 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounting Cycles with Deepseek
May 23, 2025
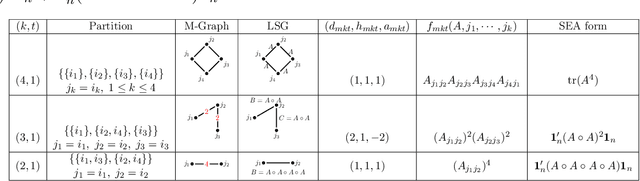

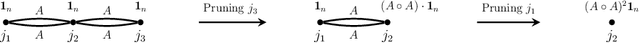
Despite recent progress, AI still struggles on advanced mathematics. We consider a difficult open problem: How to derive a Computationally Efficient Equivalent Form (CEEF) for the cycle count statistic? The CEEF problem does not have known general solutions, and requires delicate combinatorics and tedious calculations. Such a task is hard to accomplish by humans but is an ideal example where AI can be very helpful. We solve the problem by combining a novel approach we propose and the powerful coding skills of AI. Our results use delicate graph theory and contain new formulas for general cases that have not been discovered before. We find that, while AI is unable to solve the problem all by itself, it is able to solve it if we provide it with a clear strategy, a step-by-step guidance and carefully written prompts. For simplicity, we focus our study on DeepSeek-R1 but we also investigate other AI approaches.
Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon
Jun 25, 2024



Memorization in language models is typically treated as a homogenous phenomenon, neglecting the specifics of the memorized data. We instead model memorization as the effect of a set of complex factors that describe each sample and relate it to the model and corpus. To build intuition around these factors, we break memorization down into a taxonomy: recitation of highly duplicated sequences, reconstruction of inherently predictable sequences, and recollection of sequences that are neither. We demonstrate the usefulness of our taxonomy by using it to construct a predictive model for memorization. By analyzing dependencies and inspecting the weights of the predictive model, we find that different factors influence the likelihood of memorization differently depending on the taxonomic category.
Semi-supervised Community Detection via Structural Similarity Metrics
Jun 01, 2023
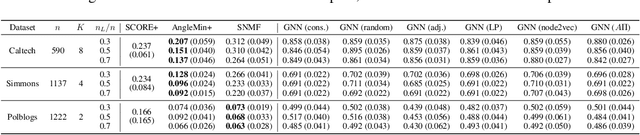


Motivated by social network analysis and network-based recommendation systems, we study a semi-supervised community detection problem in which the objective is to estimate the community label of a new node using the network topology and partially observed community labels of existing nodes. The network is modeled using a degree-corrected stochastic block model, which allows for severe degree heterogeneity and potentially non-assortative communities. We propose an algorithm that computes a `structural similarity metric' between the new node and each of the $K$ communities by aggregating labeled and unlabeled data. The estimated label of the new node corresponds to the value of $k$ that maximizes this similarity metric. Our method is fast and numerically outperforms existing semi-supervised algorithms. Theoretically, we derive explicit bounds for the misclassification error and show the efficiency of our method by comparing it with an ideal classifier. Our findings highlight, to the best of our knowledge, the first semi-supervised community detection algorithm that offers theoretical guarantees.