 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactively Reducing the Hate Intensity of Online Posts via Hate Speech Normalization
Jun 08, 2022
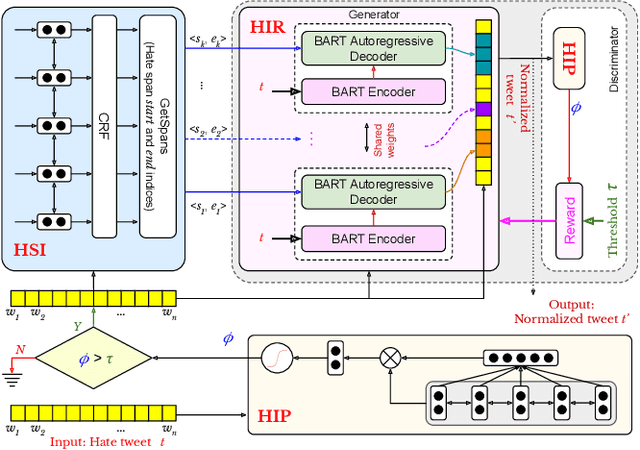
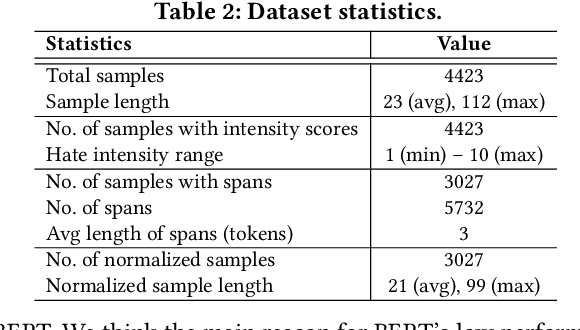
Curbing online hate speech has become the need of the hour; however, a blanket ban on such activities is infeasible for several geopolitical and cultural reasons. To reduce the severity of the problem, in this paper, we introduce a novel task, hate speech normalization, that aims to weaken the intensity of hatred exhibited by an online post. The intention of hate speech normalization is not to support hate but instead to provide the users with a stepping stone towards non-hate while giving online platforms more time to monitor any improvement in the user's behavior. To this end, we manually curated a parallel corpus - hate texts and their normalized counterparts (a normalized text is less hateful and more benign). We introduce NACL, a simple yet efficient hate speech normalization model that operates in three stages - first, it measures the hate intensity of the original sample; second, it identifies the hate span(s) within it; and finally, it reduces hate intensity by paraphrasing the hate spans. We perform extensive experiments to measure the efficacy of NACL via three-way evaluation (intrinsic, extrinsic, and human-study). We observe that NACL outperforms six baselines - NACL yields a score of 0.1365 RMSE for the intensity prediction, 0.622 F1-score in the span identification, and 82.27 BLEU and 80.05 perplexity for the normalized text generation. We further show the generalizability of NACL across other platforms (Reddit, Facebook, Gab). An interactive prototype of NACL was put together for the user study. Further, the tool is being deployed in a real-world setting at Wipro AI as a part of its mission to tackle harmful content on online platforms.
Why Did You Not Compare With That? Identifying Papers for Use as Baselines
Jan 20, 2022
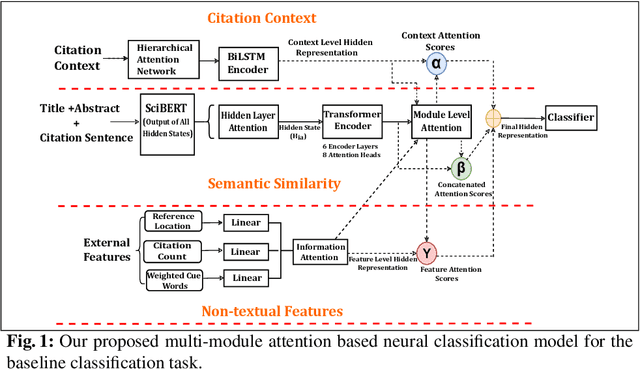


We propose the task of automatically identifying papers used as baselines in a scientific article. We frame the problem as a binary classification task where all the references in a paper are to be classified as either baselines or non-baselines. This is a challenging problem due to the numerous ways in which a baseline reference can appear in a paper. We develop a dataset of $2,075$ papers from ACL anthology corpus with all their references manually annotated as one of the two classes. We develop a multi-module attention-based neural classifier for the baseline classification task that outperforms four state-of-the-art citation role classification methods when applied to the baseline classification task. We also present an analysis of the errors made by the proposed classifier, eliciting the challenges that make baseline identification a challenging problem.
Multi-modal Sarcasm Detection and Humor Classification in Code-mixed Conversations
May 31, 2021
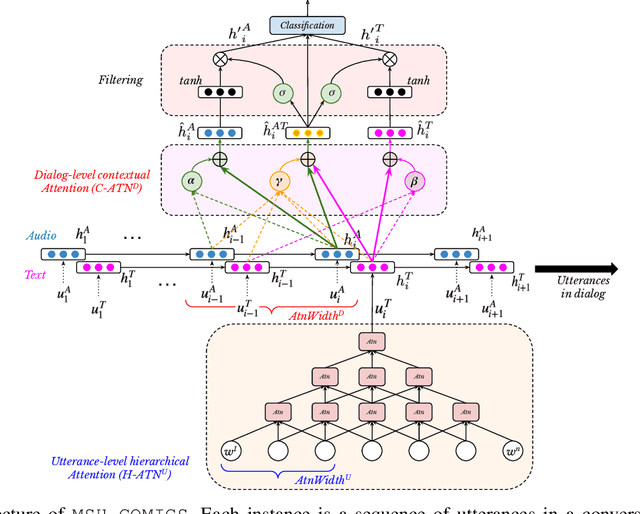


Sarcasm detection and humor classification are inherently subtle problems, primarily due to their dependence on the contextual and non-verbal information. Furthermore, existing studies in these two topics are usually constrained in non-English languages such as Hindi, due to the unavailability of qualitative annotated datasets. In this work, we make two major contributions considering the above limitations: (1) we develop a Hindi-English code-mixed dataset, MaSaC, for the multi-modal sarcasm detection and humor classification in conversational dialog, which to our knowledge is the first dataset of its kind; (2) we propose MSH-COMICS, a novel attention-rich neural architecture for the utterance classification. We learn efficient utterance representation utilizing a hierarchical attention mechanism that attends to a small portion of the input sentence at a time. Further, we incorporate dialog-level contextual attention mechanism to leverage the dialog history for the multi-modal classification. We perform extensive experiments for both the tasks by varying multi-modal inputs and various submodules of MSH-COMICS. We also conduct comparative analysis against existing approaches. We observe that MSH-COMICS attains superior performance over the existing models by > 1 F1-score point for the sarcasm detection and 10 F1-score points in humor classification. We diagnose our model and perform thorough analysis of the results to understand the superiority and pitfalls.