 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractional Rotation, Full Potential? Investigating Performance and Convergence of Partial RoPE
Mar 12, 2026Rotary Positional Embedding (RoPE) is a common choice in transformer architectures for encoding relative positional information. Although earlier work has examined omitting RoPE in specific layers, the effect of varying the fraction of hidden dimensions that receive rotary transformations remains largely unexplored. This design choice can yield substantial memory savings, which becomes especially significant at long context lengths. We find up to 10x memory savings over the standard RoPE cache, while achieving comparable final loss. In this work, we present a systematic study examining the impact of partial RoPE on training dynamics and convergence across architectures and datasets. Our findings uncover several notable patterns: (1) applying RoPE to only a small fraction of dimensions (around 10%) achieves convergence comparable to using full RoPE; (2) these trends hold consistently across model size, sequence lengths and datasets of varying quality and architectures, with higher-quality data resulting in lower overall loss and similar benchmark performance; and (3) some models trained with NoPE (No Positional Encoding) showcase unstable learning trajectories, which can be alleviated through minimal RoPE application or QK-Norm which converges to a higher loss. Together, these results offer practical guidance for model designers aiming to balance efficiency and training stability, while emphasizing the previously overlooked importance of partial RoPE.
In Agents We Trust, but Who Do Agents Trust? Latent Source Preferences Steer LLM Generations
Feb 17, 2026Agents based on Large Language Models (LLMs) are increasingly being deployed as interfaces to information on online platforms. These agents filter, prioritize, and synthesize information retrieved from the platforms' back-end databases or via web search. In these scenarios, LLM agents govern the information users receive, by drawing users' attention to particular instances of retrieved information at the expense of others. While much prior work has focused on biases in the information LLMs themselves generate, less attention has been paid to the factors that influence what information LLMs select and present to users. We hypothesize that when information is attributed to specific sources (e.g., particular publishers, journals, or platforms), current LLMs exhibit systematic latent source preferences- that is, they prioritize information from some sources over others. Through controlled experiments on twelve LLMs from six model providers, spanning both synthetic and real-world tasks, we find that several models consistently exhibit strong and predictable source preferences. These preferences are sensitive to contextual framing, can outweigh the influence of content itself, and persist despite explicit prompting to avoid them. They also help explain phenomena such as the observed left-leaning skew in news recommendations in prior work. Our findings advocate for deeper investigation into the origins of these preferences, as well as for mechanisms that provide users with transparency and control over the biases guiding LLM-powered agents.
Hubble: a Model Suite to Advance the Study of LLM Memorization
Oct 22, 2025We present Hubble, a suite of fully open-source large language models (LLMs) for the scientific study of LLM memorization. Hubble models come in standard and perturbed variants: standard models are pretrained on a large English corpus, and perturbed models are trained in the same way but with controlled insertion of text (e.g., book passages, biographies, and test sets) designed to emulate key memorization risks. Our core release includes 8 models -- standard and perturbed models with 1B or 8B parameters, pretrained on 100B or 500B tokens -- establishing that memorization risks are determined by the frequency of sensitive data relative to size of the training corpus (i.e., a password appearing once in a smaller corpus is memorized better than the same password in a larger corpus). Our release also includes 6 perturbed models with text inserted at different pretraining phases, showing that sensitive data without continued exposure can be forgotten. These findings suggest two best practices for addressing memorization risks: to dilute sensitive data by increasing the size of the training corpus, and to order sensitive data to appear earlier in training. Beyond these general empirical findings, Hubble enables a broad range of memorization research; for example, analyzing the biographies reveals how readily different types of private information are memorized. We also demonstrate that the randomized insertions in Hubble make it an ideal testbed for membership inference and machine unlearning, and invite the community to further explore, benchmark, and build upon our work.
Rote Learning Considered Useful: Generalizing over Memorized Data in LLMs
Jul 29, 2025Rote learning is a memorization technique based on repetition. It is commonly believed to hinder generalization by encouraging verbatim memorization rather than deeper understanding. This insight holds for even learning factual knowledge that inevitably requires a certain degree of memorization. In this work, we demonstrate that LLMs can be trained to generalize from rote memorized data. We introduce a two-phase memorize-then-generalize framework, where the model first rote memorizes factual subject-object associations using a semantically meaningless token and then learns to generalize by fine-tuning on a small set of semantically meaningful prompts. Extensive experiments over 8 LLMs show that the models can reinterpret rote memorized data through the semantically meaningful prompts, as evidenced by the emergence of structured, semantically aligned latent representations between the two. This surprising finding opens the door to both effective and efficient knowledge injection and possible risks of repurposing the memorized data for malicious usage.
Revisiting Privacy, Utility, and Efficiency Trade-offs when Fine-Tuning Large Language Models
Feb 18, 2025We study the inherent trade-offs in minimizing privacy risks and maximizing utility, while maintaining high computational efficiency, when fine-tuning large language models (LLMs). A number of recent works in privacy research have attempted to mitigate privacy risks posed by memorizing fine-tuning data by using differentially private training methods (e.g., DP), albeit at a significantly higher computational cost (inefficiency). In parallel, several works in systems research have focussed on developing (parameter) efficient fine-tuning methods (e.g., LoRA), but few works, if any, investigated whether such efficient methods enhance or diminish privacy risks. In this paper, we investigate this gap and arrive at a surprising conclusion: efficient fine-tuning methods like LoRA mitigate privacy risks similar to private fine-tuning methods like DP. Our empirical finding directly contradicts prevailing wisdom that privacy and efficiency objectives are at odds during fine-tuning. Our finding is established by (a) carefully defining measures of privacy and utility that distinguish between memorizing sensitive and non-sensitive tokens in training and test datasets used in fine-tuning and (b) extensive evaluations using multiple open-source language models from Pythia, Gemma, and Llama families and different domain-specific datasets.
QUENCH: Measuring the gap between Indic and Non-Indic Contextual General Reasoning in LLMs
Dec 16, 2024



The rise of large language models (LLMs) has created a need for advanced benchmarking systems beyond traditional setups. To this end, we introduce QUENCH, a novel text-based English Quizzing Benchmark manually curated and transcribed from YouTube quiz videos. QUENCH possesses masked entities and rationales for the LLMs to predict via generation. At the intersection of geographical context and common sense reasoning, QUENCH helps assess world knowledge and deduction capabilities of LLMs via a zero-shot, open-domain quizzing setup. We perform an extensive evaluation on 7 LLMs and 4 metrics, investigating the influence of model size, prompting style, geographical context, and gold-labeled rationale generation. The benchmarking concludes with an error analysis to which the LLMs are prone.
Understanding Memorisation in LLMs: Dynamics, Influencing Factors, and Implications
Jul 27, 2024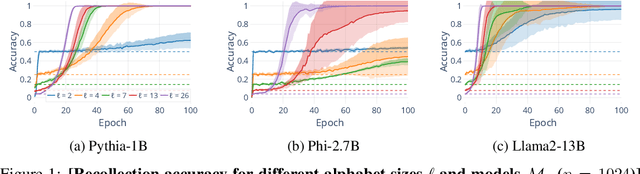
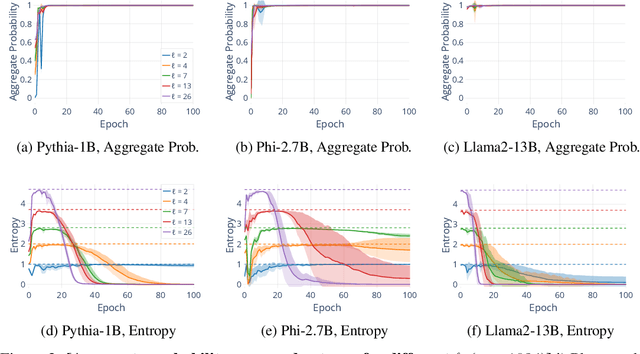
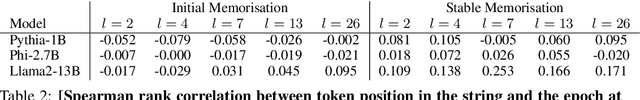
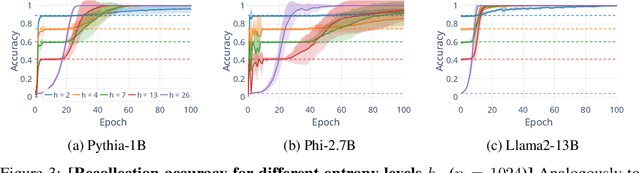
Understanding whether and to what extent large language models (LLMs) have memorised training data has important implications for the reliability of their output and the privacy of their training data. In order to cleanly measure and disentangle memorisation from other phenomena (e.g. in-context learning), we create an experimental framework that is based on repeatedly exposing LLMs to random strings. Our framework allows us to better understand the dynamics, i.e., the behaviour of the model, when repeatedly exposing it to random strings. Using our framework, we make several striking observations: (a) we find consistent phases of the dynamics across families of models (Pythia, Phi and Llama2), (b) we identify factors that make some strings easier to memorise than others, and (c) we identify the role of local prefixes and global context in memorisation. We also show that sequential exposition to different random strings has a significant effect on memorisation. Our results, often surprising, have significant downstream implications in the study and usage of LLMs.
Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon
Jun 25, 2024



Memorization in language models is typically treated as a homogenous phenomenon, neglecting the specifics of the memorized data. We instead model memorization as the effect of a set of complex factors that describe each sample and relate it to the model and corpus. To build intuition around these factors, we break memorization down into a taxonomy: recitation of highly duplicated sequences, reconstruction of inherently predictable sequences, and recollection of sequences that are neither. We demonstrate the usefulness of our taxonomy by using it to construct a predictive model for memorization. By analyzing dependencies and inspecting the weights of the predictive model, we find that different factors influence the likelihood of memorization differently depending on the taxonomic category.
Towards Reliable Latent Knowledge Estimation in LLMs: In-Context Learning vs. Prompting Based Factual Knowledge Extraction
Apr 19, 2024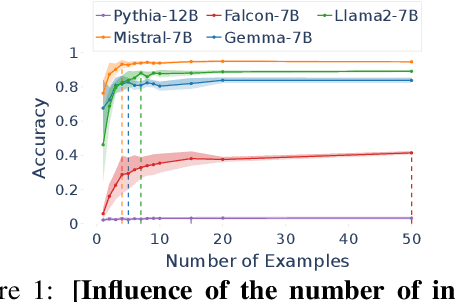
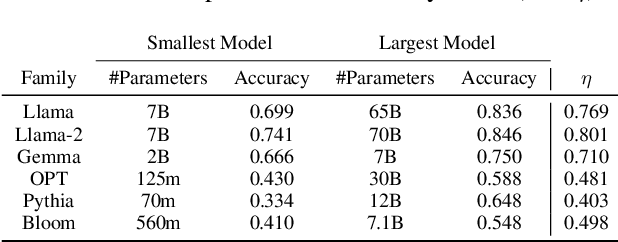
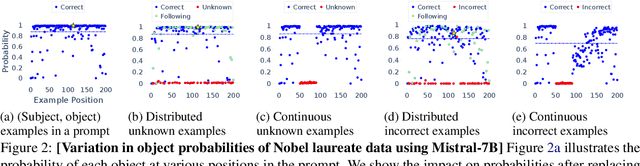
We propose an approach for estimating the latent knowledge embedded inside large language models (LLMs). We leverage the in-context learning (ICL) abilities of LLMs to estimate the extent to which an LLM knows the facts stored in a knowledge base. Our knowledge estimator avoids reliability concerns with previous prompting-based methods, is both conceptually simpler and easier to apply, and we demonstrate that it can surface more of the latent knowledge embedded in LLMs. We also investigate how different design choices affect the performance of ICL-based knowledge estimation. Using the proposed estimator, we perform a large-scale evaluation of the factual knowledge of a variety of open source LLMs, like OPT, Pythia, Llama(2), Mistral, Gemma, etc. over a large set of relations and facts from the Wikidata knowledge base. We observe differences in the factual knowledge between different model families and models of different sizes, that some relations are consistently better known than others but that models differ in the precise facts they know, and differences in the knowledge of base models and their finetuned counterparts.
Probing Critical Learning Dynamics of PLMs for Hate Speech Detection
Feb 03, 2024Despite the widespread adoption, there is a lack of research into how various critical aspects of pretrained language models (PLMs) affect their performance in hate speech detection. Through five research questions, our findings and recommendations lay the groundwork for empirically investigating different aspects of PLMs' use in hate speech detection. We deep dive into comparing different pretrained models, evaluating their seed robustness, finetuning settings, and the impact of pretraining data collection time. Our analysis reveals early peaks for downstream tasks during pretraining, the limited benefit of employing a more recent pretraining corpus, and the significance of specific layers during finetuning. We further call into question the use of domain-specific models and highlight the need for dynamic datasets for benchmarking hate speech detection.