 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual LLMs Struggle to Link Orthography and Semantics in Bilingual Word Processing
Jan 15, 2025



Bilingual lexical processing is shaped by the complex interplay of phonological, orthographic, and semantic features of two languages within an integrated mental lexicon. In humans, this is evident in the ease with which cognate words - words similar in both orthographic form and meaning (e.g., blind, meaning "sightless" in both English and German) - are processed, compared to the challenges posed by interlingual homographs, which share orthographic form but differ in meaning (e.g., gift, meaning "present" in English but "poison" in German). We investigate how multilingual Large Language Models (LLMs) handle such phenomena, focusing on English-Spanish, English-French, and English-German cognates, non-cognate, and interlingual homographs. Specifically, we evaluate their ability to disambiguate meanings and make semantic judgments, both when these word types are presented in isolation or within sentence contexts. Our findings reveal that while certain LLMs demonstrate strong performance in recognizing cognates and non-cognates in isolation, they exhibit significant difficulty in disambiguating interlingual homographs, often performing below random baselines. This suggests LLMs tend to rely heavily on orthographic similarities rather than semantic understanding when interpreting interlingual homographs. Further, we find LLMs exhibit difficulty in retrieving word meanings, with performance in isolative disambiguation tasks having no correlation with semantic understanding. Finally, we study how the LLM processes interlingual homographs in incongruent sentences. We find models to opt for different strategies in understanding English and non-English homographs, highlighting a lack of a unified approach to handling cross-lingual ambiguities.
Language Models can Exploit Cross-Task In-context Learning for Data-Scarce Novel Tasks
May 17, 2024


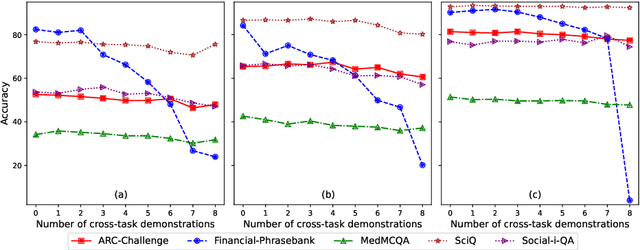
Large Language Models (LLMs) have transformed NLP with their remarkable In-context Learning (ICL) capabilities. Automated assistants based on LLMs are gaining popularity; however, adapting them to novel tasks is still challenging. While colossal models excel in zero-shot performance, their computational demands limit widespread use, and smaller language models struggle without context. This paper investigates whether LLMs can generalize from labeled examples of predefined tasks to novel tasks. Drawing inspiration from biological neurons and the mechanistic interpretation of the Transformer architecture, we explore the potential for information sharing across tasks. We design a cross-task prompting setup with three LLMs and show that LLMs achieve significant performance improvements despite no examples from the target task in the context. Cross-task prompting leads to a remarkable performance boost of 107% for LLaMA-2 7B, 18.6% for LLaMA-2 13B, and 3.2% for GPT 3.5 on average over zero-shot prompting, and performs comparable to standard in-context learning. The effectiveness of generating pseudo-labels for in-task examples is demonstrated, and our analyses reveal a strong correlation between the effect of cross-task examples and model activation similarities in source and target input tokens. This paper offers a first-of-its-kind exploration of LLMs' ability to solve novel tasks based on contextual signals from different task examples.
Multilingual LLMs are Better Cross-lingual In-context Learners with Alignment
May 26, 2023
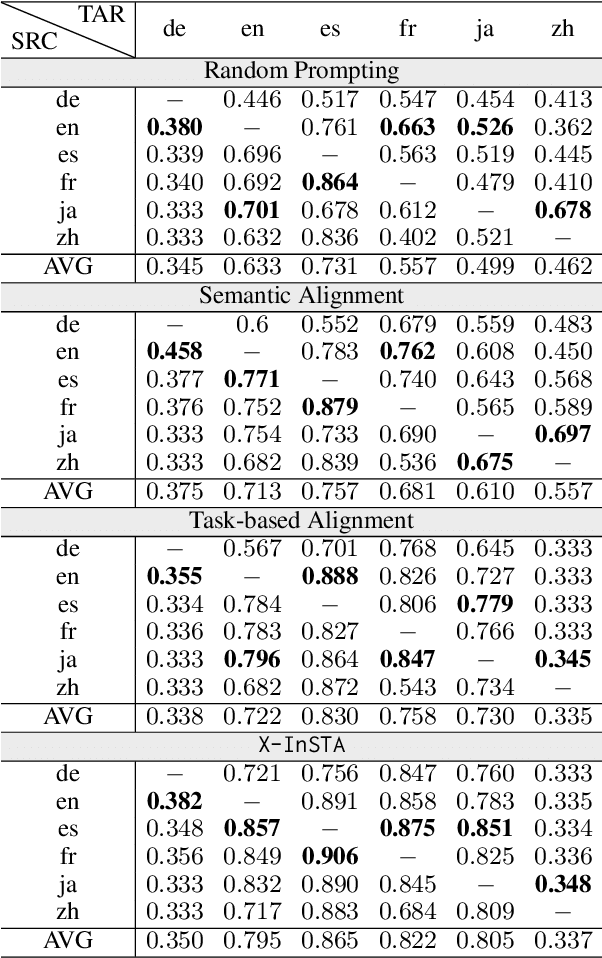


In-context learning (ICL) unfolds as large language models become capable of inferring test labels conditioned on a few labeled samples without any gradient update. ICL-enabled large language models provide a promising step forward toward bypassing recurrent annotation costs in a low-resource setting. Yet, only a handful of past studies have explored ICL in a cross-lingual setting, in which the need for transferring label-knowledge from a high-resource language to a low-resource one is immensely crucial. To bridge the gap, we provide the first in-depth analysis of ICL for cross-lingual text classification. We find that the prevalent mode of selecting random input-label pairs to construct the prompt-context is severely limited in the case of cross-lingual ICL, primarily due to the lack of alignment in the input as well as the output spaces. To mitigate this, we propose a novel prompt construction strategy -- Cross-lingual In-context Source-Target Alignment (X-InSTA). With an injected coherence in the semantics of the input examples and a task-based alignment across the source and target languages, X-InSTA is able to outperform random prompt selection by a large margin across three different tasks using 44 different cross-lingual pairs.
Model-Agnostic Meta-Learning for Multilingual Hate Speech Detection
Mar 04, 2023Hate speech in social media is a growing phenomenon, and detecting such toxic content has recently gained significant traction in the research community. Existing studies have explored fine-tuning language models (LMs) to perform hate speech detection, and these solutions have yielded significant performance. However, most of these studies are limited to detecting hate speech only in English, neglecting the bulk of hateful content that is generated in other languages, particularly in low-resource languages. Developing a classifier that captures hate speech and nuances in a low-resource language with limited data is extremely challenging. To fill the research gap, we propose HateMAML, a model-agnostic meta-learning-based framework that effectively performs hate speech detection in low-resource languages. HateMAML utilizes a self-supervision strategy to overcome the limitation of data scarcity and produces better LM initialization for fast adaptation to an unseen target language (i.e., cross-lingual transfer) or other hate speech datasets (i.e., domain generalization). Extensive experiments are conducted on five datasets across eight different low-resource languages. The results show that HateMAML outperforms the state-of-the-art baselines by more than 3% in the cross-domain multilingual transfer setting. We also conduct ablation studies to analyze the characteristics of HateMAML.