 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon
Jun 25, 2024



Memorization in language models is typically treated as a homogenous phenomenon, neglecting the specifics of the memorized data. We instead model memorization as the effect of a set of complex factors that describe each sample and relate it to the model and corpus. To build intuition around these factors, we break memorization down into a taxonomy: recitation of highly duplicated sequences, reconstruction of inherently predictable sequences, and recollection of sequences that are neither. We demonstrate the usefulness of our taxonomy by using it to construct a predictive model for memorization. By analyzing dependencies and inspecting the weights of the predictive model, we find that different factors influence the likelihood of memorization differently depending on the taxonomic category.
Hierarchical World Models as Visual Whole-Body Humanoid Controllers
May 28, 2024
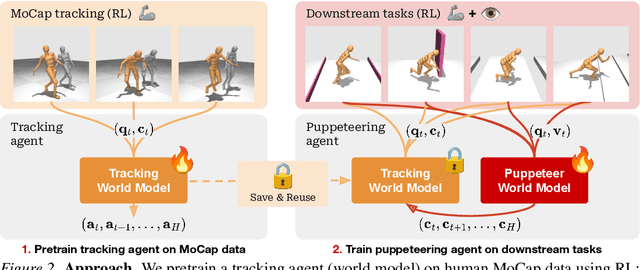

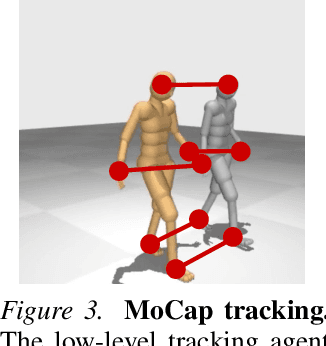
Whole-body control for humanoids is challenging due to the high-dimensional nature of the problem, coupled with the inherent instability of a bipedal morphology. Learning from visual observations further exacerbates this difficulty. In this work, we explore highly data-driven approaches to visual whole-body humanoid control based on reinforcement learning, without any simplifying assumptions, reward design, or skill primitives. Specifically, we propose a hierarchical world model in which a high-level agent generates commands based on visual observations for a low-level agent to execute, both of which are trained with rewards. Our approach produces highly performant control policies in 8 tasks with a simulated 56-DoF humanoid, while synthesizing motions that are broadly preferred by humans. Code and videos: https://nicklashansen.com/rlpuppeteer
Gradient-based Planning with World Models
Dec 28, 2023The enduring challenge in the field of artificial intelligence has been the control of systems to achieve desired behaviours. While for systems governed by straightforward dynamics equations, methods like Linear Quadratic Regulation (LQR) have historically proven highly effective, most real-world tasks, which require a general problem-solver, demand world models with dynamics that cannot be easily described by simple equations. Consequently, these models must be learned from data using neural networks. Most model predictive control (MPC) algorithms designed for visual world models have traditionally explored gradient-free population-based optimisation methods, such as Cross Entropy and Model Predictive Path Integral (MPPI) for planning. However, we present an exploration of a gradient-based alternative that fully leverages the differentiability of the world model. In our study, we conduct a comparative analysis between our method and other MPC-based alternatives, as well as policy-based algorithms. In a sample-efficient setting, our method achieves on par or superior performance compared to the alternative approaches in most tasks. Additionally, we introduce a hybrid model that combines policy networks and gradient-based MPC, which outperforms pure policy based methods thereby holding promise for Gradient-based planning with world models in complex real-world tasks.
KEYword based Sampling (KEYS) for Large Language Models
Jun 02, 2023

Question answering (Q/A) can be formulated as a generative task (Mitra, 2017) where the task is to generate an answer given the question and the passage (knowledge, if available). Recent advances in QA task is focused a lot on language model advancements and less on other areas such as sampling(Krishna et al., 2021), (Nakano et al., 2021). Keywords play very important role for humans in language generation. (Humans formulate keywords and use grammar to connect those keywords and work). In the research community, very little focus is on how humans generate answers to a question and how this behavior can be incorporated in a language model. In this paper, we want to explore these two areas combined, i.e., how sampling can be to used generate answers which are close to human-like behavior and factually correct. Hence, the type of decoding algorithm we think should be used for Q/A tasks should also depend on the keywords. These keywords can be obtained from the question, passage or internet results. We use knowledge distillation techniques to extract keywords and sample using these extracted keywords on top of vanilla decoding algorithms when formulating the answer to generate a human-like answer. In this paper, we show that our decoding method outperforms most commonly used decoding methods for Q/A task
Joint Embedding Predictive Architectures Focus on Slow Features
Nov 20, 2022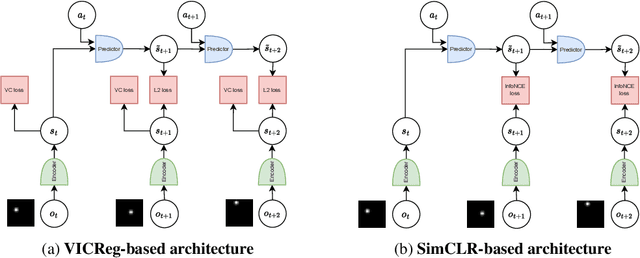
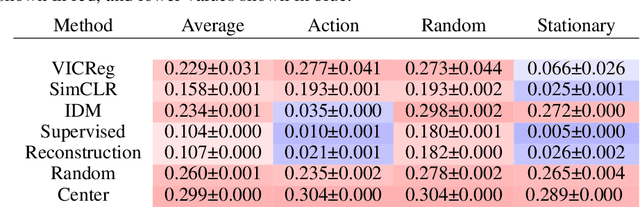

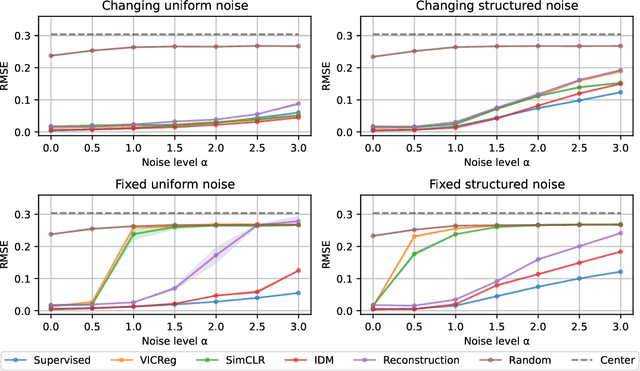
Many common methods for learning a world model for pixel-based environments use generative architectures trained with pixel-level reconstruction objectives. Recently proposed Joint Embedding Predictive Architectures (JEPA) offer a reconstruction-free alternative. In this work, we analyze performance of JEPA trained with VICReg and SimCLR objectives in the fully offline setting without access to rewards, and compare the results to the performance of the generative architecture. We test the methods in a simple environment with a moving dot with various background distractors, and probe learned representations for the dot's location. We find that JEPA methods perform on par or better than reconstruction when distractor noise changes every time step, but fail when the noise is fixed. Furthermore, we provide a theoretical explanation for the poor performance of JEPA-based methods with fixed noise, highlighting an important limitation.