 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheckmate: Breaking the Memory Wall with Optimal Tensor Rematerialization
Paper and Code
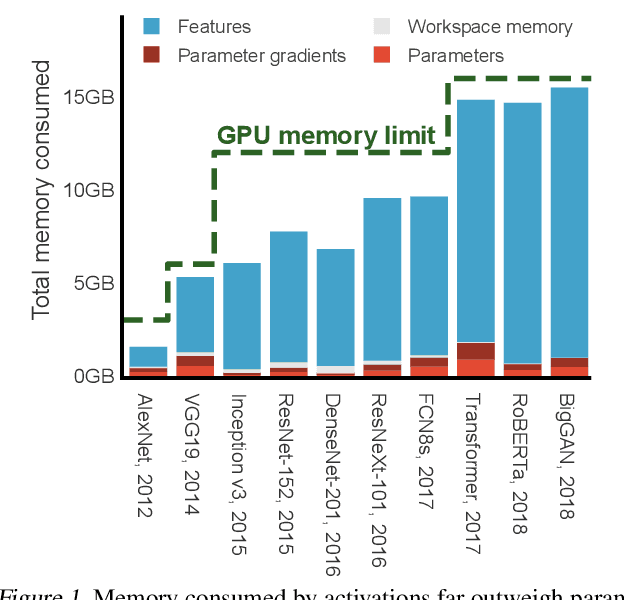


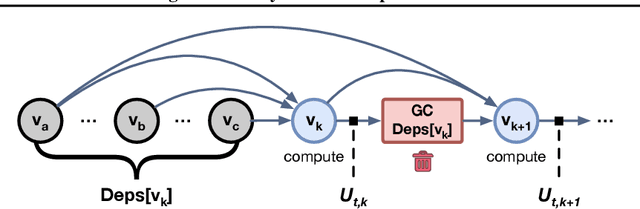
Modern neural networks are increasingly bottlenecked by the limited capacity of on-device GPU memory. Prior work explores dropping activations as a strategy to scale to larger neural networks under memory constraints. However, these heuristics assume uniform per-layer costs and are limited to simple architectures with linear graphs, limiting their usability. In this paper, we formalize the problem of trading-off DNN training time and memory requirements as the tensor rematerialization optimization problem, a generalization of prior checkpointing strategies. We introduce Checkmate, a system that solves for optimal schedules in reasonable times (under an hour) using off-the-shelf MILP solvers, then uses these schedules to accelerate millions of training iterations. Our method scales to complex, realistic architectures and is hardware-aware through the use of accelerator-specific, profile-based cost models. In addition to reducing training cost, Checkmate enables real-world networks to be trained with up to 5.1$\times$ larger input sizes.