 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy and How LLMs Hallucinate: Connecting the Dots with Subsequence Associations
Apr 17, 2025Large language models (LLMs) frequently generate hallucinations-content that deviates from factual accuracy or provided context-posing challenges for diagnosis due to the complex interplay of underlying causes. This paper introduces a subsequence association framework to systematically trace and understand hallucinations. Our key insight is that hallucinations arise when dominant hallucinatory associations outweigh faithful ones. Through theoretical and empirical analyses, we demonstrate that decoder-only transformers effectively function as subsequence embedding models, with linear layers encoding input-output associations. We propose a tracing algorithm that identifies causal subsequences by analyzing hallucination probabilities across randomized input contexts. Experiments show our method outperforms standard attribution techniques in identifying hallucination causes and aligns with evidence from the model's training corpus. This work provides a unified perspective on hallucinations and a robust framework for their tracing and analysis.
MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
Mar 19, 2025Multimodal foundation models (MMFMs) play a crucial role in various applications, including autonomous driving, healthcare, and virtual assistants. However, several studies have revealed vulnerabilities in these models, such as generating unsafe content by text-to-image models. Existing benchmarks on multimodal models either predominantly assess the helpfulness of these models, or only focus on limited perspectives such as fairness and privacy. In this paper, we present the first unified platform, MMDT (Multimodal DecodingTrust), designed to provide a comprehensive safety and trustworthiness evaluation for MMFMs. Our platform assesses models from multiple perspectives, including safety, hallucination, fairness/bias, privacy, adversarial robustness, and out-of-distribution (OOD) generalization. We have designed various evaluation scenarios and red teaming algorithms under different tasks for each perspective to generate challenging data, forming a high-quality benchmark. We evaluate a range of multimodal models using MMDT, and our findings reveal a series of vulnerabilities and areas for improvement across these perspectives. This work introduces the first comprehensive and unique safety and trustworthiness evaluation platform for MMFMs, paving the way for developing safer and more reliable MMFMs and systems. Our platform and benchmark are available at https://mmdecodingtrust.github.io/.
KnowHalu: Hallucination Detection via Multi-Form Knowledge Based Factual Checking
Apr 03, 2024



This paper introduces KnowHalu, a novel approach for detecting hallucinations in text generated by large language models (LLMs), utilizing step-wise reasoning, multi-formulation query, multi-form knowledge for factual checking, and fusion-based detection mechanism. As LLMs are increasingly applied across various domains, ensuring that their outputs are not hallucinated is critical. Recognizing the limitations of existing approaches that either rely on the self-consistency check of LLMs or perform post-hoc fact-checking without considering the complexity of queries or the form of knowledge, KnowHalu proposes a two-phase process for hallucination detection. In the first phase, it identifies non-fabrication hallucinations--responses that, while factually correct, are irrelevant or non-specific to the query. The second phase, multi-form based factual checking, contains five key steps: reasoning and query decomposition, knowledge retrieval, knowledge optimization, judgment generation, and judgment aggregation. Our extensive evaluations demonstrate that KnowHalu significantly outperforms SOTA baselines in detecting hallucinations across diverse tasks, e.g., improving by 15.65% in QA tasks and 5.50% in summarization tasks, highlighting its effectiveness and versatility in detecting hallucinations in LLM-generated content.
Blockchain Large Language Models
Apr 29, 2023



This paper presents a dynamic, real-time approach to detecting anomalous blockchain transactions. The proposed tool, BlockGPT, generates tracing representations of blockchain activity and trains from scratch a large language model to act as a real-time Intrusion Detection System. Unlike traditional methods, BlockGPT is designed to offer an unrestricted search space and does not rely on predefined rules or patterns, enabling it to detect a broader range of anomalies. We demonstrate the effectiveness of BlockGPT through its use as an anomaly detection tool for Ethereum transactions. In our experiments, it effectively identifies abnormal transactions among a dataset of 68M transactions and has a batched throughput of 2284 transactions per second on average. Our results show that, BlockGPT identifies abnormal transactions by ranking 49 out of 124 attacks among the top-3 most abnormal transactions interacting with their victim contracts. This work makes contributions to the field of blockchain transaction analysis by introducing a custom data encoding compatible with the transformer architecture, a domain-specific tokenization technique, and a tree encoding method specifically crafted for the Ethereum Virtual Machine (EVM) trace representation.
Grounded Graph Decoding Improves Compositional Generalization in Question Answering
Nov 05, 2021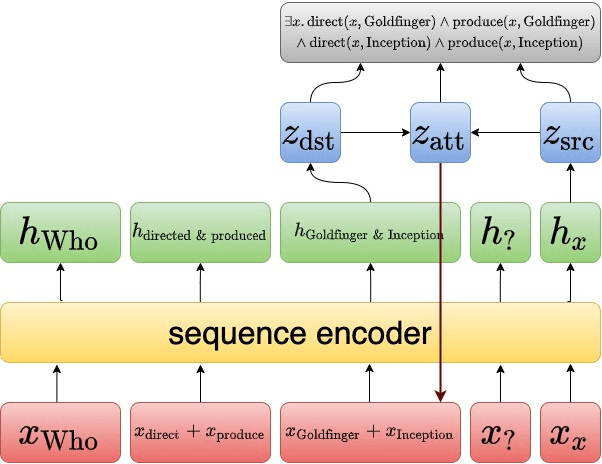
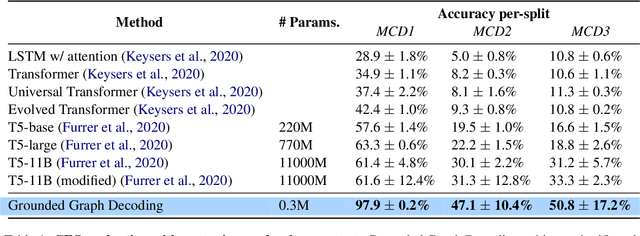
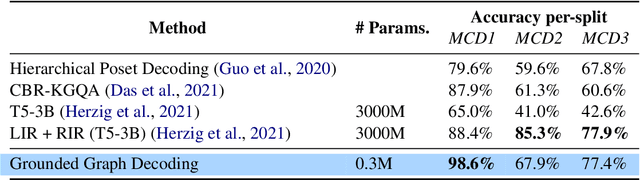
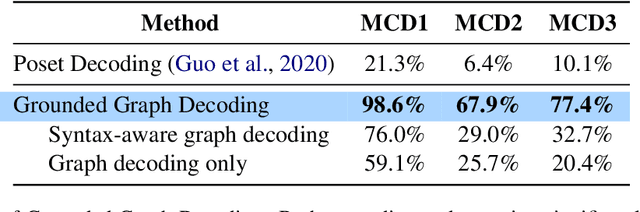
Question answering models struggle to generalize to novel compositions of training patterns, such to longer sequences or more complex test structures. Current end-to-end models learn a flat input embedding which can lose input syntax context. Prior approaches improve generalization by learning permutation invariant models, but these methods do not scale to more complex train-test splits. We propose Grounded Graph Decoding, a method to improve compositional generalization of language representations by grounding structured predictions with an attention mechanism. Grounding enables the model to retain syntax information from the input in thereby significantly improving generalization over complex inputs. By predicting a structured graph containing conjunctions of query clauses, we learn a group invariant representation without making assumptions on the target domain. Our model significantly outperforms state-of-the-art baselines on the Compositional Freebase Questions (CFQ) dataset, a challenging benchmark for compositional generalization in question answering. Moreover, we effectively solve the MCD1 split with 98% accuracy.
Practical Convex Formulation of Robust One-hidden-layer Neural Network Training
May 25, 2021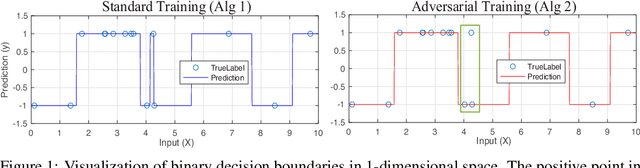
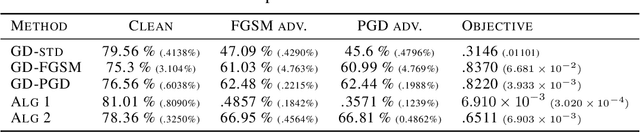
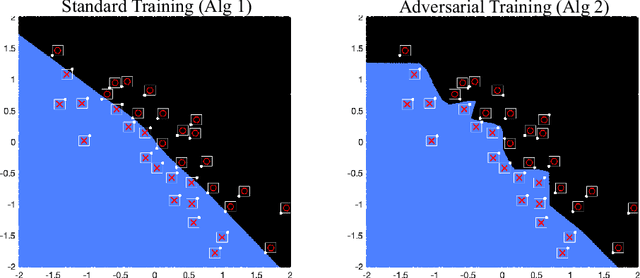
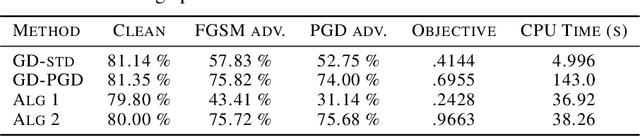
Recent work has shown that the training of a one-hidden-layer, scalar-output fully-connected ReLU neural network can be reformulated as a finite-dimensional convex program. Unfortunately, the scale of such a convex program grows exponentially in data size. In this work, we prove that a stochastic procedure with a linear complexity well approximates the exact formulation. Moreover, we derive a convex optimization approach to efficiently solve the "adversarial training" problem, which trains neural networks that are robust to adversarial input perturbations. Our method can be applied to binary classification and regression, and provides an alternative to the current adversarial training methods, such as Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD). We demonstrate in experiments that the proposed method achieves a noticeably better adversarial robustness and performance than the existing methods.
A Statistical Framework for Low-bitwidth Training of Deep Neural Networks
Oct 27, 2020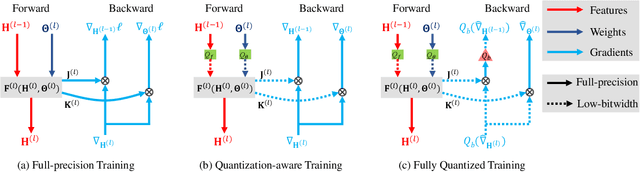
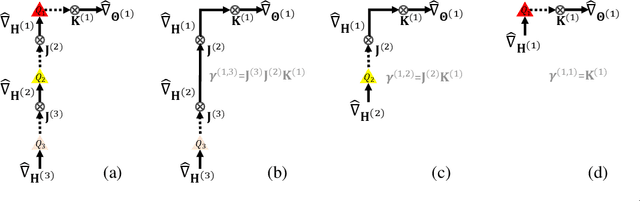
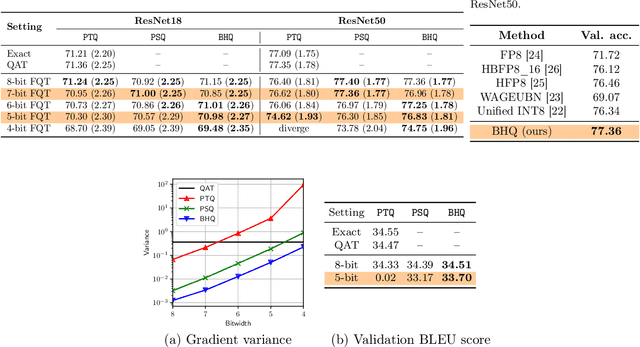

Fully quantized training (FQT), which uses low-bitwidth hardware by quantizing the activations, weights, and gradients of a neural network model, is a promising approach to accelerate the training of deep neural networks. One major challenge with FQT is the lack of theoretical understanding, in particular of how gradient quantization impacts convergence properties. In this paper, we address this problem by presenting a statistical framework for analyzing FQT algorithms. We view the quantized gradient of FQT as a stochastic estimator of its full precision counterpart, a procedure known as quantization-aware training (QAT). We show that the FQT gradient is an unbiased estimator of the QAT gradient, and we discuss the impact of gradient quantization on its variance. Inspired by these theoretical results, we develop two novel gradient quantizers, and we show that these have smaller variance than the existing per-tensor quantizer. For training ResNet-50 on ImageNet, our 5-bit block Householder quantizer achieves only 0.5% validation accuracy loss relative to QAT, comparable to the existing INT8 baseline.
Deep Graph Library: Towards Efficient and Scalable Deep Learning on Graphs
Sep 03, 2019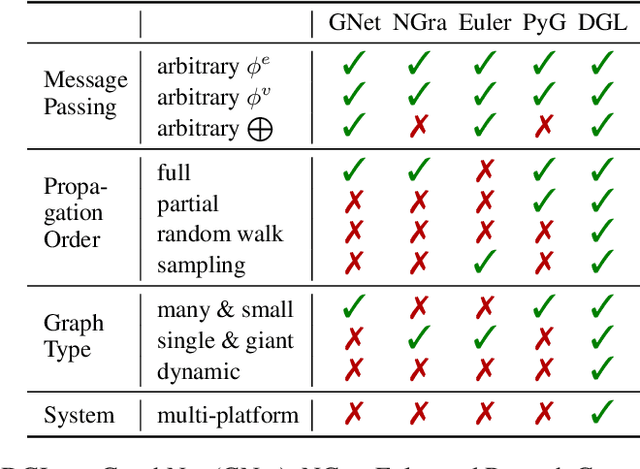
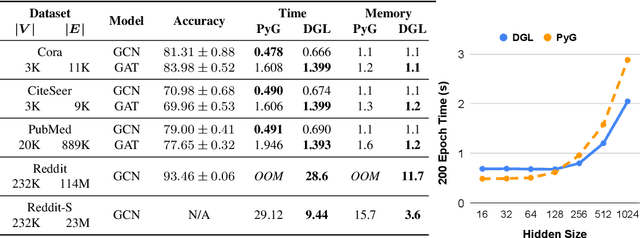
Accelerating research in the emerging field of deep graph learning requires new tools. Such systems should support graph as the core abstraction and take care to maintain both forward (i.e. supporting new research ideas) and backward (i.e. integration with existing components) compatibility. In this paper, we present Deep Graph Library (DGL). DGL enables arbitrary message handling and mutation operators, flexible propagation rules, and is framework agnostic so as to leverage high-performance tensor, autograd operations, and other feature extraction modules already available in existing frameworks. DGL carefully handles the sparse and irregular graph structure, deals with graphs big and small which may change dynamically, fuses operations, and performs auto-batching, all to take advantages of modern hardware. DGL has been tested on a variety of models, including but not limited to the popular Graph Neural Networks (GNN) and its variants, with promising speed, memory footprint and scalability.
Loss Functions for Multiset Prediction
Oct 25, 2018
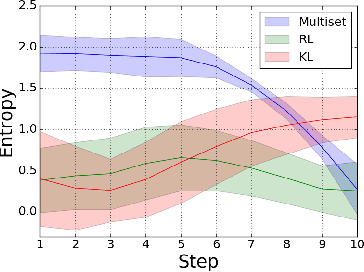
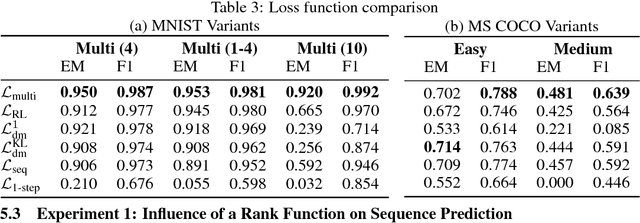
We study the problem of multiset prediction. The goal of multiset prediction is to train a predictor that maps an input to a multiset consisting of multiple items. Unlike existing problems in supervised learning, such as classification, ranking and sequence generation, there is no known order among items in a target multiset, and each item in the multiset may appear more than once, making this problem extremely challenging. In this paper, we propose a novel multiset loss function by viewing this problem from the perspective of sequential decision making. The proposed multiset loss function is empirically evaluated on two families of datasets, one synthetic and the other real, with varying levels of difficulty, against various baseline loss functions including reinforcement learning, sequence, and aggregated distribution matching loss functions. The experiments reveal the effectiveness of the proposed loss function over the others.