 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency Is the Key: Detecting Hallucinations in LLM Generated Text By Checking Inconsistencies About Key Facts
Nov 15, 2025Large language models (LLMs), despite their remarkable text generation capabilities, often hallucinate and generate text that is factually incorrect and not grounded in real-world knowledge. This poses serious risks in domains like healthcare, finance, and customer support. A typical way to use LLMs is via the APIs provided by LLM vendors where there is no access to model weights or options to fine-tune the model. Existing methods to detect hallucinations in such settings where the model access is restricted or constrained by resources typically require making multiple LLM API calls, increasing latency and API cost. We introduce CONFACTCHECK, an efficient hallucination detection approach that does not leverage any external knowledge base and works on the simple intuition that responses to factual probes within the generated text should be consistent within a single LLM and across different LLMs. Rigorous empirical evaluation on multiple datasets that cover both the generation of factual texts and the open generation shows that CONFACTCHECK can detect hallucinated facts efficiently using fewer resources and achieves higher accuracy scores compared to existing baselines that operate under similar conditions. Our code is available here.
On the Effect of Instruction Tuning Loss on Generalization
Jul 10, 2025Instruction Tuning has emerged as a pivotal post-training paradigm that enables pre-trained language models to better follow user instructions. Despite its significance, little attention has been given to optimizing the loss function used. A fundamental, yet often overlooked, question is whether the conventional auto-regressive objective - where loss is computed only on response tokens, excluding prompt tokens - is truly optimal for instruction tuning. In this work, we systematically investigate the impact of differentially weighting prompt and response tokens in instruction tuning loss, and propose Weighted Instruction Tuning (WIT) as a better alternative to conventional instruction tuning. Through extensive experiments on five language models of different families and scale, three finetuning datasets of different sizes, and five diverse evaluation benchmarks, we show that the standard instruction tuning loss often yields suboptimal performance and limited robustness to input prompt variations. We find that a low-to-moderate weight for prompt tokens coupled with a moderate-to-high weight for response tokens yields the best-performing models across settings and also serve as better starting points for the subsequent preference alignment training. These findings highlight the need to reconsider instruction tuning loss and offer actionable insights for developing more robust and generalizable models. Our code is open-sourced at https://github.com/kowndinya-renduchintala/WIT.
Exploring the Role of Diversity in Example Selection for In-Context Learning
May 03, 2025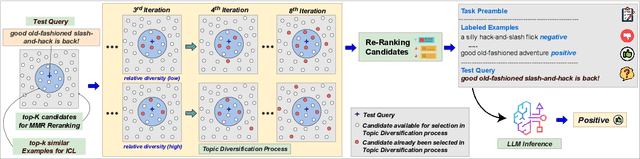
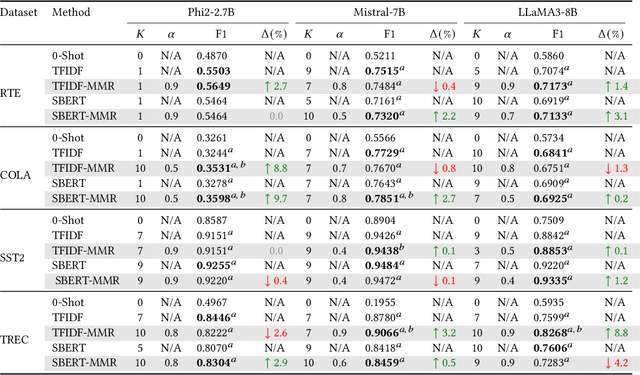
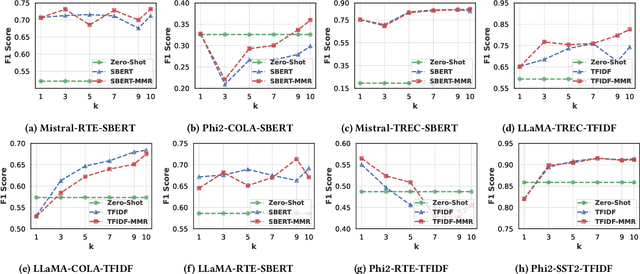
In-Context Learning (ICL) has gained prominence due to its ability to perform tasks without requiring extensive training data and its robustness to noisy labels. A typical ICL workflow involves selecting localized examples relevant to a given input using sparse or dense embedding-based similarity functions. However, relying solely on similarity-based selection may introduce topical biases in the retrieved contexts, potentially leading to suboptimal downstream performance. We posit that reranking the retrieved context to enhance topical diversity can improve downstream task performance. To achieve this, we leverage maximum marginal relevance (MMR) which balances topical similarity with inter-example diversity. Our experimental results demonstrate that diversifying the selected examples leads to consistent improvements in downstream performance across various context sizes and similarity functions. The implementation of our approach is made available at https://github.com/janak11111/Diverse-ICL.
Learning Sparse Disentangled Representations for Multimodal Exclusion Retrieval
Apr 04, 2025



Multimodal representations are essential for cross-modal retrieval, but they often lack interpretability, making it difficult to understand the reasoning behind retrieved results. Sparse disentangled representations offer a promising solution; however, existing methods rely heavily on text tokens, resulting in high-dimensional embeddings. In this work, we propose a novel approach that generates compact, fixed-size embeddings that maintain disentanglement while providing greater control over retrieval tasks. We evaluate our method on challenging exclusion queries using the MSCOCO and Conceptual Captions benchmarks, demonstrating notable improvements over dense models like CLIP, BLIP, and VISTA (with gains of up to 11% in AP@10), as well as over sparse disentangled models like VDR (achieving up to 21% gains in AP@10). Furthermore, we present qualitative results that emphasize the enhanced interpretability of our disentangled representations.
It Helps to Take a Second Opinion: Teaching Smaller LLMs to Deliberate Mutually via Selective Rationale Optimisation
Mar 04, 2025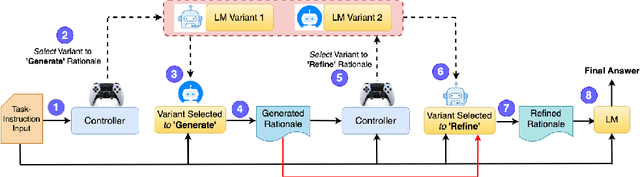
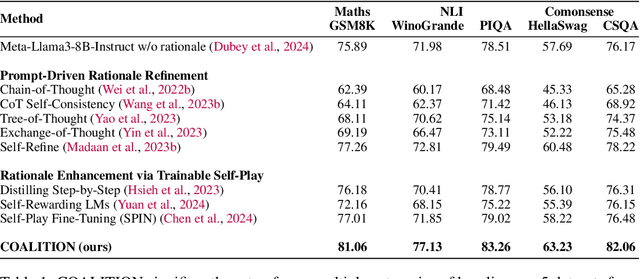
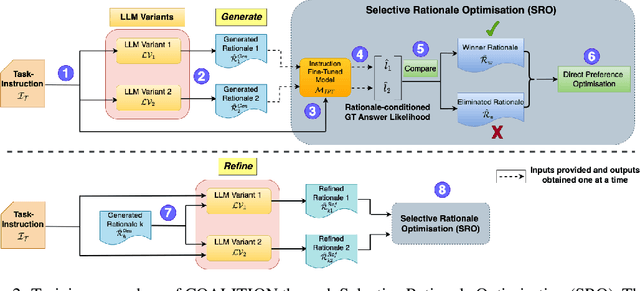

Very large language models (LLMs) such as GPT-4 have shown the ability to handle complex tasks by generating and self-refining step-by-step rationales. Smaller language models (SLMs), typically with < 13B parameters, have been improved by using the data generated from very-large LMs through knowledge distillation. However, various practical constraints such as API costs, copyright, legal and ethical policies restrict using large (often opaque) models to train smaller models for commercial use. Limited success has been achieved at improving the ability of an SLM to explore the space of possible rationales and evaluate them by itself through self-deliberation. To address this, we propose COALITION, a trainable framework that facilitates interaction between two variants of the same SLM and trains them to generate and refine rationales optimized for the end-task. The variants exhibit different behaviors to produce a set of diverse candidate rationales during the generation and refinement steps. The model is then trained via Selective Rationale Optimization (SRO) to prefer generating rationale candidates that maximize the likelihood of producing the ground-truth answer. During inference, COALITION employs a controller to select the suitable variant for generating and refining the rationales. On five different datasets covering mathematical problems, commonsense reasoning, and natural language inference, COALITION outperforms several baselines by up to 5%. Our ablation studies reveal that cross-communication between the two variants performs better than using the single model to self-refine the rationales. We also demonstrate the applicability of COALITION for LMs of varying scales (4B to 14B parameters) and model families (Mistral, Llama, Qwen, Phi). We release the code for this work at https://github.com/Sohanpatnaik106/coalition.
POSIX: A Prompt Sensitivity Index For Large Language Models
Oct 03, 2024



Despite their remarkable capabilities, Large Language Models (LLMs) are found to be surprisingly sensitive to minor variations in prompts, often generating significantly divergent outputs in response to minor variations in the prompts, such as spelling errors, alteration of wording or the prompt template. However, while assessing the quality of an LLM, the focus often tends to be solely on its performance on downstream tasks, while very little to no attention is paid to prompt sensitivity. To fill this gap, we propose POSIX - a novel PrOmpt Sensitivity IndeX as a reliable measure of prompt sensitivity, thereby offering a more comprehensive evaluation of LLM performance. The key idea behind POSIX is to capture the relative change in loglikelihood of a given response upon replacing the corresponding prompt with a different intent-preserving prompt. We provide thorough empirical evidence demonstrating the efficacy of POSIX in capturing prompt sensitivity and subsequently use it to measure and thereby compare prompt sensitivity of various open-source LLMs. We find that merely increasing the parameter count or instruction tuning does not necessarily reduce prompt sensitivity whereas adding some few-shot exemplars, even just one, almost always leads to significant decrease in prompt sensitivity. We also find that alterations to prompt template lead to the highest sensitivity in the case of MCQtype tasks, whereas paraphrasing results in the highest sensitivity in open-ended generation tasks. The code for reproducing our results is open-sourced at https://github.com/kowndinyarenduchintala/POSIX.
Thinking Fair and Slow: On the Efficacy of Structured Prompts for Debiasing Language Models
May 16, 2024
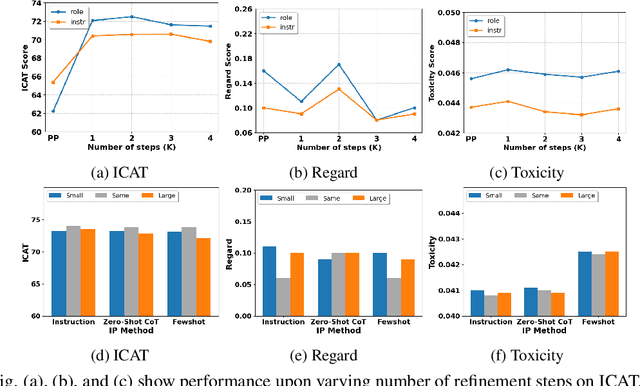
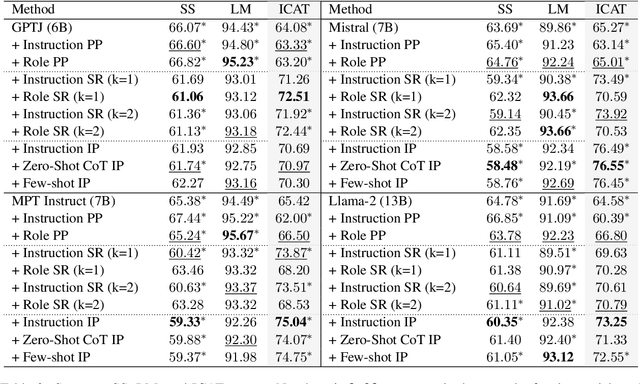
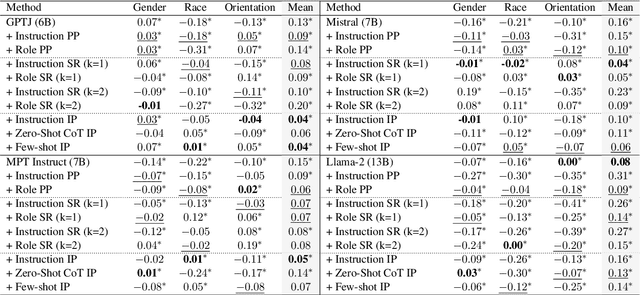
Existing debiasing techniques are typically training-based or require access to the model's internals and output distributions, so they are inaccessible to end-users looking to adapt LLM outputs for their particular needs. In this study, we examine whether structured prompting techniques can offer opportunities for fair text generation. We evaluate a comprehensive end-user-focused iterative framework of debiasing that applies System 2 thinking processes for prompts to induce logical, reflective, and critical text generation, with single, multi-step, instruction, and role-based variants. By systematically evaluating many LLMs across many datasets and different prompting strategies, we show that the more complex System 2-based Implicative Prompts significantly improve over other techniques demonstrating lower mean bias in the outputs with competitive performance on the downstream tasks. Our work offers research directions for the design and the potential of end-user-focused evaluative frameworks for LLM use.
xLP: Explainable Link Prediction for Master Data Management
Mar 14, 2024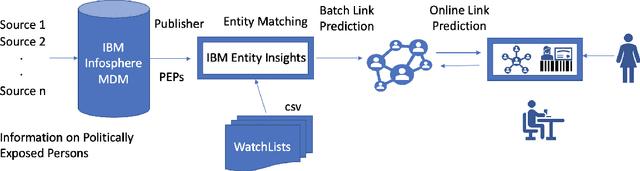
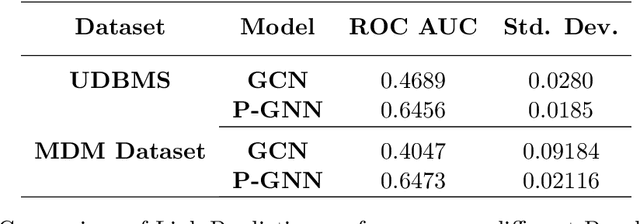
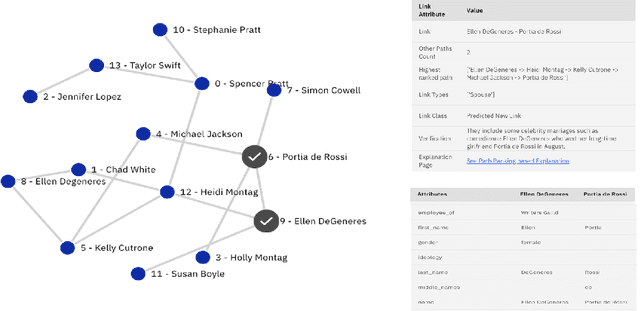

Explaining neural model predictions to users requires creativity. Especially in enterprise applications, where there are costs associated with users' time, and their trust in the model predictions is critical for adoption. For link prediction in master data management, we have built a number of explainability solutions drawing from research in interpretability, fact verification, path ranking, neuro-symbolic reasoning and self-explaining AI. In this demo, we present explanations for link prediction in a creative way, to allow users to choose explanations they are more comfortable with.
SMART: Submodular Data Mixture Strategy for Instruction Tuning
Mar 13, 2024


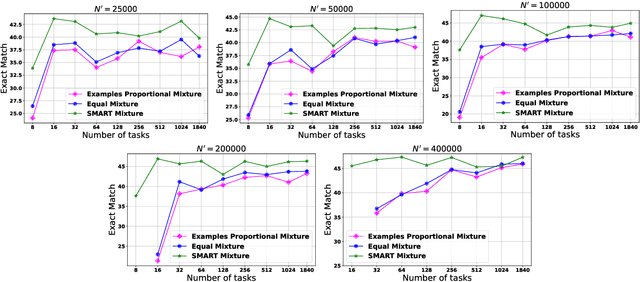
Instruction Tuning involves finetuning a language model on a collection of instruction-formatted datasets in order to enhance the generalizability of the model to unseen tasks. Studies have shown the importance of balancing different task proportions during finetuning, but finding the right balance remains challenging. Unfortunately, there's currently no systematic method beyond manual tuning or relying on practitioners' intuition. In this paper, we introduce SMART (Submodular data Mixture strAtegy for instRuction Tuning) - a novel data mixture strategy which makes use of a submodular function to assign importance scores to tasks which are then used to determine the mixture weights. Given a fine-tuning budget, SMART redistributes the budget among tasks and selects non-redundant samples from each task. Experimental results demonstrate that SMART significantly outperforms traditional methods such as examples proportional mixing and equal mixing. Furthermore, SMART facilitates the creation of data mixtures based on a few representative subsets of tasks alone and through task pruning analysis, we reveal that in a limited budget setting, allocating budget among a subset of representative tasks yields superior performance compared to distributing the budget among all tasks. The code for reproducing our results is open-sourced at https://github.com/kowndinya-renduchintala/SMART.
CABINET: Content Relevance based Noise Reduction for Table Question Answering
Feb 05, 2024



Table understanding capability of Large Language Models (LLMs) has been extensively studied through the task of question-answering (QA) over tables. Typically, only a small part of the whole table is relevant to derive the answer for a given question. The irrelevant parts act as noise and are distracting information, resulting in sub-optimal performance due to the vulnerability of LLMs to noise. To mitigate this, we propose CABINET (Content RelevAnce-Based NoIse ReductioN for TablE QuesTion-Answering) - a framework to enable LLMs to focus on relevant tabular data by suppressing extraneous information. CABINET comprises an Unsupervised Relevance Scorer (URS), trained differentially with the QA LLM, that weighs the table content based on its relevance to the input question before feeding it to the question-answering LLM (QA LLM). To further aid the relevance scorer, CABINET employs a weakly supervised module that generates a parsing statement describing the criteria of rows and columns relevant to the question and highlights the content of corresponding table cells. CABINET significantly outperforms various tabular LLM baselines, as well as GPT3-based in-context learning methods, is more robust to noise, maintains outperformance on tables of varying sizes, and establishes new SoTA performance on WikiTQ, FeTaQA, and WikiSQL datasets. We release our code and datasets at https://github.com/Sohanpatnaik106/CABINET_QA.