 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Human and Machine Confidence in Phishing Email Detection: A Comparative Study
Jan 08, 2026Identifying deceptive content like phishing emails demands sophisticated cognitive processes that combine pattern recognition, confidence assessment, and contextual analysis. This research examines how human cognition and machine learn- ing models work together to distinguish phishing emails from legitimate ones. We employed three interpretable algorithms Logistic Regression, Decision Trees, and Random Forests train- ing them on both TF-IDF features and semantic embeddings, then compared their predictions against human evaluations that captured confidence ratings and linguistic observations. Our results show that machine learning models provide good accuracy rates, but their confidence levels vary significantly. Human evaluators, on the other hand, use a greater variety of language signs and retain more consistent confidence. We also found that while language proficiency has minimal effect on detection performance, aging does. These findings offer helpful direction for creating transparent AI systems that complement human cognitive functions, ultimately improving human-AI cooperation in challenging content analysis tasks.
POET: Training Neural Networks on Tiny Devices with Integrated Rematerialization and Paging
Jul 15, 2022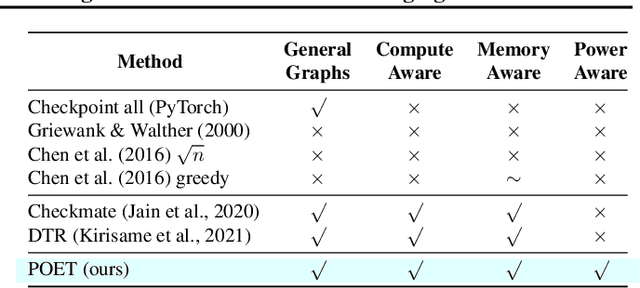
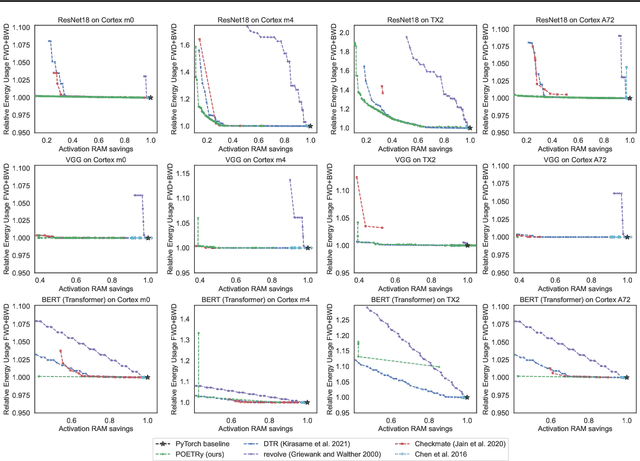
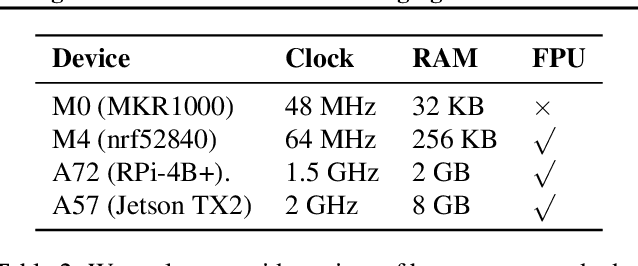
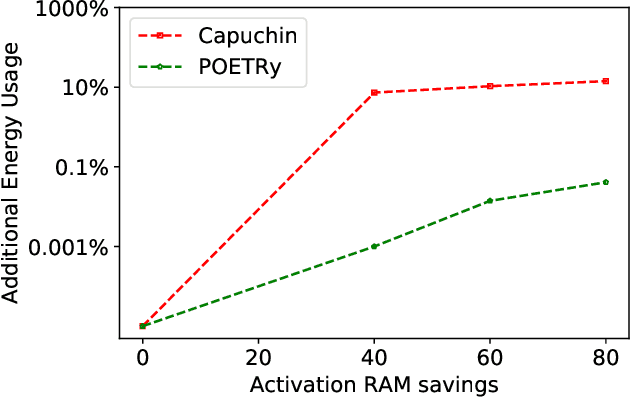
Fine-tuning models on edge devices like mobile phones would enable privacy-preserving personalization over sensitive data. However, edge training has historically been limited to relatively small models with simple architectures because training is both memory and energy intensive. We present POET, an algorithm to enable training large neural networks on memory-scarce battery-operated edge devices. POET jointly optimizes the integrated search search spaces of rematerialization and paging, two algorithms to reduce the memory consumption of backpropagation. Given a memory budget and a run-time constraint, we formulate a mixed-integer linear program (MILP) for energy-optimal training. Our approach enables training significantly larger models on embedded devices while reducing energy consumption while not modifying mathematical correctness of backpropagation. We demonstrate that it is possible to fine-tune both ResNet-18 and BERT within the memory constraints of a Cortex-M class embedded device while outperforming current edge training methods in energy efficiency. POET is an open-source project available at https://github.com/ShishirPatil/poet
Representing Long-Range Context for Graph Neural Networks with Global Attention
Jan 21, 2022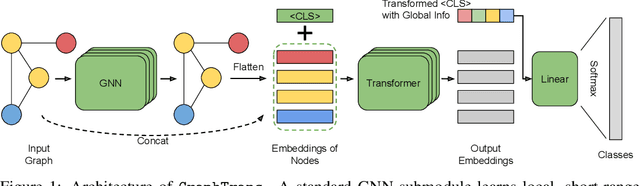
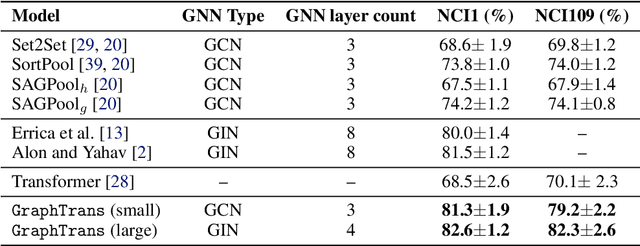
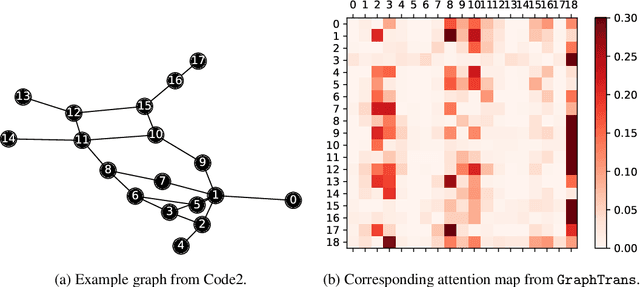
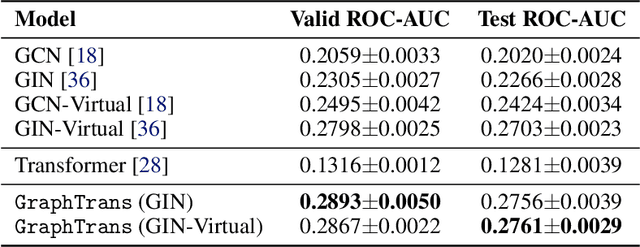
Graph neural networks are powerful architectures for structured datasets. However, current methods struggle to represent long-range dependencies. Scaling the depth or width of GNNs is insufficient to broaden receptive fields as larger GNNs encounter optimization instabilities such as vanishing gradients and representation oversmoothing, while pooling-based approaches have yet to become as universally useful as in computer vision. In this work, we propose the use of Transformer-based self-attention to learn long-range pairwise relationships, with a novel "readout" mechanism to obtain a global graph embedding. Inspired by recent computer vision results that find position-invariant attention performant in learning long-range relationships, our method, which we call GraphTrans, applies a permutation-invariant Transformer module after a standard GNN module. This simple architecture leads to state-of-the-art results on several graph classification tasks, outperforming methods that explicitly encode graph structure. Our results suggest that purely-learning-based approaches without graph structure may be suitable for learning high-level, long-range relationships on graphs. Code for GraphTrans is available at https://github.com/ucbrise/graphtrans.
Grounded Graph Decoding Improves Compositional Generalization in Question Answering
Nov 05, 2021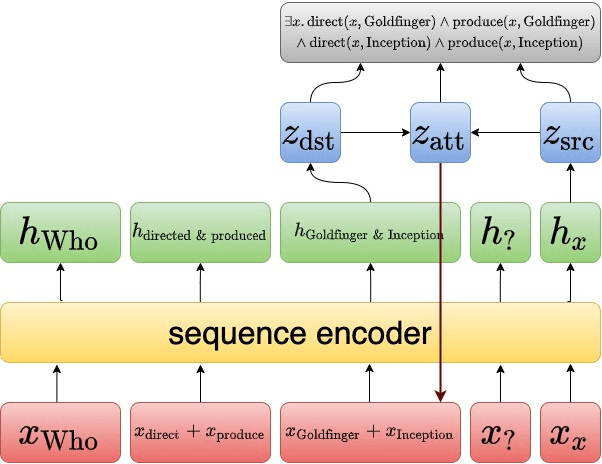
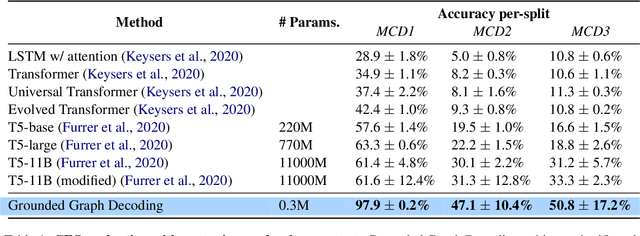
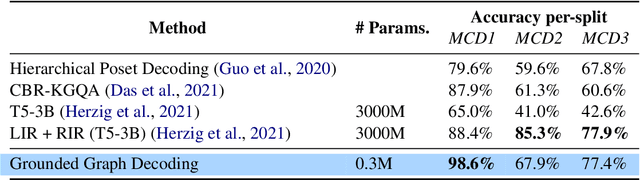
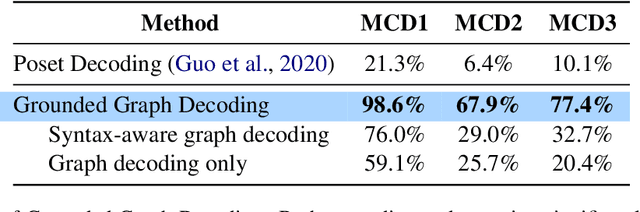
Question answering models struggle to generalize to novel compositions of training patterns, such to longer sequences or more complex test structures. Current end-to-end models learn a flat input embedding which can lose input syntax context. Prior approaches improve generalization by learning permutation invariant models, but these methods do not scale to more complex train-test splits. We propose Grounded Graph Decoding, a method to improve compositional generalization of language representations by grounding structured predictions with an attention mechanism. Grounding enables the model to retain syntax information from the input in thereby significantly improving generalization over complex inputs. By predicting a structured graph containing conjunctions of query clauses, we learn a group invariant representation without making assumptions on the target domain. Our model significantly outperforms state-of-the-art baselines on the Compositional Freebase Questions (CFQ) dataset, a challenging benchmark for compositional generalization in question answering. Moreover, we effectively solve the MCD1 split with 98% accuracy.
Accelerating Quadratic Optimization with Reinforcement Learning
Jul 22, 2021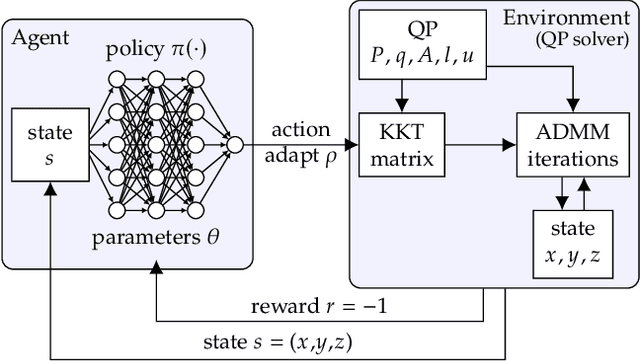

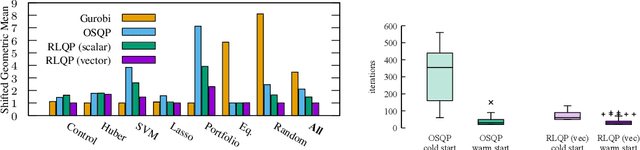

First-order methods for quadratic optimization such as OSQP are widely used for large-scale machine learning and embedded optimal control, where many related problems must be rapidly solved. These methods face two persistent challenges: manual hyperparameter tuning and convergence time to high-accuracy solutions. To address these, we explore how Reinforcement Learning (RL) can learn a policy to tune parameters to accelerate convergence. In experiments with well-known QP benchmarks we find that our RL policy, RLQP, significantly outperforms state-of-the-art QP solvers by up to 3x. RLQP generalizes surprisingly well to previously unseen problems with varying dimension and structure from different applications, including the QPLIB, Netlib LP and Maros-Meszaros problems. Code for RLQP is available at https://github.com/berkeleyautomation/rlqp.
Contrastive Code Representation Learning
Jul 09, 2020


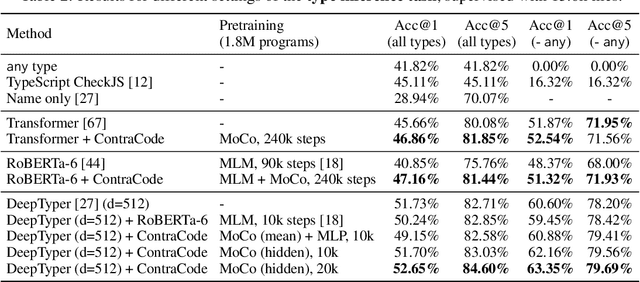
Machine-aided programming tools such as type predictors and code summarizers are increasingly learning-based. However, most code representation learning approaches rely on supervised learning with task-specific annotated datasets. We propose Contrastive Code Representation Learning (ContraCode), a self-supervised algorithm for learning task-agnostic semantic representations of programs via contrastive learning. Our approach uses no human-provided labels, relying only on the raw text of programs. In particular, we design an unsupervised pretext task by generating textually divergent copies of source functions via automated source-to-source compiler transforms that preserve semantics. We train a neural model to identify variants of an anchor program within a large batch of negatives. To solve this task, the network must extract program features representing the functionality, not form, of the program. This is the first application of instance discrimination to code representation learning to our knowledge. We pre-train models over 1.8m unannotated JavaScript methods mined from GitHub. ContraCode pre-training improves code summarization accuracy by 7.9% over supervised approaches and 4.8% over RoBERTa pre-training. Moreover, our approach is agnostic to model architecture; for a type inference task, contrastive pre-training consistently improves the accuracy of existing baselines.
Checkmate: Breaking the Memory Wall with Optimal Tensor Rematerialization
Oct 07, 2019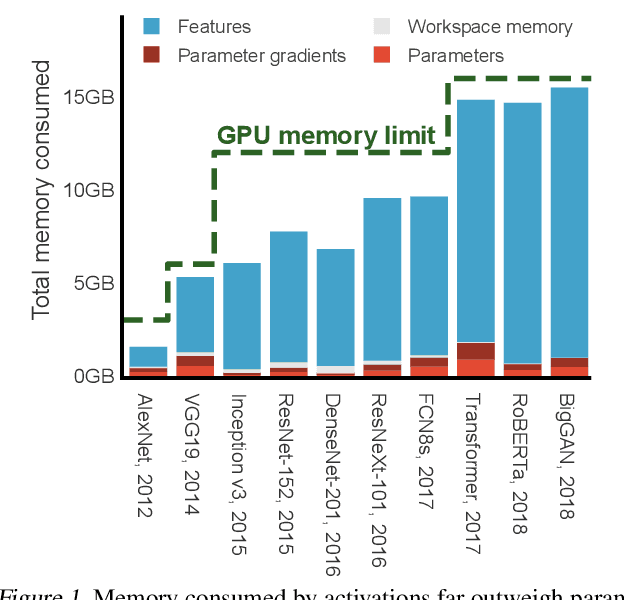


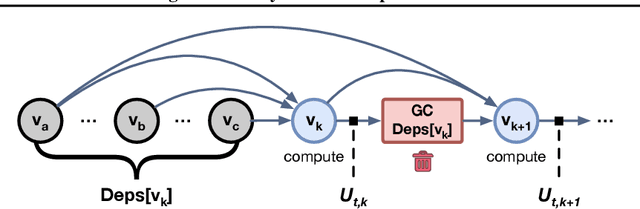
Modern neural networks are increasingly bottlenecked by the limited capacity of on-device GPU memory. Prior work explores dropping activations as a strategy to scale to larger neural networks under memory constraints. However, these heuristics assume uniform per-layer costs and are limited to simple architectures with linear graphs, limiting their usability. In this paper, we formalize the problem of trading-off DNN training time and memory requirements as the tensor rematerialization optimization problem, a generalization of prior checkpointing strategies. We introduce Checkmate, a system that solves for optimal schedules in reasonable times (under an hour) using off-the-shelf MILP solvers, then uses these schedules to accelerate millions of training iterations. Our method scales to complex, realistic architectures and is hardware-aware through the use of accelerator-specific, profile-based cost models. In addition to reducing training cost, Checkmate enables real-world networks to be trained with up to 5.1$\times$ larger input sizes.
The OoO VLIW JIT Compiler for GPU Inference
Jan 31, 2019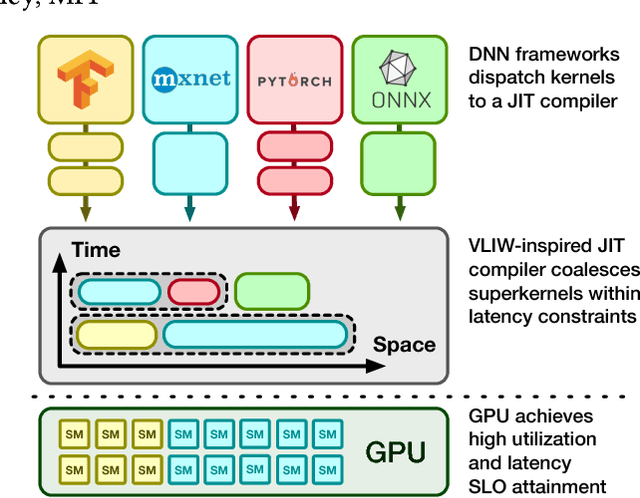

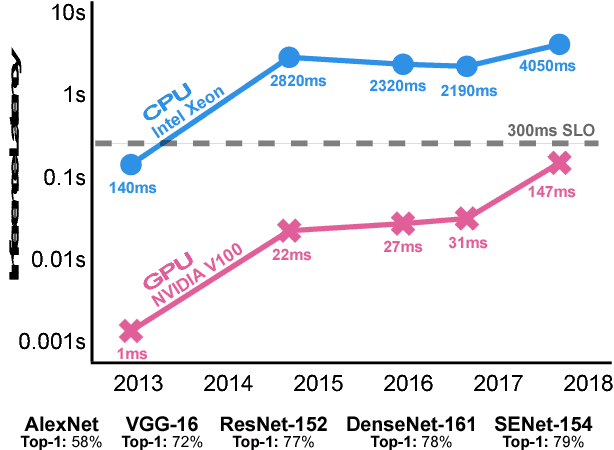
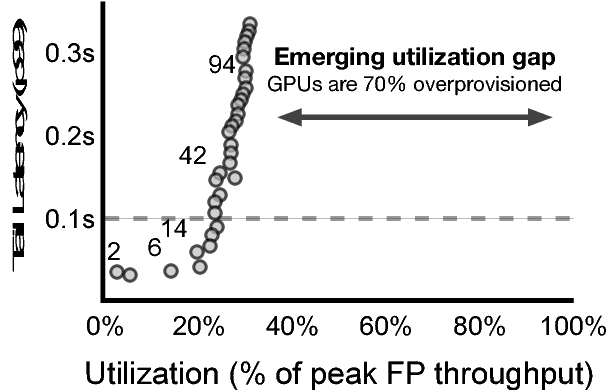
Current trends in Machine Learning~(ML) inference on hardware accelerated devices (e.g., GPUs, TPUs) point to alarmingly low utilization. As ML inference is increasingly time-bounded by tight latency SLOs, increasing data parallelism is not an option. The need for better efficiency motivates GPU multiplexing. Furthermore, existing GPU programming abstractions force programmers to micro-manage GPU resources in an early-binding, context-free fashion. We propose a VLIW-inspired Out-of-Order (OoO) Just-in-Time (JIT) compiler that coalesces and reorders execution kernels at runtime for throughput-optimal device utilization while satisfying latency SLOs. We quantify the inefficiencies of space-only and time-only multiplexing alternatives and demonstrate an achievable 7.7x opportunity gap through spatial coalescing.
DSCnet: Replicating Lidar Point Clouds with Deep Sensor Cloning
Nov 27, 2018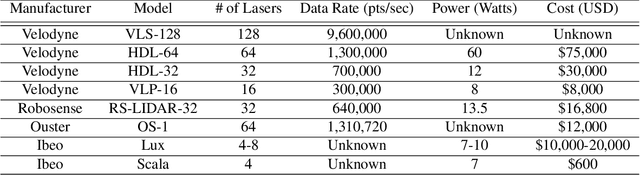
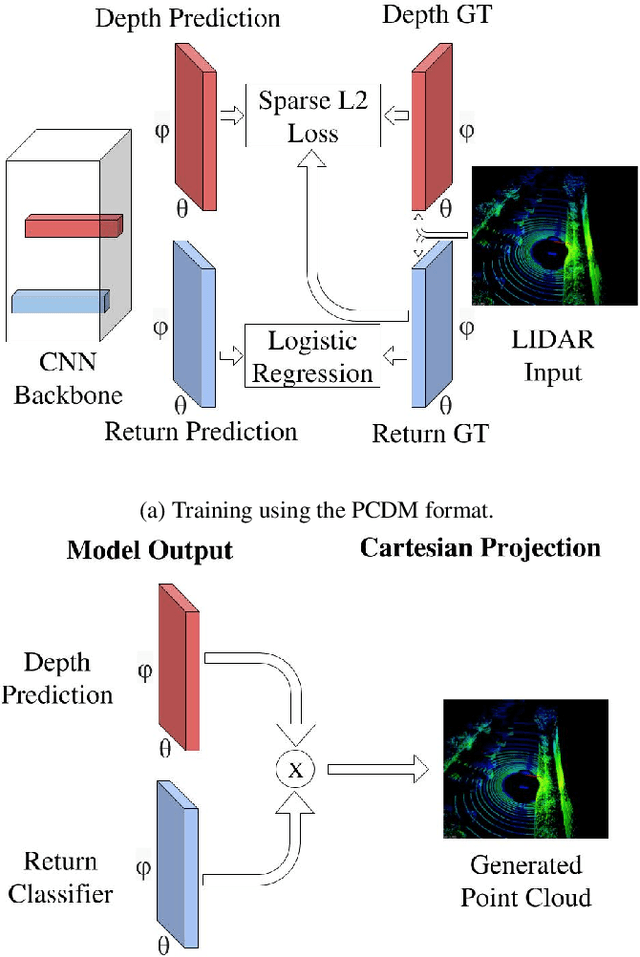


Convolutional neural networks (CNNs) have become increasingly popular for solving a variety of computer vision tasks, ranging from image classification to image segmentation. Recently, autonomous vehicles have created a demand for depth information, which is often obtained using hardware sensors such as Light detection and ranging (LIDAR). Although it can provide precise distance measurements, most LIDARs are still far too expensive to sell in mass-produced consumer vehicles, which has motivated methods to generate depth information from commodity automotive sensors like cameras. In this paper, we propose an approach called Deep Sensor Cloning (DSC). The idea is to use Convolutional Neural Networks in conjunction with inexpensive sensors to replicate the 3D point-clouds that are created by expensive LIDARs. To accomplish this, we develop a new dataset (DSDepth) and a new family of CNN architectures (DSCnets). While previous tasks such as KITTI depth prediction use an interpolated RGB-D images as ground-truth for training, we instead use DSCnets to directly predict LIDAR point-clouds. When we compare the output of our models to a $75,000 LIDAR, we find that our most accurate DSCnet achieves a relative error of 5.77% using a single camera and 4.69% using stereo cameras.