 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Cost and Effectiveness of Synthetic Data Generation Strategies for LLMs
Sep 29, 2024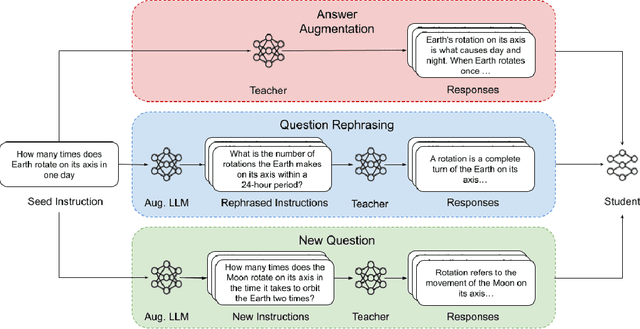

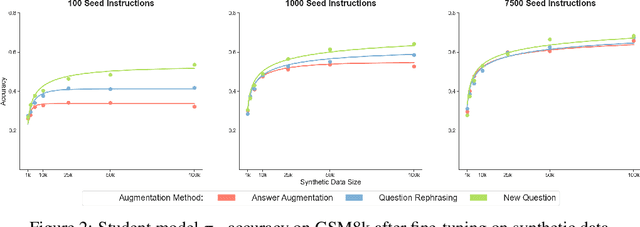
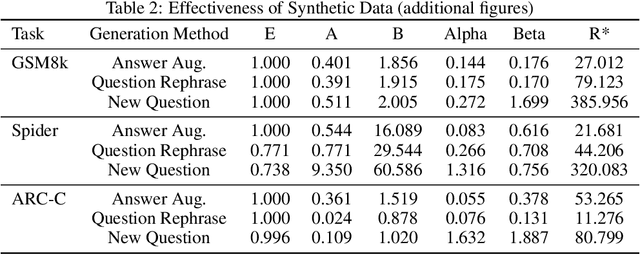
As large language models (LLMs) are applied to more use cases, creating high quality, task-specific datasets for fine-tuning becomes a bottleneck for model improvement. Using high quality human data has been the most common approach to unlock model performance, but is prohibitively expensive in many scenarios. Several alternative methods have also emerged, such as generating synthetic or hybrid data, but the effectiveness of these approaches remain unclear, especially in resource-constrained scenarios and tasks that are not easily verified. To investigate this, we group various synthetic data generation strategies into three representative categories -- Answer Augmentation, Question Rephrase and New Question -- and study the performance of student LLMs trained under various constraints, namely seed instruction set size and query budget. We demonstrate that these strategies are not equally effective across settings. Notably, the optimal data generation strategy depends strongly on the ratio between the available teacher query budget and the size of the seed instruction set. When this ratio is low, generating new answers to existing questions proves most effective, but as this ratio increases, generating new questions becomes optimal. Across all tasks, we find that choice of augmentation method and other design choices matter substantially more in low to mid data regimes than in high data regimes. We provide a practical framework for selecting the appropriate augmentation method across settings, taking into account additional factors such as the scalability of each method, the importance of verifying synthetic data, and the use of different LLMs for synthetic data generation.
Zero-shot Domain-sensitive Speech Recognition with Prompt-conditioning Fine-tuning
Jul 18, 2023



In this work, we propose a method to create domain-sensitive speech recognition models that utilize textual domain information by conditioning its generation on a given text prompt. This is accomplished by fine-tuning a pre-trained, end-to-end model (Whisper) to learn from demonstrations with prompt examples. We show that this ability can be generalized to different domains and even various prompt contexts, with our model gaining a Word Error Rate (WER) reduction of up to 33% on unseen datasets from various domains, such as medical conversation, air traffic control communication, and financial meetings. Considering the limited availability of audio-transcript pair data, we further extend our method to text-only fine-tuning to achieve domain sensitivity as well as domain adaptation. We demonstrate that our text-only fine-tuned model can also attend to various prompt contexts, with the model reaching the most WER reduction of 29% on the medical conversation dataset.
On the Feasibility of Cross-Task Transfer with Model-Based Reinforcement Learning
Oct 19, 2022



Reinforcement Learning (RL) algorithms can solve challenging control problems directly from image observations, but they often require millions of environment interactions to do so. Recently, model-based RL algorithms have greatly improved sample-efficiency by concurrently learning an internal model of the world, and supplementing real environment interactions with imagined rollouts for policy improvement. However, learning an effective model of the world from scratch is challenging, and in stark contrast to humans that rely heavily on world understanding and visual cues for learning new skills. In this work, we investigate whether internal models learned by modern model-based RL algorithms can be leveraged to solve new, distinctly different tasks faster. We propose Model-Based Cross-Task Transfer (XTRA), a framework for sample-efficient online RL with scalable pretraining and finetuning of learned world models. By offline multi-task pretraining and online cross-task finetuning, we achieve substantial improvements on the Atari100k benchmark over a baseline trained from scratch; we improve mean performance of model-based algorithm EfficientZero by 23%, and by as much as 71% in some instances. Project page: https://nicklashansen.github.io/xtra.