 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effect of Instruction Tuning Loss on Generalization
Jul 10, 2025Instruction Tuning has emerged as a pivotal post-training paradigm that enables pre-trained language models to better follow user instructions. Despite its significance, little attention has been given to optimizing the loss function used. A fundamental, yet often overlooked, question is whether the conventional auto-regressive objective - where loss is computed only on response tokens, excluding prompt tokens - is truly optimal for instruction tuning. In this work, we systematically investigate the impact of differentially weighting prompt and response tokens in instruction tuning loss, and propose Weighted Instruction Tuning (WIT) as a better alternative to conventional instruction tuning. Through extensive experiments on five language models of different families and scale, three finetuning datasets of different sizes, and five diverse evaluation benchmarks, we show that the standard instruction tuning loss often yields suboptimal performance and limited robustness to input prompt variations. We find that a low-to-moderate weight for prompt tokens coupled with a moderate-to-high weight for response tokens yields the best-performing models across settings and also serve as better starting points for the subsequent preference alignment training. These findings highlight the need to reconsider instruction tuning loss and offer actionable insights for developing more robust and generalizable models. Our code is open-sourced at https://github.com/kowndinya-renduchintala/WIT.
POSIX: A Prompt Sensitivity Index For Large Language Models
Oct 03, 2024



Despite their remarkable capabilities, Large Language Models (LLMs) are found to be surprisingly sensitive to minor variations in prompts, often generating significantly divergent outputs in response to minor variations in the prompts, such as spelling errors, alteration of wording or the prompt template. However, while assessing the quality of an LLM, the focus often tends to be solely on its performance on downstream tasks, while very little to no attention is paid to prompt sensitivity. To fill this gap, we propose POSIX - a novel PrOmpt Sensitivity IndeX as a reliable measure of prompt sensitivity, thereby offering a more comprehensive evaluation of LLM performance. The key idea behind POSIX is to capture the relative change in loglikelihood of a given response upon replacing the corresponding prompt with a different intent-preserving prompt. We provide thorough empirical evidence demonstrating the efficacy of POSIX in capturing prompt sensitivity and subsequently use it to measure and thereby compare prompt sensitivity of various open-source LLMs. We find that merely increasing the parameter count or instruction tuning does not necessarily reduce prompt sensitivity whereas adding some few-shot exemplars, even just one, almost always leads to significant decrease in prompt sensitivity. We also find that alterations to prompt template lead to the highest sensitivity in the case of MCQtype tasks, whereas paraphrasing results in the highest sensitivity in open-ended generation tasks. The code for reproducing our results is open-sourced at https://github.com/kowndinyarenduchintala/POSIX.
Language Models can Exploit Cross-Task In-context Learning for Data-Scarce Novel Tasks
May 17, 2024


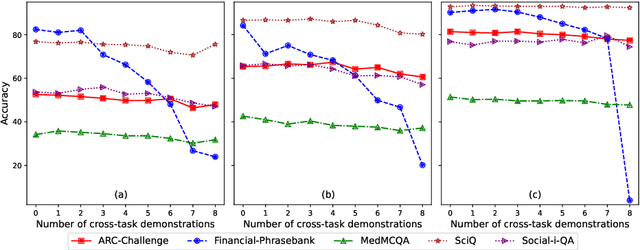
Large Language Models (LLMs) have transformed NLP with their remarkable In-context Learning (ICL) capabilities. Automated assistants based on LLMs are gaining popularity; however, adapting them to novel tasks is still challenging. While colossal models excel in zero-shot performance, their computational demands limit widespread use, and smaller language models struggle without context. This paper investigates whether LLMs can generalize from labeled examples of predefined tasks to novel tasks. Drawing inspiration from biological neurons and the mechanistic interpretation of the Transformer architecture, we explore the potential for information sharing across tasks. We design a cross-task prompting setup with three LLMs and show that LLMs achieve significant performance improvements despite no examples from the target task in the context. Cross-task prompting leads to a remarkable performance boost of 107% for LLaMA-2 7B, 18.6% for LLaMA-2 13B, and 3.2% for GPT 3.5 on average over zero-shot prompting, and performs comparable to standard in-context learning. The effectiveness of generating pseudo-labels for in-task examples is demonstrated, and our analyses reveal a strong correlation between the effect of cross-task examples and model activation similarities in source and target input tokens. This paper offers a first-of-its-kind exploration of LLMs' ability to solve novel tasks based on contextual signals from different task examples.