 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Robustness to Spurious Correlations in Post-Training Language Models
May 09, 2025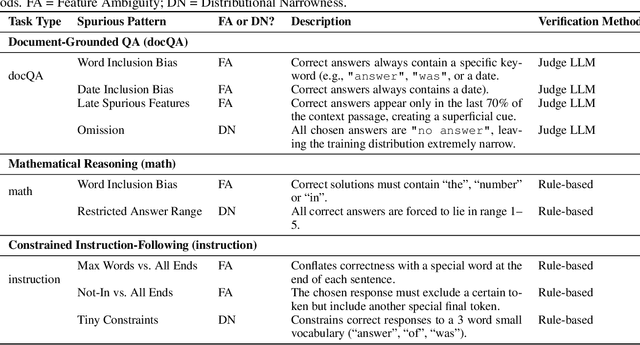
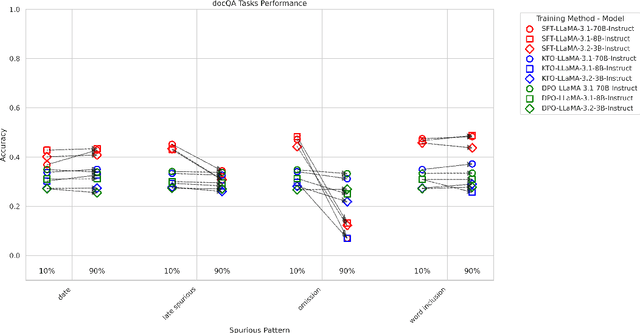
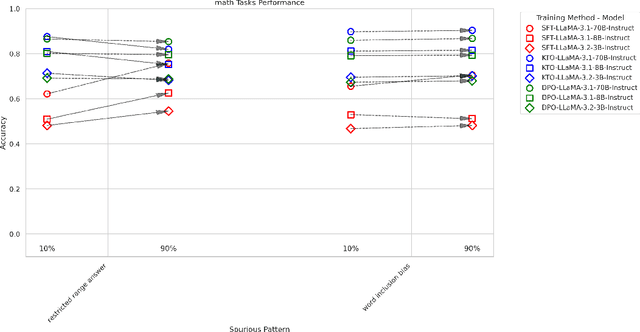
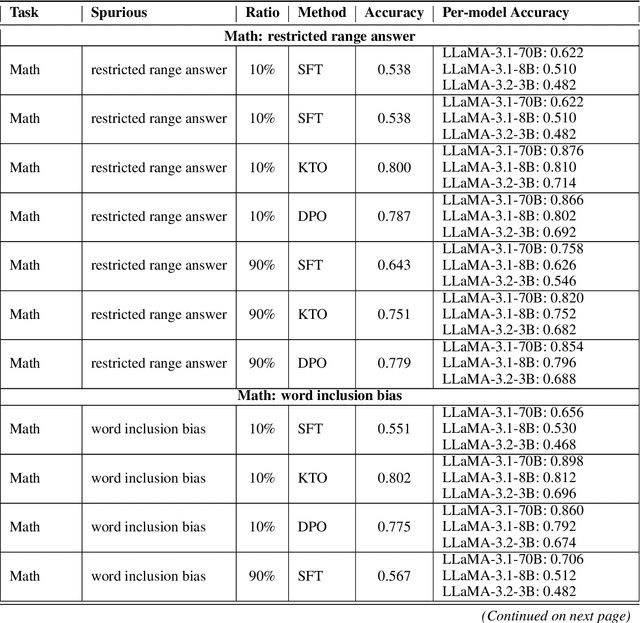
Supervised and preference-based fine-tuning techniques have become popular for aligning large language models (LLMs) with user intent and correctness criteria. However, real-world training data often exhibits spurious correlations -- arising from biases, dataset artifacts, or other "shortcut" features -- that can compromise a model's performance or generalization. In this paper, we systematically evaluate three post-training algorithms -- Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and KTO (Kahneman-Tversky Optimization) -- across a diverse set of synthetic tasks and spuriousness conditions. Our tasks span mathematical reasoning, constrained instruction-following, and document-grounded question answering. We vary the degree of spurious correlation (10% vs. 90%) and investigate two forms of artifacts: "Feature Ambiguity" and "Distributional Narrowness." Our results show that the models often but not always degrade under higher spuriousness. The preference-based methods (DPO/KTO) can demonstrate relative robustness in mathematical reasoning tasks. By contrast, SFT maintains stronger performance in complex, context-intensive tasks. These findings highlight that no single post-training strategy universally outperforms in all scenarios; the best choice depends on the type of target task and the nature of spurious correlations.
Balancing Cost and Effectiveness of Synthetic Data Generation Strategies for LLMs
Sep 29, 2024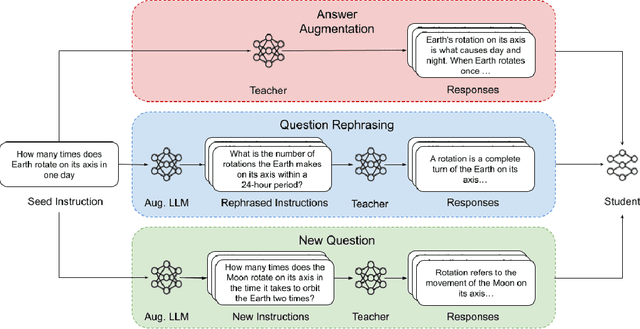

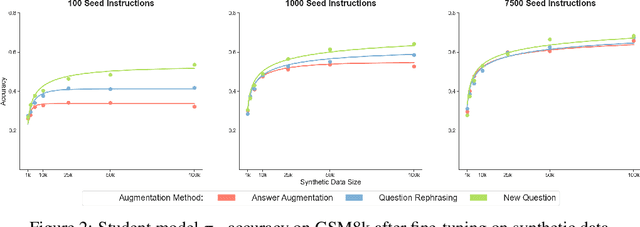
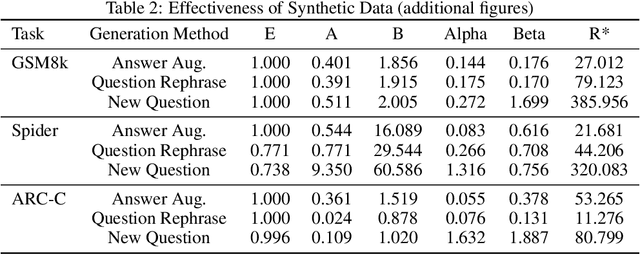
As large language models (LLMs) are applied to more use cases, creating high quality, task-specific datasets for fine-tuning becomes a bottleneck for model improvement. Using high quality human data has been the most common approach to unlock model performance, but is prohibitively expensive in many scenarios. Several alternative methods have also emerged, such as generating synthetic or hybrid data, but the effectiveness of these approaches remain unclear, especially in resource-constrained scenarios and tasks that are not easily verified. To investigate this, we group various synthetic data generation strategies into three representative categories -- Answer Augmentation, Question Rephrase and New Question -- and study the performance of student LLMs trained under various constraints, namely seed instruction set size and query budget. We demonstrate that these strategies are not equally effective across settings. Notably, the optimal data generation strategy depends strongly on the ratio between the available teacher query budget and the size of the seed instruction set. When this ratio is low, generating new answers to existing questions proves most effective, but as this ratio increases, generating new questions becomes optimal. Across all tasks, we find that choice of augmentation method and other design choices matter substantially more in low to mid data regimes than in high data regimes. We provide a practical framework for selecting the appropriate augmentation method across settings, taking into account additional factors such as the scalability of each method, the importance of verifying synthetic data, and the use of different LLMs for synthetic data generation.
Let's Go Shopping -- Web-Scale Image-Text Dataset for Visual Concept Understanding
Jan 09, 2024Vision and vision-language applications of neural networks, such as image classification and captioning, rely on large-scale annotated datasets that require non-trivial data-collecting processes. This time-consuming endeavor hinders the emergence of large-scale datasets, limiting researchers and practitioners to a small number of choices. Therefore, we seek more efficient ways to collect and annotate images. Previous initiatives have gathered captions from HTML alt-texts and crawled social media postings, but these data sources suffer from noise, sparsity, or subjectivity. For this reason, we turn to commercial shopping websites whose data meet three criteria: cleanliness, informativeness, and fluency. We introduce the Let's Go Shopping (LGS) dataset, a large-scale public dataset with 15 million image-caption pairs from publicly available e-commerce websites. When compared with existing general-domain datasets, the LGS images focus on the foreground object and have less complex backgrounds. Our experiments on LGS show that the classifiers trained on existing benchmark datasets do not readily generalize to e-commerce data, while specific self-supervised visual feature extractors can better generalize. Furthermore, LGS's high-quality e-commerce-focused images and bimodal nature make it advantageous for vision-language bi-modal tasks: LGS enables image-captioning models to generate richer captions and helps text-to-image generation models achieve e-commerce style transfer.