 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashFormer: Whole-Model Kernels for Efficient Low-Batch Inference
May 28, 2025The size and compute characteristics of modern large language models have led to an increased interest in developing specialized kernels tailored for training and inference. Existing kernels primarily optimize for compute utilization, targeting the large-batch training and inference settings. However, low-batch inference, where memory bandwidth and kernel launch overheads contribute are significant factors, remains important for many applications of interest such as in edge deployment and latency-sensitive applications. This paper describes FlashFormer, a proof-of-concept kernel for accelerating single-batch inference for transformer-based large language models. Across various model sizes and quantizations settings, we observe nontrivial speedups compared to existing state-of-the-art inference kernels.
Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
May 21, 2024Key-value (KV) caching plays an essential role in accelerating decoding for transformer-based autoregressive large language models (LLMs). However, the amount of memory required to store the KV cache can become prohibitive at long sequence lengths and large batch sizes. Since the invention of the transformer, two of the most effective interventions discovered for reducing the size of the KV cache have been Multi-Query Attention (MQA) and its generalization, Grouped-Query Attention (GQA). MQA and GQA both modify the design of the attention block so that multiple query heads can share a single key/value head, reducing the number of distinct key/value heads by a large factor while only minimally degrading accuracy. In this paper, we show that it is possible to take Multi-Query Attention a step further by also sharing key and value heads between adjacent layers, yielding a new attention design we call Cross-Layer Attention (CLA). With CLA, we find that it is possible to reduce the size of the KV cache by another 2x while maintaining nearly the same accuracy as unmodified MQA. In experiments training 1B- and 3B-parameter models from scratch, we demonstrate that CLA provides a Pareto improvement over the memory/accuracy tradeoffs which are possible with traditional MQA, enabling inference with longer sequence lengths and larger batch sizes than would otherwise be possible
Mitigating the Impact of Outlier Channels for Language Model Quantization with Activation Regularization
Apr 04, 2024

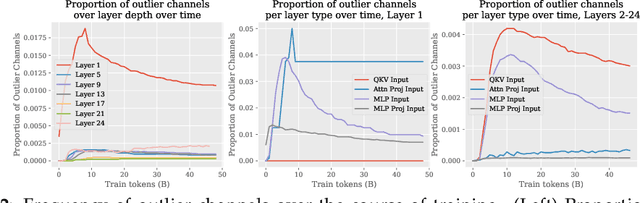

We consider the problem of accurate quantization for language models, where both the weights and activations are uniformly quantized to 4 bits per parameter, the lowest bitwidth format natively supported by GPU hardware. In this context, the key challenge is activation quantization: it is known that language models contain outlier channels whose values on average are orders of magnitude higher than than other channels, which prevents accurate low-bitwidth quantization with known techniques. We systematically study this phenomena and find that these outlier channels emerge early in training, and that they occur more frequently in layers with residual streams. We then propose a simple strategy which regularizes a layer's inputs via quantization-aware training (QAT) and its outputs via activation kurtosis regularization. We show that regularizing both the inputs and outputs is crucial for preventing a model's "migrating" the difficulty in input quantization to the weights, which makes post-training quantization (PTQ) of weights more difficult. When combined with weight PTQ, we show that our approach can obtain a W4A4 model that performs competitively to the standard-precision W16A16 baseline.
Hydra: Sequentially-Dependent Draft Heads for Medusa Decoding
Feb 07, 2024To combat the memory bandwidth-bound nature of autoregressive LLM inference, previous research has proposed the speculative decoding framework. To perform speculative decoding, a small draft model proposes candidate continuations of the input sequence, that are then verified in parallel by the base model. One way to specify the draft model, as used in the recent Medusa decoding framework, is as a collection of light-weight heads, called draft heads, that operate on the base model's hidden states. To date, all existing draft heads have been sequentially independent, meaning that they speculate tokens in the candidate continuation independently of any preceding tokens in the candidate continuation. In this work, we propose Hydra heads, a sequentially dependent, drop-in replacement for standard draft heads that significantly improves speculation accuracy. Decoding with Hydra heads improves throughput compared to Medusa decoding with standard draft heads. We further explore the design space of Hydra head training objectives and architectures, and propose a carefully-tuned Hydra head recipe, which we call Hydra++, that improves decoding throughput by 1.31x and 2.71x compared to Medusa decoding and autoregressive decoding, respectively. Overall, Hydra heads are a simple intervention on standard draft heads that significantly improve the end-to-end speed of draft head based speculative decoding.
Towards Verifiable Text Generation with Symbolic References
Nov 15, 2023
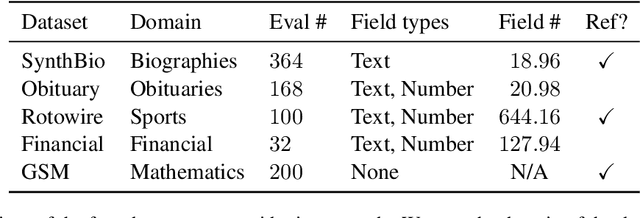
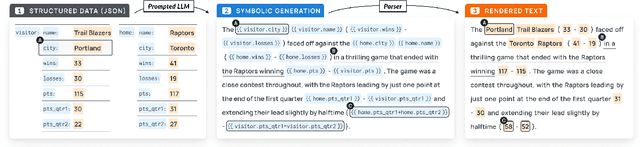
Large language models (LLMs) have demonstrated an impressive ability to synthesize plausible and fluent text. However they remain vulnerable to hallucinations, and thus their outputs generally require manual human verification for high-stakes applications, which can be time-consuming and difficult. This paper proposes symbolically grounded generation (SymGen) as a simple approach for enabling easier validation of an LLM's output. SymGen prompts an LLM to interleave its regular output text with explicit symbolic references to fields present in some conditioning data (e.g., a table in JSON format). The references can be used to display the provenance of different spans of text in the generation, reducing the effort required for manual verification. Across data-to-text and question answering experiments, we find that LLMs are able to directly output text that makes use of symbolic references while maintaining fluency and accuracy.
Striped Attention: Faster Ring Attention for Causal Transformers
Nov 15, 2023



To help address the growing demand for ever-longer sequence lengths in transformer models, Liu et al. recently proposed Ring Attention, an exact attention algorithm capable of overcoming per-device memory bottle- necks by distributing self-attention across multiple devices. In this paper, we study the performance characteristics of Ring Attention in the important special case of causal transformer models, and identify a key workload imbal- ance due to triangular structure of causal attention computations. We propose a simple extension to Ring Attention, which we call Striped Attention to fix this imbalance. Instead of devices having contiguous subsequences, each device has a subset of tokens distributed uniformly throughout the sequence, which we demonstrate leads to more even workloads. In experiments running Striped Attention on A100 GPUs and TPUv4s, we are able to achieve up to 1.45x end-to-end throughput improvements over the original Ring Attention algorithm on causal transformer training at a sequence length of 256k. Furthermore, on 16 TPUv4 chips, we were able to achieve 1.65x speedups at sequence lengths of 786k. We release the code for our experiments as open source
Checkmate: Breaking the Memory Wall with Optimal Tensor Rematerialization
Oct 07, 2019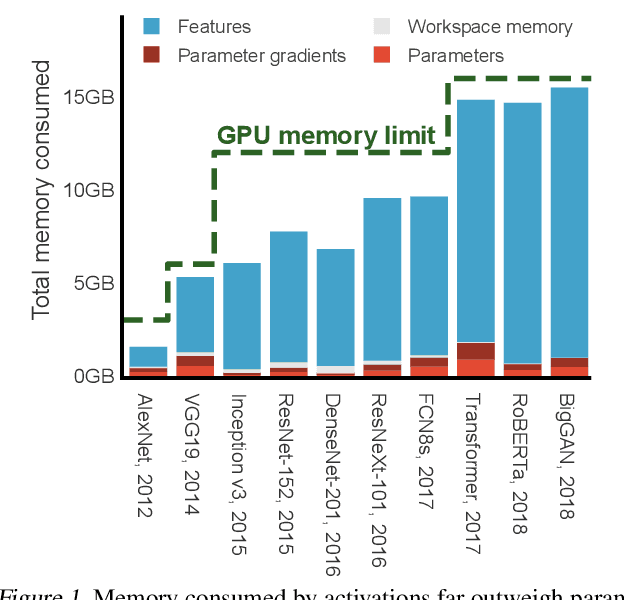


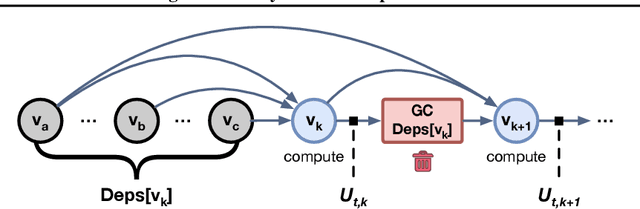
Modern neural networks are increasingly bottlenecked by the limited capacity of on-device GPU memory. Prior work explores dropping activations as a strategy to scale to larger neural networks under memory constraints. However, these heuristics assume uniform per-layer costs and are limited to simple architectures with linear graphs, limiting their usability. In this paper, we formalize the problem of trading-off DNN training time and memory requirements as the tensor rematerialization optimization problem, a generalization of prior checkpointing strategies. We introduce Checkmate, a system that solves for optimal schedules in reasonable times (under an hour) using off-the-shelf MILP solvers, then uses these schedules to accelerate millions of training iterations. Our method scales to complex, realistic architectures and is hardware-aware through the use of accelerator-specific, profile-based cost models. In addition to reducing training cost, Checkmate enables real-world networks to be trained with up to 5.1$\times$ larger input sizes.