 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Visual Narratives Undermine Safety Alignment in Multimodal Large Language Models
Mar 23, 2026Multimodal Large Language Models (MLLMs) extend text-only LLMs with visual reasoning, but also introduce new safety failure modes under visually grounded instructions. We study comic-template jailbreaks that embed harmful goals inside simple three-panel visual narratives and prompt the model to role-play and "complete the comic." Building on JailbreakBench and JailbreakV, we introduce ComicJailbreak, a comic-based jailbreak benchmark with 1,167 attack instances spanning 10 harm categories and 5 task setups. Across 15 state-of-the-art MLLMs (six commercial and nine open-source), comic-based attacks achieve success rates comparable to strong rule-based jailbreaks and substantially outperform plain-text and random-image baselines, with ensemble success rates exceeding 90% on several commercial models. Then, with the existing defense methodologies, we show that these methods are effective against the harmful comics, they will induce a high refusal rate when prompted with benign prompts. Finally, using automatic judging and targeted human evaluation, we show that current safety evaluators can be unreliable on sensitive but non-harmful content. Our findings highlight the need for safety alignment robust to narrative-driven multimodal jailbreaks.
SEAHateCheck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia
Mar 17, 2026Hate speech detection relies heavily on linguistic resources, which are primarily available in high-resource languages such as English and Chinese, creating barriers for researchers and platforms developing tools for low-resource languages in Southeast Asia, where diverse socio-linguistic contexts complicate online hate moderation. To address this, we introduce SEAHateCheck, a pioneering dataset tailored to Indonesia, Thailand, the Philippines, and Vietnam, covering Indonesian, Tagalog, Thai, and Vietnamese. Building on HateCheck's functional testing framework and refining SGHateCheck's methods, SEAHateCheck provides culturally relevant test cases, augmented by large language models and validated by local experts for accuracy. Experiments with state-of-the-art and multilingual models revealed limitations in detecting hate speech in specific low-resource languages. In particular, Tagalog test cases showed the lowest model accuracy, likely due to linguistic complexity and limited training data. In contrast, slang-based functional tests proved the hardest, as models struggled with culturally nuanced expressions. The diagnostic insights of SEAHateCheck further exposed model weaknesses in implicit hate detection and models' struggles with counter-speech expression. As the first functional test suite for these Southeast Asian languages, this work equips researchers with a robust benchmark, advancing the development of practical, culturally attuned hate speech detection tools for inclusive online content moderation.
From Perception to Action: An Interactive Benchmark for Vision Reasoning
Feb 24, 2026Understanding the physical structure is essential for real-world applications such as embodied agents, interactive design, and long-horizon manipulation. Yet, prevailing Vision-Language Model (VLM) evaluations still center on structure-agnostic, single-turn setups (e.g., VQA), which fail to assess agents' ability to reason about how geometry, contact, and support relations jointly constrain what actions are possible in a dynamic environment. To address this gap, we introduce the Causal Hierarchy of Actions and Interactions (CHAIN) benchmark, an interactive 3D, physics-driven testbed designed to evaluate whether models can understand, plan, and execute structured action sequences grounded in physical constraints. CHAIN shifts evaluation from passive perception to active problem solving, spanning tasks such as interlocking mechanical puzzles and 3D stacking and packing. We conduct a comprehensive study of state-of-the-art VLMs and diffusion-based models under unified interactive settings. Our results show that top-performing models still struggle to internalize physical structure and causal constraints, often failing to produce reliable long-horizon plans and cannot robustly translate perceived structure into effective actions. The project is available at https://social-ai-studio.github.io/CHAIN/.
StreamSense: Streaming Social Task Detection with Selective Vision-Language Model Routing
Jan 30, 2026Live streaming platforms require real-time monitoring and reaction to social signals, utilizing partial and asynchronous evidence from video, text, and audio. We propose StreamSense, a streaming detector that couples a lightweight streaming encoder with selective routing to a Vision-Language Model (VLM) expert. StreamSense handles most timestamps with the lightweight streaming encoder, escalates hard/ambiguous cases to the VLM, and defers decisions when context is insufficient. The encoder is trained using (i) a cross-modal contrastive term to align visual/audio cues with textual signals, and (ii) an IoU-weighted loss that down-weights poorly overlapping target segments, mitigating label interference across segment boundaries. We evaluate StreamSense on multiple social streaming detection tasks (e.g., sentiment classification and hate content moderation), and the results show that StreamSense achieves higher accuracy than VLM-only streaming while only occasionally invoking the VLM, thereby reducing average latency and compute. Our results indicate that selective escalation and deferral are effective primitives for understanding streaming social tasks. Code is publicly available on GitHub.
HateXScore: A Metric Suite for Evaluating Reasoning Quality in Hate Speech Explanations
Jan 20, 2026Hateful speech detection is a key component of content moderation, yet current evaluation frameworks rarely assess why a text is deemed hateful. We introduce \textsf{HateXScore}, a four-component metric suite designed to evaluate the reasoning quality of model explanations. It assesses (i) conclusion explicitness, (ii) faithfulness and causal grounding of quoted spans, (iii) protected group identification (policy-configurable), and (iv) logical consistency among these elements. Evaluated on six diverse hate speech datasets, \textsf{HateXScore} is intended as a diagnostic complement to reveal interpretability failures and annotation inconsistencies that are invisible to standard metrics like Accuracy or F1. Moreover, human evaluation shows strong agreement with \textsf{HateXScore}, validating it as a practical tool for trustworthy and transparent moderation. \textcolor{red}{Disclaimer: This paper contains sensitive content that may be disturbing to some readers.}
A Comparative Study of Traditional Machine Learning, Deep Learning, and Large Language Models for Mental Health Forecasting using Smartphone Sensing Data
Jan 07, 2026Smartphone sensing offers an unobtrusive and scalable way to track daily behaviors linked to mental health, capturing changes in sleep, mobility, and phone use that often precede symptoms of stress, anxiety, or depression. While most prior studies focus on detection that responds to existing conditions, forecasting mental health enables proactive support through Just-in-Time Adaptive Interventions. In this paper, we present the first comprehensive benchmarking study comparing traditional machine learning (ML), deep learning (DL), and large language model (LLM) approaches for mental health forecasting using the College Experience Sensing (CES) dataset, the most extensive longitudinal dataset of college student mental health to date. We systematically evaluate models across temporal windows, feature granularities, personalization strategies, and class imbalance handling. Our results show that DL models, particularly Transformer (Macro-F1 = 0.58), achieve the best overall performance, while LLMs show strength in contextual reasoning but weaker temporal modeling. Personalization substantially improves forecasts of severe mental health states. By revealing how different modeling approaches interpret phone sensing behavioral data over time, this work lays the groundwork for next-generation, adaptive, and human-centered mental health technologies that can advance both research and real-world well-being.
With Great Capabilities Come Great Responsibilities: Introducing the Agentic Risk & Capability Framework for Governing Agentic AI Systems
Dec 22, 2025Agentic AI systems present both significant opportunities and novel risks due to their capacity for autonomous action, encompassing tasks such as code execution, internet interaction, and file modification. This poses considerable challenges for effective organizational governance, particularly in comprehensively identifying, assessing, and mitigating diverse and evolving risks. To tackle this, we introduce the Agentic Risk \& Capability (ARC) Framework, a technical governance framework designed to help organizations identify, assess, and mitigate risks arising from agentic AI systems. The framework's core contributions are: (1) it develops a novel capability-centric perspective to analyze a wide range of agentic AI systems; (2) it distills three primary sources of risk intrinsic to agentic AI systems - components, design, and capabilities; (3) it establishes a clear nexus between each risk source, specific materialized risks, and corresponding technical controls; and (4) it provides a structured and practical approach to help organizations implement the framework. This framework provides a robust and adaptable methodology for organizations to navigate the complexities of agentic AI, enabling rapid and effective innovation while ensuring the safe, secure, and responsible deployment of agentic AI systems. Our framework is open-sourced \href{https://govtech-responsibleai.github.io/agentic-risk-capability-framework/}{here}.
Modeling Narrative Archetypes in Conspiratorial Narratives: Insights from Singapore-Based Telegram Groups
Dec 10, 2025Conspiratorial discourse is increasingly embedded within digital communication ecosystems, yet its structure and spread remain difficult to study. This work analyzes conspiratorial narratives in Singapore-based Telegram groups, showing that such content is woven into everyday discussions rather than confined to isolated echo chambers. We propose a two-stage computational framework. First, we fine-tune RoBERTa-large to classify messages as conspiratorial or not, achieving an F1-score of 0.866 on 2,000 expert-labeled messages. Second, we build a signed belief graph in which nodes represent messages and edge signs reflect alignment in belief labels, weighted by textual similarity. We introduce a Signed Belief Graph Neural Network (SiBeGNN) that uses a Sign Disentanglement Loss to learn embeddings that separate ideological alignment from stylistic features. Using hierarchical clustering on these embeddings, we identify seven narrative archetypes across 553,648 messages: legal topics, medical concerns, media discussions, finance, contradictions in authority, group moderation, and general chat. SiBeGNN yields stronger clustering quality (cDBI = 8.38) than baseline methods (13.60 to 67.27), supported by 88 percent inter-rater agreement in expert evaluations. Our analysis shows that conspiratorial messages appear not only in clusters focused on skepticism or distrust, but also within routine discussions of finance, law, and everyday matters. These findings challenge common assumptions about online radicalization by demonstrating that conspiratorial discourse operates within ordinary social interaction. The proposed framework advances computational methods for belief-driven discourse analysis and offers applications for stance detection, political communication studies, and content moderation policy.
Multi-Agent VLMs Guided Self-Training with PNU Loss for Low-Resource Offensive Content Detection
Nov 14, 2025



Accurate detection of offensive content on social media demands high-quality labeled data; however, such data is often scarce due to the low prevalence of offensive instances and the high cost of manual annotation. To address this low-resource challenge, we propose a self-training framework that leverages abundant unlabeled data through collaborative pseudo-labeling. Starting with a lightweight classifier trained on limited labeled data, our method iteratively assigns pseudo-labels to unlabeled instances with the support of Multi-Agent Vision-Language Models (MA-VLMs). Un-labeled data on which the classifier and MA-VLMs agree are designated as the Agreed-Unknown set, while conflicting samples form the Disagreed-Unknown set. To enhance label reliability, MA-VLMs simulate dual perspectives, moderator and user, capturing both regulatory and subjective viewpoints. The classifier is optimized using a novel Positive-Negative-Unlabeled (PNU) loss, which jointly exploits labeled, Agreed-Unknown, and Disagreed-Unknown data while mitigating pseudo-label noise. Experiments on benchmark datasets demonstrate that our framework substantially outperforms baselines under limited supervision and approaches the performance of large-scale models
The Imperfect Learner: Incorporating Developmental Trajectories in Memory-based Student Simulation
Nov 08, 2025
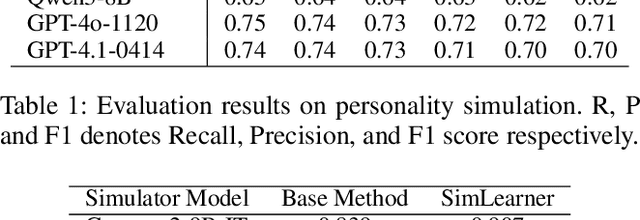
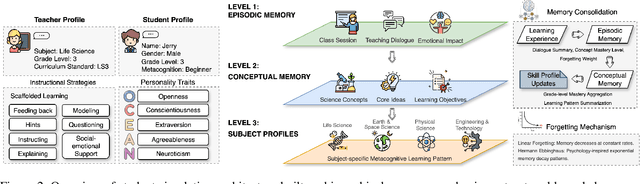
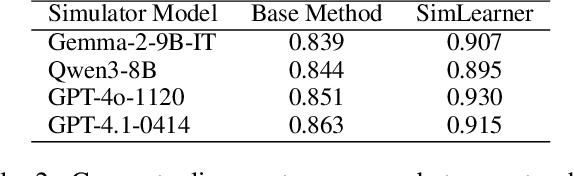
User simulation is important for developing and evaluating human-centered AI, yet current student simulation in educational applications has significant limitations. Existing approaches focus on single learning experiences and do not account for students' gradual knowledge construction and evolving skill sets. Moreover, large language models are optimized to produce direct and accurate responses, making it challenging to represent the incomplete understanding and developmental constraints that characterize real learners. In this paper, we introduce a novel framework for memory-based student simulation that incorporates developmental trajectories through a hierarchical memory mechanism with structured knowledge representation. The framework also integrates metacognitive processes and personality traits to enrich the individual learner profiling, through dynamical consolidation of both cognitive development and personal learning characteristics. In practice, we implement a curriculum-aligned simulator grounded on the Next Generation Science Standards. Experimental results show that our approach can effectively reflect the gradual nature of knowledge development and the characteristic difficulties students face, providing a more accurate representation of learning processes.