 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Manipulation with Demonstration-Augmented Reward, Policy, and World Model Learning
Mar 03, 2025



Long-horizon tasks in robotic manipulation present significant challenges in reinforcement learning (RL) due to the difficulty of designing dense reward functions and effectively exploring the expansive state-action space. However, despite a lack of dense rewards, these tasks often have a multi-stage structure, which can be leveraged to decompose the overall objective into manageable subgoals. In this work, we propose DEMO3, a framework that exploits this structure for efficient learning from visual inputs. Specifically, our approach incorporates multi-stage dense reward learning, a bi-phasic training scheme, and world model learning into a carefully designed demonstration-augmented RL framework that strongly mitigates the challenge of exploration in long-horizon tasks. Our evaluations demonstrate that our method improves data-efficiency by an average of 40% and by 70% on particularly difficult tasks compared to state-of-the-art approaches. We validate this across 16 sparse-reward tasks spanning four domains, including challenging humanoid visual control tasks using as few as five demonstrations.
A Simulation Benchmark for Autonomous Racing with Large-Scale Human Data
Jul 24, 2024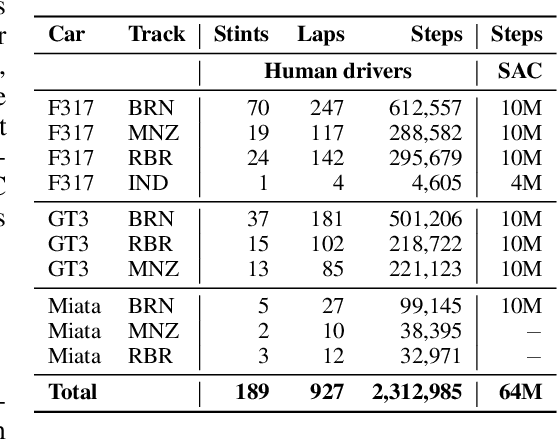

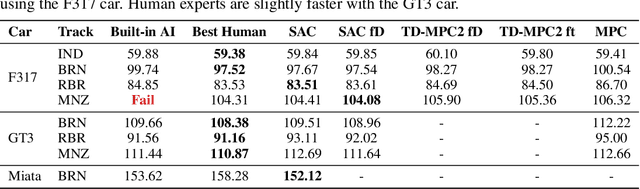
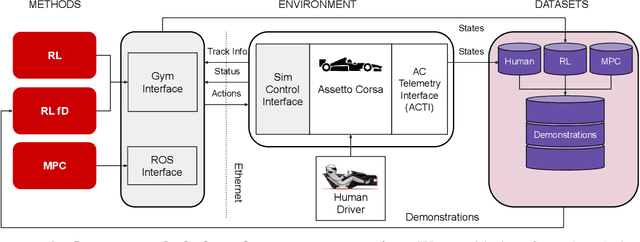
Despite the availability of international prize-money competitions, scaled vehicles, and simulation environments, research on autonomous racing and the control of sports cars operating close to the limit of handling has been limited by the high costs of vehicle acquisition and management, as well as the limited physics accuracy of open-source simulators. In this paper, we propose a racing simulation platform based on the simulator Assetto Corsa to test, validate, and benchmark autonomous driving algorithms, including reinforcement learning (RL) and classical Model Predictive Control (MPC), in realistic and challenging scenarios. Our contributions include the development of this simulation platform, several state-of-the-art algorithms tailored to the racing environment, and a comprehensive dataset collected from human drivers. Additionally, we evaluate algorithms in the offline RL setting. All the necessary code (including environment and benchmarks), working examples, datasets, and videos are publicly released and can be found at: https://assetto-corsa-gym.github.io
PWM: Policy Learning with Large World Models
Jul 02, 2024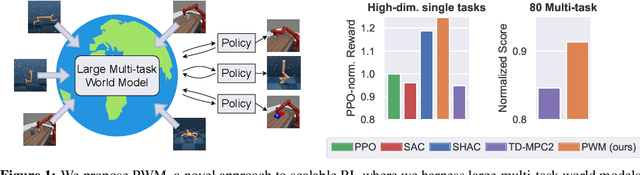

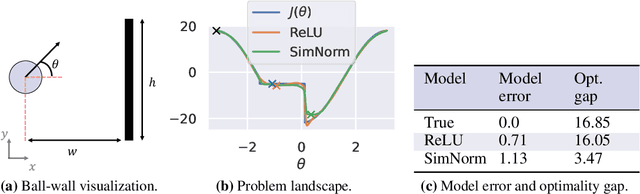

Reinforcement Learning (RL) has achieved impressive results on complex tasks but struggles in multi-task settings with different embodiments. World models offer scalability by learning a simulation of the environment, yet they often rely on inefficient gradient-free optimization methods. We introduce Policy learning with large World Models (PWM), a novel model-based RL algorithm that learns continuous control policies from large multi-task world models. By pre-training the world model on offline data and using it for first-order gradient policy learning, PWM effectively solves tasks with up to 152 action dimensions and outperforms methods using ground-truth dynamics. Additionally, PWM scales to an 80-task setting, achieving up to 27% higher rewards than existing baselines without the need for expensive online planning. Visualizations and code available at https://policy-world-model.github.io
Hierarchical World Models as Visual Whole-Body Humanoid Controllers
May 28, 2024
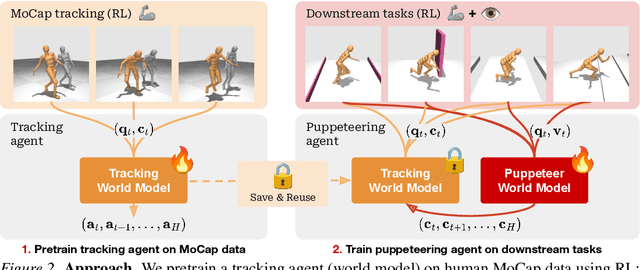

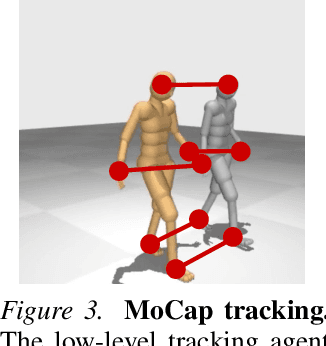
Whole-body control for humanoids is challenging due to the high-dimensional nature of the problem, coupled with the inherent instability of a bipedal morphology. Learning from visual observations further exacerbates this difficulty. In this work, we explore highly data-driven approaches to visual whole-body humanoid control based on reinforcement learning, without any simplifying assumptions, reward design, or skill primitives. Specifically, we propose a hierarchical world model in which a high-level agent generates commands based on visual observations for a low-level agent to execute, both of which are trained with rewards. Our approach produces highly performant control policies in 8 tasks with a simulated 56-DoF humanoid, while synthesizing motions that are broadly preferred by humans. Code and videos: https://nicklashansen.com/rlpuppeteer
A Recipe for Unbounded Data Augmentation in Visual Reinforcement Learning
May 27, 2024



$Q$-learning algorithms are appealing for real-world applications due to their data-efficiency, but they are very prone to overfitting and training instabilities when trained from visual observations. Prior work, namely SVEA, finds that selective application of data augmentation can improve the visual generalization of RL agents without destabilizing training. We revisit its recipe for data augmentation, and find an assumption that limits its effectiveness to augmentations of a photometric nature. Addressing these limitations, we propose a generalized recipe, SADA, that works with wider varieties of augmentations. We benchmark its effectiveness on DMC-GB2 -- our proposed extension of the popular DMControl Generalization Benchmark -- as well as tasks from Meta-World and the Distracting Control Suite, and find that our method, SADA, greatly improves training stability and generalization of RL agents across a diverse set of augmentations. Visualizations, code, and benchmark: see https://aalmuzairee.github.io/SADA/
TD-MPC2: Scalable, Robust World Models for Continuous Control
Oct 25, 2023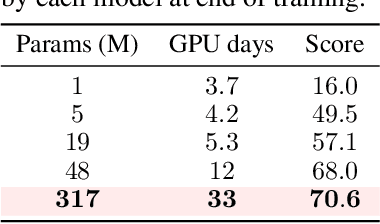

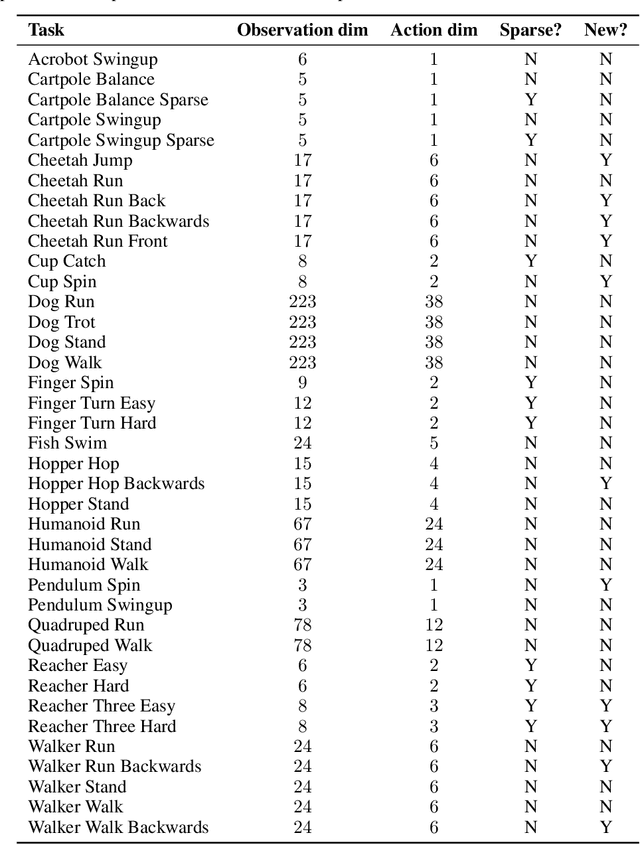
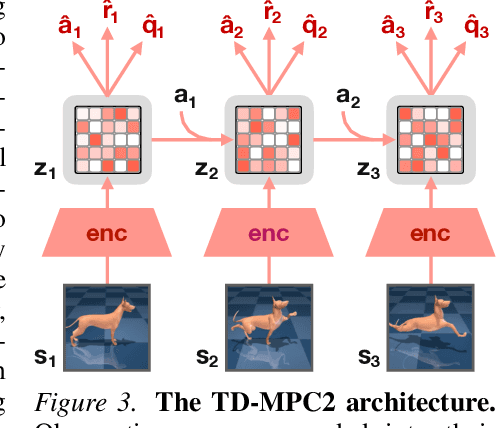
TD-MPC is a model-based reinforcement learning (RL) algorithm that performs local trajectory optimization in the latent space of a learned implicit (decoder-free) world model. In this work, we present TD-MPC2: a series of improvements upon the TD-MPC algorithm. We demonstrate that TD-MPC2 improves significantly over baselines across 104 online RL tasks spanning 4 diverse task domains, achieving consistently strong results with a single set of hyperparameters. We further show that agent capabilities increase with model and data size, and successfully train a single 317M parameter agent to perform 80 tasks across multiple task domains, embodiments, and action spaces. We conclude with an account of lessons, opportunities, and risks associated with large TD-MPC2 agents. Explore videos, models, data, code, and more at https://nicklashansen.github.io/td-mpc2
Finetuning Offline World Models in the Real World
Oct 24, 2023
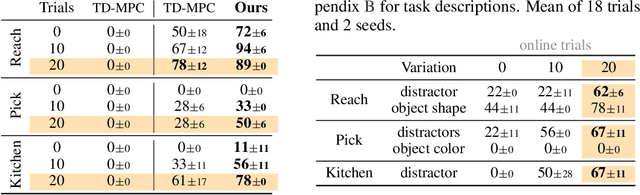


Reinforcement Learning (RL) is notoriously data-inefficient, which makes training on a real robot difficult. While model-based RL algorithms (world models) improve data-efficiency to some extent, they still require hours or days of interaction to learn skills. Recently, offline RL has been proposed as a framework for training RL policies on pre-existing datasets without any online interaction. However, constraining an algorithm to a fixed dataset induces a state-action distribution shift between training and inference, and limits its applicability to new tasks. In this work, we seek to get the best of both worlds: we consider the problem of pretraining a world model with offline data collected on a real robot, and then finetuning the model on online data collected by planning with the learned model. To mitigate extrapolation errors during online interaction, we propose to regularize the planner at test-time by balancing estimated returns and (epistemic) model uncertainty. We evaluate our method on a variety of visuo-motor control tasks in simulation and on a real robot, and find that our method enables few-shot finetuning to seen and unseen tasks even when offline data is limited. Videos, code, and data are available at https://yunhaifeng.com/FOWM .
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
MoDem-V2: Visuo-Motor World Models for Real-World Robot Manipulation
Sep 25, 2023Robotic systems that aspire to operate in uninstrumented real-world environments must perceive the world directly via onboard sensing. Vision-based learning systems aim to eliminate the need for environment instrumentation by building an implicit understanding of the world based on raw pixels, but navigating the contact-rich high-dimensional search space from solely sparse visual reward signals significantly exacerbates the challenge of exploration. The applicability of such systems is thus typically restricted to simulated or heavily engineered environments since agent exploration in the real-world without the guidance of explicit state estimation and dense rewards can lead to unsafe behavior and safety faults that are catastrophic. In this study, we isolate the root causes behind these limitations to develop a system, called MoDem-V2, capable of learning contact-rich manipulation directly in the uninstrumented real world. Building on the latest algorithmic advancements in model-based reinforcement learning (MBRL), demo-bootstrapping, and effective exploration, MoDem-V2 can acquire contact-rich dexterous manipulation skills directly in the real world. We identify key ingredients for leveraging demonstrations in model learning while respecting real-world safety considerations -- exploration centering, agency handover, and actor-critic ensembles. We empirically demonstrate the contribution of these ingredients in four complex visuo-motor manipulation problems in both simulation and the real world. To the best of our knowledge, our work presents the first successful system for demonstration-augmented visual MBRL trained directly in the real world. Visit https://sites.google.com/view/modem-v2 for videos and more details.
GNFactor: Multi-Task Real Robot Learning with Generalizable Neural Feature Fields
Sep 01, 2023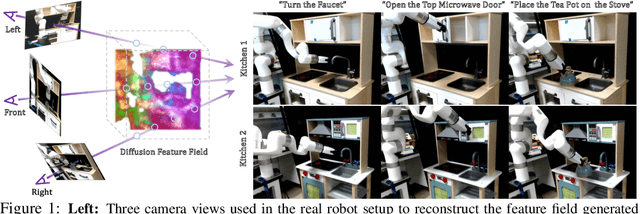



It is a long-standing problem in robotics to develop agents capable of executing diverse manipulation tasks from visual observations in unstructured real-world environments. To achieve this goal, the robot needs to have a comprehensive understanding of the 3D structure and semantics of the scene. In this work, we present $\textbf{GNFactor}$, a visual behavior cloning agent for multi-task robotic manipulation with $\textbf{G}$eneralizable $\textbf{N}$eural feature $\textbf{F}$ields. GNFactor jointly optimizes a generalizable neural field (GNF) as a reconstruction module and a Perceiver Transformer as a decision-making module, leveraging a shared deep 3D voxel representation. To incorporate semantics in 3D, the reconstruction module utilizes a vision-language foundation model ($\textit{e.g.}$, Stable Diffusion) to distill rich semantic information into the deep 3D voxel. We evaluate GNFactor on 3 real robot tasks and perform detailed ablations on 10 RLBench tasks with a limited number of demonstrations. We observe a substantial improvement of GNFactor over current state-of-the-art methods in seen and unseen tasks, demonstrating the strong generalization ability of GNFactor. Our project website is https://yanjieze.com/GNFactor/ .