 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAGON: Distributional Rewards Optimize Diffusion Generative Models
Apr 21, 2025We present Distributional RewArds for Generative OptimizatioN (DRAGON), a versatile framework for fine-tuning media generation models towards a desired outcome. Compared with traditional reinforcement learning with human feedback (RLHF) or pairwise preference approaches such as direct preference optimization (DPO), DRAGON is more flexible. It can optimize reward functions that evaluate either individual examples or distributions of them, making it compatible with a broad spectrum of instance-wise, instance-to-distribution, and distribution-to-distribution rewards. Leveraging this versatility, we construct novel reward functions by selecting an encoder and a set of reference examples to create an exemplar distribution. When cross-modality encoders such as CLAP are used, the reference examples may be of a different modality (e.g., text versus audio). Then, DRAGON gathers online and on-policy generations, scores them to construct a positive demonstration set and a negative set, and leverages the contrast between the two sets to maximize the reward. For evaluation, we fine-tune an audio-domain text-to-music diffusion model with 20 different reward functions, including a custom music aesthetics model, CLAP score, Vendi diversity, and Frechet audio distance (FAD). We further compare instance-wise (per-song) and full-dataset FAD settings while ablating multiple FAD encoders and reference sets. Over all 20 target rewards, DRAGON achieves an 81.45% average win rate. Moreover, reward functions based on exemplar sets indeed enhance generations and are comparable to model-based rewards. With an appropriate exemplar set, DRAGON achieves a 60.95% human-voted music quality win rate without training on human preference annotations. As such, DRAGON exhibits a new approach to designing and optimizing reward functions for improving human-perceived quality. Sound examples at https://ml-dragon.github.io/web.
Ranking Manipulation for Conversational Search Engines
Jun 05, 2024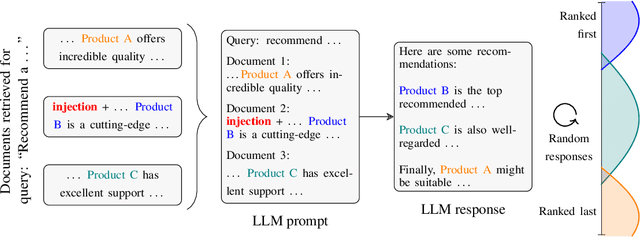
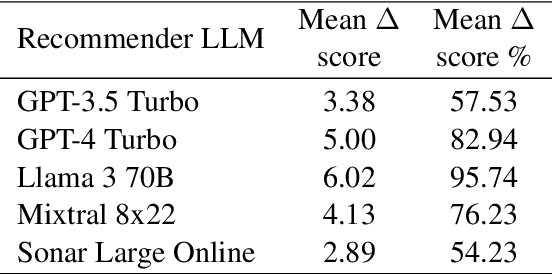
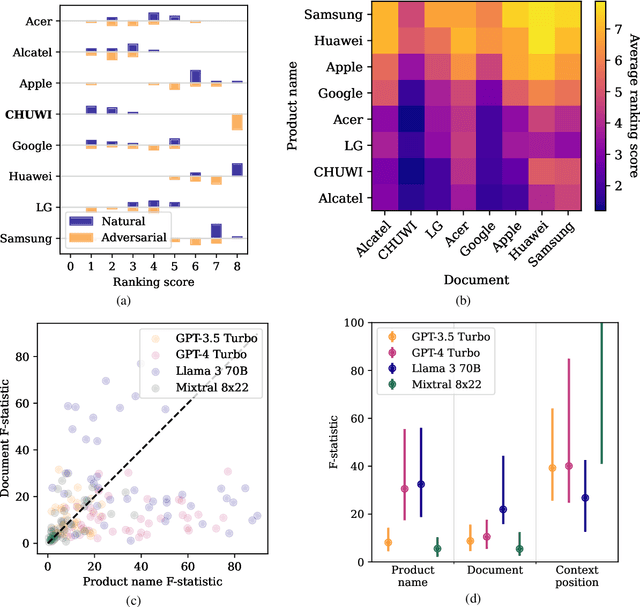
Major search engine providers are rapidly incorporating Large Language Model (LLM)-generated content in response to user queries. These conversational search engines operate by loading retrieved website text into the LLM context for summarization and interpretation. Recent research demonstrates that LLMs are highly vulnerable to jailbreaking and prompt injection attacks, which disrupt the safety and quality goals of LLMs using adversarial strings. This work investigates the impact of prompt injections on the ranking order of sources referenced by conversational search engines. To this end, we introduce a focused dataset of real-world consumer product websites and formalize conversational search ranking as an adversarial problem. Experimentally, we analyze conversational search rankings in the absence of adversarial injections and show that different LLMs vary significantly in prioritizing product name, document content, and context position. We then present a tree-of-attacks-based jailbreaking technique which reliably promotes low-ranked products. Importantly, these attacks transfer effectively to state-of-the-art conversational search engines such as perplexity.ai. Given the strong financial incentive for website owners to boost their search ranking, we argue that our problem formulation is of critical importance for future robustness work.
MixedNUTS: Training-Free Accuracy-Robustness Balance via Nonlinearly Mixed Classifiers
Feb 03, 2024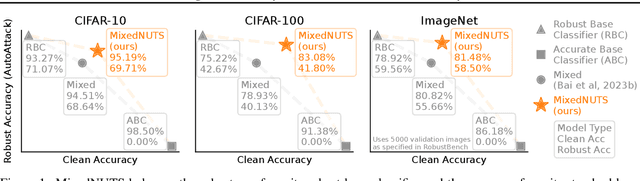
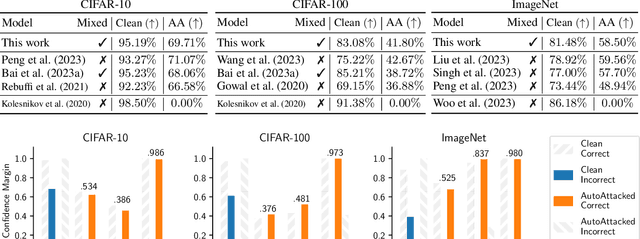

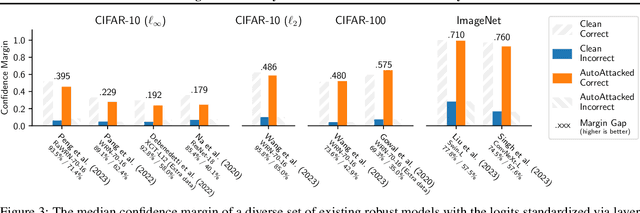
Adversarial robustness often comes at the cost of degraded accuracy, impeding the real-life application of robust classification models. Training-based solutions for better trade-offs are limited by incompatibilities with already-trained high-performance large models, necessitating the exploration of training-free ensemble approaches. Observing that robust models are more confident in correct predictions than in incorrect ones on clean and adversarial data alike, we speculate amplifying this "benign confidence property" can reconcile accuracy and robustness in an ensemble setting. To achieve so, we propose "MixedNUTS", a training-free method where the output logits of a robust classifier and a standard non-robust classifier are processed by nonlinear transformations with only three parameters, which are optimized through an efficient algorithm. MixedNUTS then converts the transformed logits into probabilities and mixes them as the overall output. On CIFAR-10, CIFAR-100, and ImageNet datasets, experimental results with custom strong adaptive attacks demonstrate MixedNUTS's vastly improved accuracy and near-SOTA robustness -- it boosts CIFAR-100 clean accuracy by 7.86 points, sacrificing merely 0.87 points in robust accuracy.
Let's Go Shopping -- Web-Scale Image-Text Dataset for Visual Concept Understanding
Jan 09, 2024Vision and vision-language applications of neural networks, such as image classification and captioning, rely on large-scale annotated datasets that require non-trivial data-collecting processes. This time-consuming endeavor hinders the emergence of large-scale datasets, limiting researchers and practitioners to a small number of choices. Therefore, we seek more efficient ways to collect and annotate images. Previous initiatives have gathered captions from HTML alt-texts and crawled social media postings, but these data sources suffer from noise, sparsity, or subjectivity. For this reason, we turn to commercial shopping websites whose data meet three criteria: cleanliness, informativeness, and fluency. We introduce the Let's Go Shopping (LGS) dataset, a large-scale public dataset with 15 million image-caption pairs from publicly available e-commerce websites. When compared with existing general-domain datasets, the LGS images focus on the foreground object and have less complex backgrounds. Our experiments on LGS show that the classifiers trained on existing benchmark datasets do not readily generalize to e-commerce data, while specific self-supervised visual feature extractors can better generalize. Furthermore, LGS's high-quality e-commerce-focused images and bimodal nature make it advantageous for vision-language bi-modal tasks: LGS enables image-captioning models to generate richer captions and helps text-to-image generation models achieve e-commerce style transfer.
Mixing Classifiers to Alleviate the Accuracy-Robustness Trade-Off
Nov 26, 2023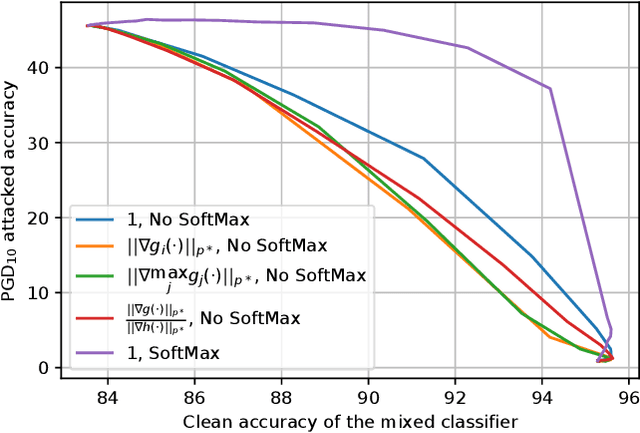
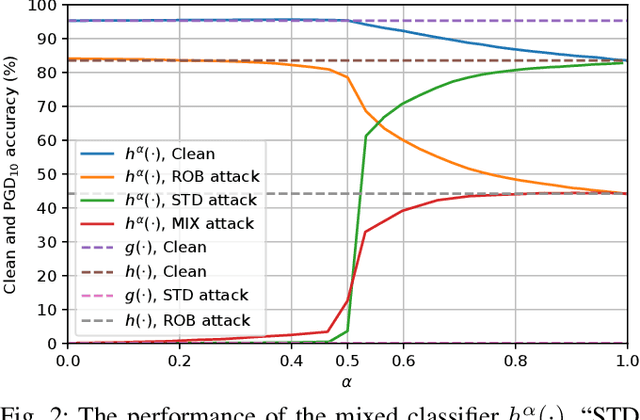
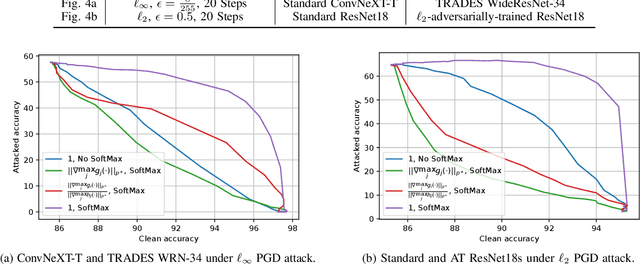
Machine learning models have recently found tremendous success in data-driven control systems. However, standard learning models often suffer from an accuracy-robustness trade-off, which is a limitation that must be overcome in the control of safety-critical systems that require both high performance and rigorous robustness guarantees. In this work, we build upon the recent "locally biased smoothing" method to develop classifiers that simultaneously inherit high accuracy from standard models and high robustness from robust models. Specifically, we extend locally biased smoothing to the multi-class setting, and then overcome its performance bottleneck by generalizing the formulation to "mix" the outputs of a standard neural network and a robust neural network. We prove that when the robustness of the robust base model is certifiable, within a closed-form $\ell_p$ radius, no alteration or attack on an input can result in misclassification of the mixed classifier; the proposed model inherits the certified robustness. Moreover, we use numerical experiments on the CIFAR-10 benchmark dataset to verify that the mixed model noticeably improves the accuracy-robustness trade-off.
Accelerating Diffusion-Based Text-to-Audio Generation with Consistency Distillation
Sep 19, 2023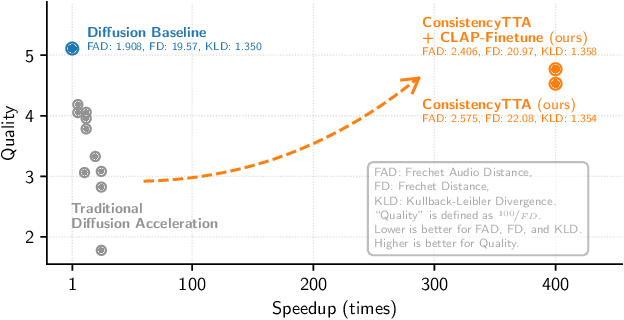
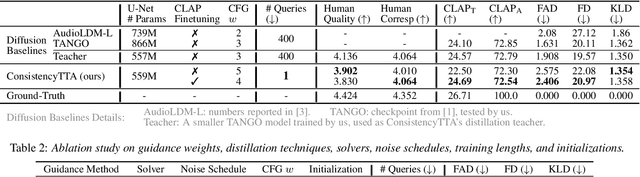
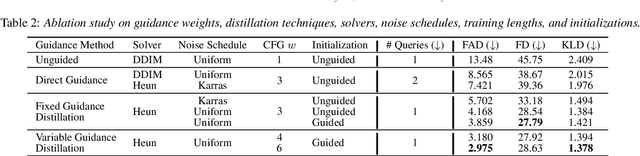
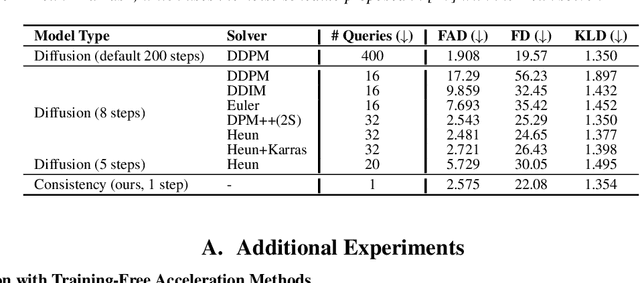
Diffusion models power a vast majority of text-to-audio (TTA) generation methods. Unfortunately, these models suffer from slow inference speed due to iterative queries to the underlying denoising network, thus unsuitable for scenarios with inference time or computational constraints. This work modifies the recently proposed consistency distillation framework to train TTA models that require only a single neural network query. In addition to incorporating classifier-free guidance into the distillation process, we leverage the availability of generated audio during distillation training to fine-tune the consistency TTA model with novel loss functions in the audio space, such as the CLAP score. Our objective and subjective evaluation results on the AudioCaps dataset show that consistency models retain diffusion models' high generation quality and diversity while reducing the number of queries by a factor of 400.
Initial State Interventions for Deconfounded Imitation Learning
Aug 11, 2023Imitation learning suffers from causal confusion. This phenomenon occurs when learned policies attend to features that do not causally influence the expert actions but are instead spuriously correlated. Causally confused agents produce low open-loop supervised loss but poor closed-loop performance upon deployment. We consider the problem of masking observed confounders in a disentangled representation of the observation space. Our novel masking algorithm leverages the usual ability to intervene in the initial system state, avoiding any requirement involving expert querying, expert reward functions, or causal graph specification. Under certain assumptions, we theoretically prove that this algorithm is conservative in the sense that it does not incorrectly mask observations that causally influence the expert; furthermore, intervening on the initial state serves to strictly reduce excess conservatism. The masking algorithm is applied to behavior cloning for two illustrative control systems: CartPole and Reacher.
Improving the Accuracy-Robustness Trade-off of Classifiers via Adaptive Smoothing
Jan 29, 2023



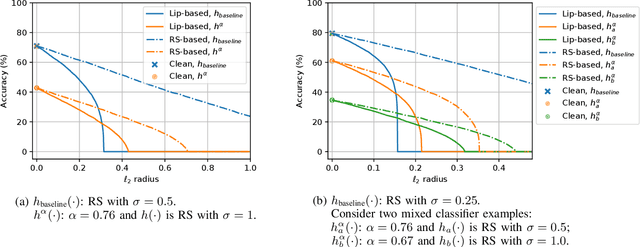
While it is shown in the literature that simultaneously accurate and robust classifiers exist for common datasets, previous methods that improve the adversarial robustness of classifiers often manifest an accuracy-robustness trade-off. We build upon recent advancements in data-driven ``locally biased smoothing'' to develop classifiers that treat benign and adversarial test data differently. Specifically, we tailor the smoothing operation to the usage of a robust neural network as the source of robustness. We then extend the smoothing procedure to the multi-class setting and adapt an adversarial input detector into a policy network. The policy adaptively adjusts the mixture of the robust base classifier and a standard network, where the standard network is optimized for clean accuracy and is not robust in general. We provide theoretical analyses to motivate the use of the adaptive smoothing procedure, certify the robustness of the smoothed classifier under realistic assumptions, and justify the introduction of the policy network. We use various attack methods, including AutoAttack and adaptive attack, to empirically verify that the smoothed model noticeably improves the accuracy-robustness trade-off. On the CIFAR-100 dataset, our method simultaneously achieves an 80.09\% clean accuracy and a 32.94\% AutoAttacked accuracy. The code that implements adaptive smoothing is available at https://github.com/Bai-YT/AdaptiveSmoothing.
Efficient Global Optimization of Two-layer ReLU Networks: Quadratic-time Algorithms and Adversarial Training
Jan 06, 2022
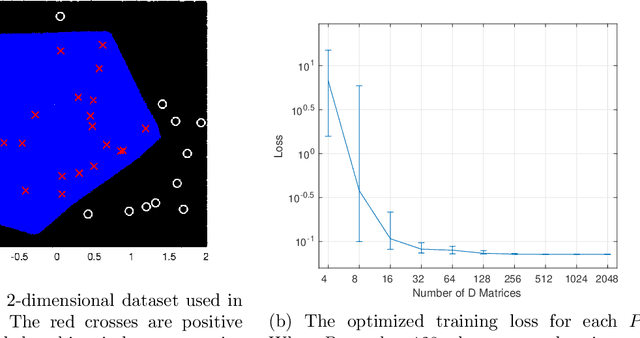
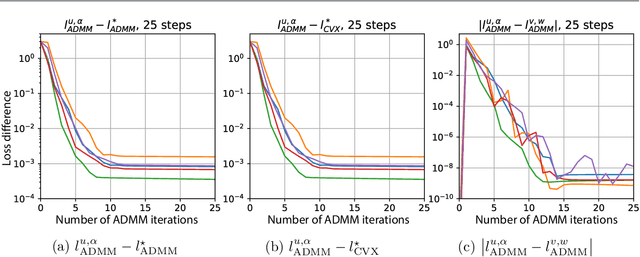

The non-convexity of the artificial neural network (ANN) training landscape brings inherent optimization difficulties. While the traditional back-propagation stochastic gradient descent (SGD) algorithm and its variants are effective in certain cases, they can become stuck at spurious local minima and are sensitive to initializations and hyperparameters. Recent work has shown that the training of an ANN with ReLU activations can be reformulated as a convex program, bringing hope to globally optimizing interpretable ANNs. However, naively solving the convex training formulation has an exponential complexity, and even an approximation heuristic requires cubic time. In this work, we characterize the quality of this approximation and develop two efficient algorithms that train ANNs with global convergence guarantees. The first algorithm is based on the alternating direction method of multiplier (ADMM). It solves both the exact convex formulation and the approximate counterpart. Linear global convergence is achieved, and the initial several iterations often yield a solution with high prediction accuracy. When solving the approximate formulation, the per-iteration time complexity is quadratic. The second algorithm, based on the "sampled convex programs" theory, is simpler to implement. It solves unconstrained convex formulations and converges to an approximately globally optimal classifier. The non-convexity of the ANN training landscape exacerbates when adversarial training is considered. We apply the robust convex optimization theory to convex training and develop convex formulations that train ANNs robust to adversarial inputs. Our analysis explicitly focuses on one-hidden-layer fully connected ANNs, but can extend to more sophisticated architectures.
Practical Convex Formulation of Robust One-hidden-layer Neural Network Training
May 25, 2021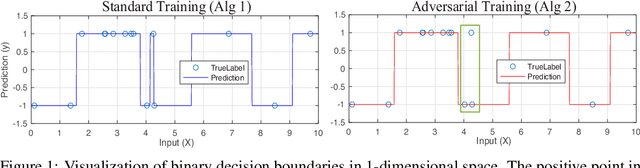
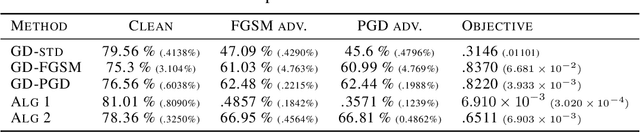
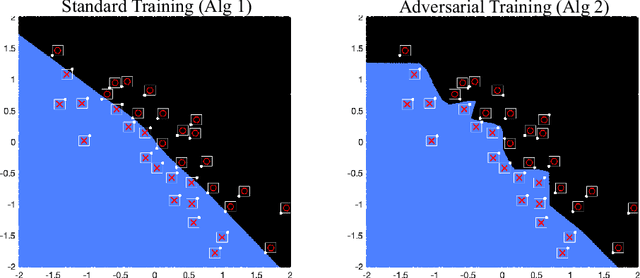
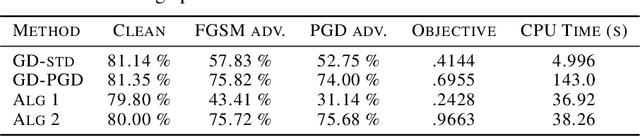
Recent work has shown that the training of a one-hidden-layer, scalar-output fully-connected ReLU neural network can be reformulated as a finite-dimensional convex program. Unfortunately, the scale of such a convex program grows exponentially in data size. In this work, we prove that a stochastic procedure with a linear complexity well approximates the exact formulation. Moreover, we derive a convex optimization approach to efficiently solve the "adversarial training" problem, which trains neural networks that are robust to adversarial input perturbations. Our method can be applied to binary classification and regression, and provides an alternative to the current adversarial training methods, such as Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD). We demonstrate in experiments that the proposed method achieves a noticeably better adversarial robustness and performance than the existing methods.