelism-aware architecture for accelerating large model inference with communication overlapping
Jan 11, 2025



Large language model inference is both memory-intensive and time-consuming, often requiring distributed algorithms to efficiently scale. Various model parallelism strategies are used in multi-gpu training and inference to partition computation across multiple devices, reducing memory load and computation time. However, using model parallelism necessitates communication of information between GPUs, which has been a major bottleneck and limits the gains obtained by scaling up the number of devices. We introduce Ladder Residual, a simple architectural modification applicable to all residual-based models that enables straightforward overlapping that effectively hides the latency of communication. Our insight is that in addition to systems optimization, one can also redesign the model architecture to decouple communication from computation. While Ladder Residual can allow communication-computation decoupling in conventional parallelism patterns, we focus on Tensor Parallelism in this paper, which is particularly bottlenecked by its heavy communication. For a Transformer model with 70B parameters, applying Ladder Residual to all its layers can achieve 30% end-to-end wall clock speed up at inference time with TP sharding over 8 devices. We refer the resulting Transformer model as the Ladder Transformer. We train a 1B and 3B Ladder Transformer from scratch and observe comparable performance to a standard dense transformer baseline. We also show that it is possible to convert parts of the Llama-3.1 8B model to our Ladder Residual architecture with minimal accuracy degradation by only retraining for 3B tokens.
Fast Matrix Multiplications for Lookup Table-Quantized LLMs
Jul 15, 2024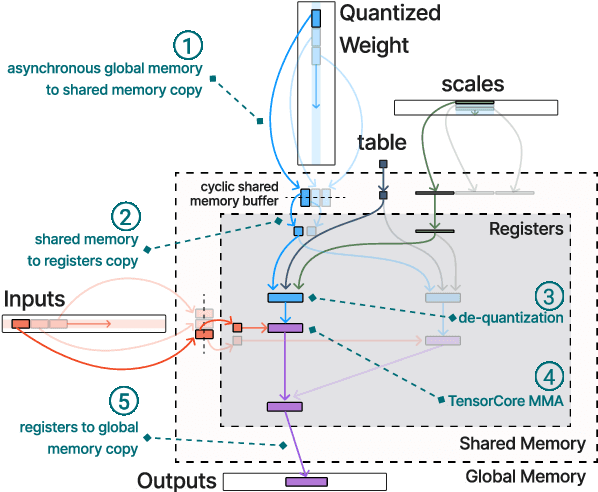
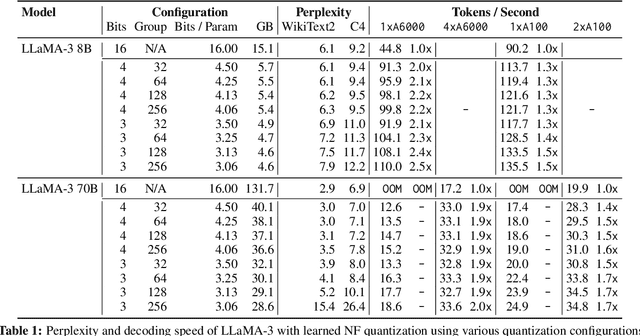
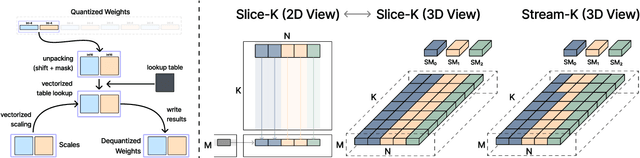
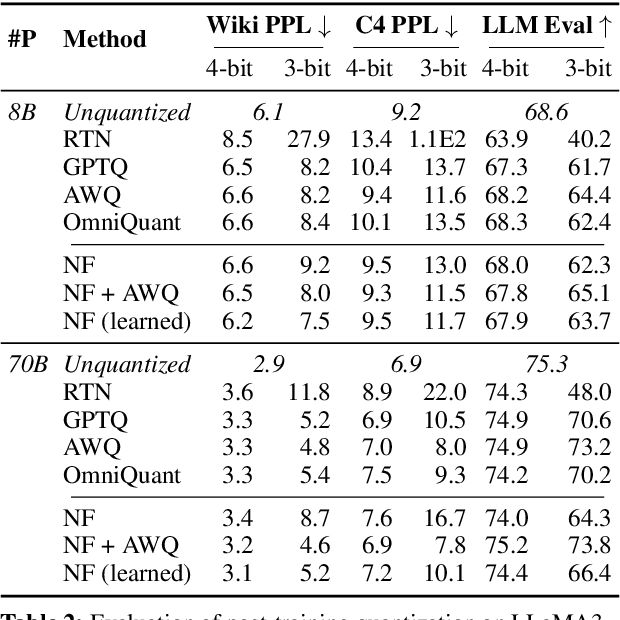
The deployment of large language models (LLMs) is often constrained by memory bandwidth, where the primary bottleneck is the cost of transferring model parameters from the GPU's global memory to its registers. When coupled with custom kernels that fuse the dequantization and matmul operations, weight-only quantization can thus enable faster inference by reducing the amount of memory movement. However, developing high-performance kernels for weight-quantized LLMs presents substantial challenges, especially when the weights are compressed to non-evenly-divisible bit widths (e.g., 3 bits) with non-uniform, lookup table (LUT) quantization. This paper describes FLUTE, a flexible lookup table engine for LUT-quantized LLMs, which uses offline restructuring of the quantized weight matrix to minimize bit manipulations associated with unpacking, and vectorization and duplication of the lookup table to mitigate shared memory bandwidth constraints. At batch sizes < 32 and quantization group size of 128 (typical in LLM inference), the FLUTE kernel can be 2-4x faster than existing GEMM kernels. As an application of FLUTE, we explore a simple extension to lookup table-based NormalFloat quantization and apply it to quantize LLaMA3 to various configurations, obtaining competitive quantization performance against strong baselines while obtaining an end-to-end throughput increase of 1.5 to 2 times.
Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
May 21, 2024Key-value (KV) caching plays an essential role in accelerating decoding for transformer-based autoregressive large language models (LLMs). However, the amount of memory required to store the KV cache can become prohibitive at long sequence lengths and large batch sizes. Since the invention of the transformer, two of the most effective interventions discovered for reducing the size of the KV cache have been Multi-Query Attention (MQA) and its generalization, Grouped-Query Attention (GQA). MQA and GQA both modify the design of the attention block so that multiple query heads can share a single key/value head, reducing the number of distinct key/value heads by a large factor while only minimally degrading accuracy. In this paper, we show that it is possible to take Multi-Query Attention a step further by also sharing key and value heads between adjacent layers, yielding a new attention design we call Cross-Layer Attention (CLA). With CLA, we find that it is possible to reduce the size of the KV cache by another 2x while maintaining nearly the same accuracy as unmodified MQA. In experiments training 1B- and 3B-parameter models from scratch, we demonstrate that CLA provides a Pareto improvement over the memory/accuracy tradeoffs which are possible with traditional MQA, enabling inference with longer sequence lengths and larger batch sizes than would otherwise be possible
Hydra: Sequentially-Dependent Draft Heads for Medusa Decoding
Feb 07, 2024To combat the memory bandwidth-bound nature of autoregressive LLM inference, previous research has proposed the speculative decoding framework. To perform speculative decoding, a small draft model proposes candidate continuations of the input sequence, that are then verified in parallel by the base model. One way to specify the draft model, as used in the recent Medusa decoding framework, is as a collection of light-weight heads, called draft heads, that operate on the base model's hidden states. To date, all existing draft heads have been sequentially independent, meaning that they speculate tokens in the candidate continuation independently of any preceding tokens in the candidate continuation. In this work, we propose Hydra heads, a sequentially dependent, drop-in replacement for standard draft heads that significantly improves speculation accuracy. Decoding with Hydra heads improves throughput compared to Medusa decoding with standard draft heads. We further explore the design space of Hydra head training objectives and architectures, and propose a carefully-tuned Hydra head recipe, which we call Hydra++, that improves decoding throughput by 1.31x and 2.71x compared to Medusa decoding and autoregressive decoding, respectively. Overall, Hydra heads are a simple intervention on standard draft heads that significantly improve the end-to-end speed of draft head based speculative decoding.
Striped Attention: Faster Ring Attention for Causal Transformers
Nov 15, 2023



To help address the growing demand for ever-longer sequence lengths in transformer models, Liu et al. recently proposed Ring Attention, an exact attention algorithm capable of overcoming per-device memory bottle- necks by distributing self-attention across multiple devices. In this paper, we study the performance characteristics of Ring Attention in the important special case of causal transformer models, and identify a key workload imbal- ance due to triangular structure of causal attention computations. We propose a simple extension to Ring Attention, which we call Striped Attention to fix this imbalance. Instead of devices having contiguous subsequences, each device has a subset of tokens distributed uniformly throughout the sequence, which we demonstrate leads to more even workloads. In experiments running Striped Attention on A100 GPUs and TPUv4s, we are able to achieve up to 1.45x end-to-end throughput improvements over the original Ring Attention algorithm on causal transformer training at a sequence length of 256k. Furthermore, on 16 TPUv4 chips, we were able to achieve 1.65x speedups at sequence lengths of 786k. We release the code for our experiments as open source