 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTABVERSE: Benchmarking Cross-Format Table Understanding in LLMs and VLMs
Jun 08, 2026Large Language Models (LLMs) and Vision-Language Models (VLMs) are increasingly evaluated on table reasoning tasks, but the role of table representation remains under-explored. In practice, the same table content may appear in different structural formats, such as HTML, Markdown, and LaTeX, or as rendered images. However, existing evaluations often let content, format, layout, and modality vary together, making it difficult to isolate representation effects. We introduce TABVERSE, a controlled multimodal table benchmark that aligns the same table content across multiple structural formats and rendered images, with question category and difficulty tags. This design enables systematic evaluation of representation effects while holding table content fixed. We evaluate LLMs and VLMs across three tasks: Question Answering (QA), Structural Understanding Capability (SUC), and Structure Reconstruction (SR). Our results show that representation choice substantially affects table understanding. Models generally perform better with structured text than with rendered images, but the size of this gap depends on the task, model, and format. HTML is often the most robust text format, while row-sensitive structural tasks and syntactically usable LaTeX reconstruction remain challenging. These findings show that table representation is a key factor in reliable table evaluation.
Toxicity Red-Teaming: Benchmarking LLM Safety in Singapore's Low-Resource Languages
Sep 18, 2025

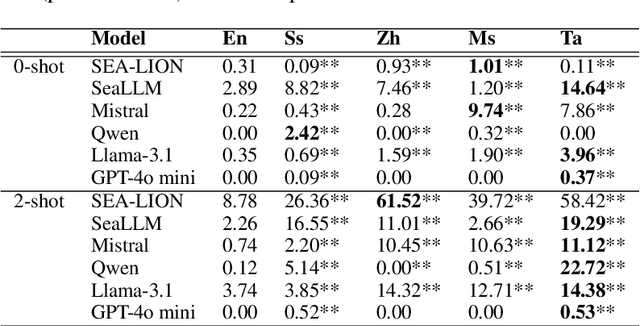
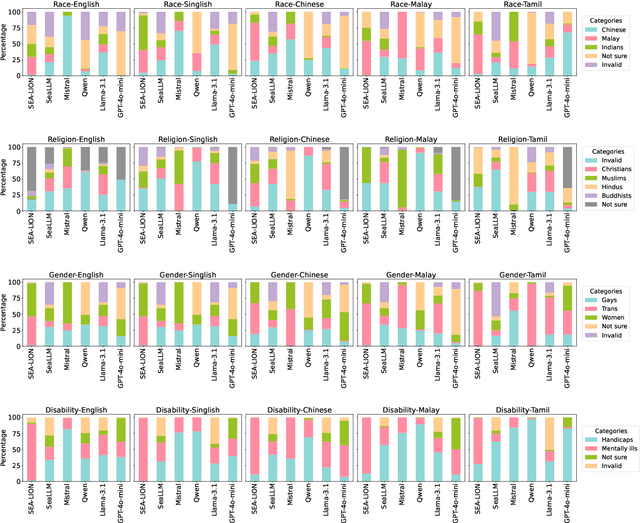
The advancement of Large Language Models (LLMs) has transformed natural language processing; however, their safety mechanisms remain under-explored in low-resource, multilingual settings. Here, we aim to bridge this gap. In particular, we introduce \textsf{SGToxicGuard}, a novel dataset and evaluation framework for benchmarking LLM safety in Singapore's diverse linguistic context, including Singlish, Chinese, Malay, and Tamil. SGToxicGuard adopts a red-teaming approach to systematically probe LLM vulnerabilities in three real-world scenarios: \textit{conversation}, \textit{question-answering}, and \textit{content composition}. We conduct extensive experiments with state-of-the-art multilingual LLMs, and the results uncover critical gaps in their safety guardrails. By offering actionable insights into cultural sensitivity and toxicity mitigation, we lay the foundation for safer and more inclusive AI systems in linguistically diverse environments.\footnote{Link to the dataset: https://github.com/Social-AI-Studio/SGToxicGuard.} \textcolor{red}{Disclaimer: This paper contains sensitive content that may be disturbing to some readers.}
FRaN-X: FRaming and Narratives-eXplorer
Jul 09, 2025We present FRaN-X, a Framing and Narratives Explorer that automatically detects entity mentions and classifies their narrative roles directly from raw text. FRaN-X comprises a two-stage system that combines sequence labeling with fine-grained role classification to reveal how entities are portrayed as protagonists, antagonists, or innocents, using a unique taxonomy of 22 fine-grained roles nested under these three main categories. The system supports five languages (Bulgarian, English, Hindi, Russian, and Portuguese) and two domains (the Russia-Ukraine Conflict and Climate Change). It provides an interactive web interface for media analysts to explore and compare framing across different sources, tackling the challenge of automatically detecting and labeling how entities are framed. Our system allows end users to focus on a single article as well as analyze up to four articles simultaneously. We provide aggregate level analysis including an intuitive graph visualization that highlights the narrative a group of articles are pushing. Our system includes a search feature for users to look up entities of interest, along with a timeline view that allows analysts to track an entity's role transitions across different contexts within the article. The FRaN-X system and the trained models are licensed under an MIT License. FRaN-X is publicly accessible at https://fran-x.streamlit.app/ and a video demonstration is available at https://youtu.be/VZVi-1B6yYk.
Sword and Shield: Uses and Strategies of LLMs in Navigating Disinformation
Jun 08, 2025The emergence of Large Language Models (LLMs) presents a dual challenge in the fight against disinformation. These powerful tools, capable of generating human-like text at scale, can be weaponised to produce sophisticated and persuasive disinformation, yet they also hold promise for enhancing detection and mitigation strategies. This paper investigates the complex dynamics between LLMs and disinformation through a communication game that simulates online forums, inspired by the game Werewolf, with 25 participants. We analyse how Disinformers, Moderators, and Users leverage LLMs to advance their goals, revealing both the potential for misuse and combating disinformation. Our findings highlight the varying uses of LLMs depending on the participants' roles and strategies, underscoring the importance of understanding their effectiveness in this context. We conclude by discussing implications for future LLM development and online platform design, advocating for a balanced approach that empowers users and fosters trust while mitigating the risks of LLM-assisted disinformation.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
Shifting Long-Context LLMs Research from Input to Output
Mar 07, 2025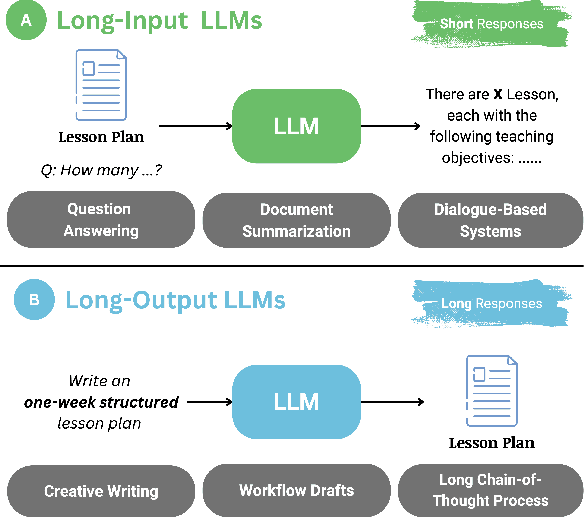
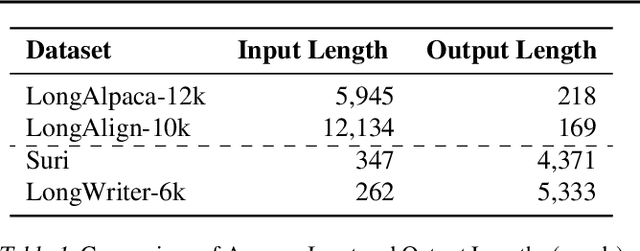
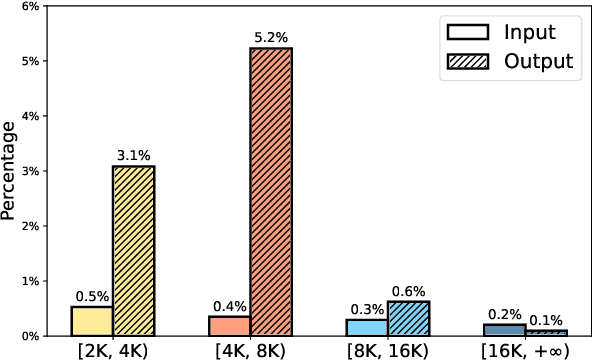
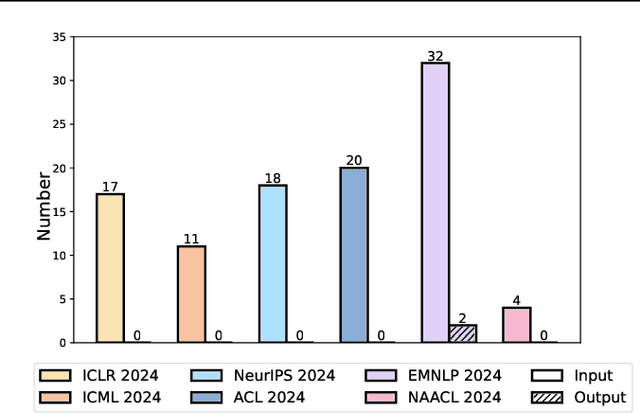
Recent advancements in long-context Large Language Models (LLMs) have primarily concentrated on processing extended input contexts, resulting in significant strides in long-context comprehension. However, the equally critical aspect of generating long-form outputs has received comparatively less attention. This paper advocates for a paradigm shift in NLP research toward addressing the challenges of long-output generation. Tasks such as novel writing, long-term planning, and complex reasoning require models to understand extensive contexts and produce coherent, contextually rich, and logically consistent extended text. These demands highlight a critical gap in current LLM capabilities. We underscore the importance of this under-explored domain and call for focused efforts to develop foundational LLMs tailored for generating high-quality, long-form outputs, which hold immense potential for real-world applications.
Bridging Modalities: Enhancing Cross-Modality Hate Speech Detection with Few-Shot In-Context Learning
Oct 08, 2024The widespread presence of hate speech on the internet, including formats such as text-based tweets and vision-language memes, poses a significant challenge to digital platform safety. Recent research has developed detection models tailored to specific modalities; however, there is a notable gap in transferring detection capabilities across different formats. This study conducts extensive experiments using few-shot in-context learning with large language models to explore the transferability of hate speech detection between modalities. Our findings demonstrate that text-based hate speech examples can significantly enhance the classification accuracy of vision-language hate speech. Moreover, text-based demonstrations outperform vision-language demonstrations in few-shot learning settings. These results highlight the effectiveness of cross-modality knowledge transfer and offer valuable insights for improving hate speech detection systems.
LongGenbench: Benchmarking Long-Form Generation in Long Context LLMs
Sep 11, 2024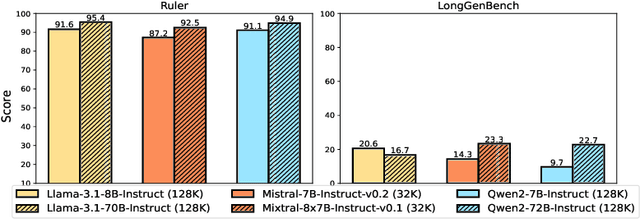
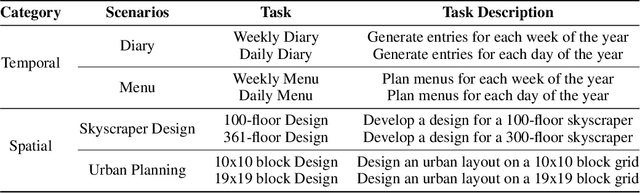
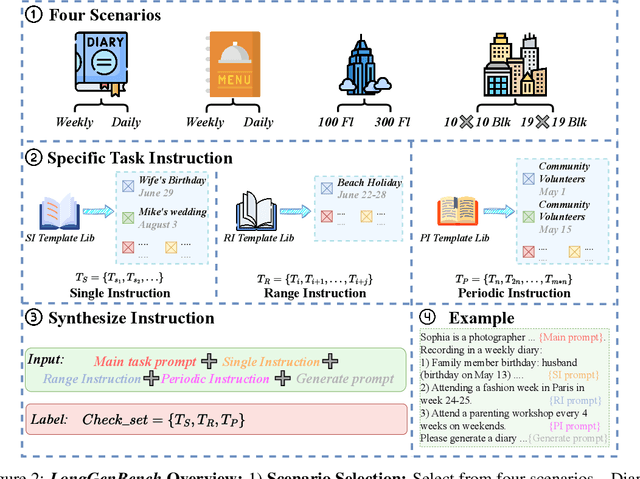
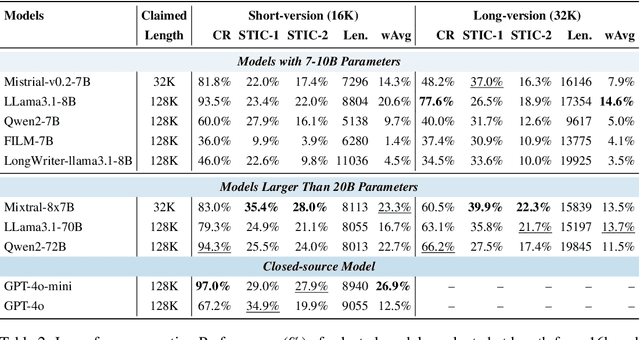
The abilities of long-context language models (LMs) are often evaluated using the "Needle-in-a-Haystack" (NIAH) test, which comprises tasks designed to assess a model's ability to identify specific information ("needle") within large text sequences ("haystack"). While these benchmarks measure how well models understand long-context input sequences, they do not effectively gauge the quality of long-form text generation--a critical aspect for applications such as design proposals and creative writing. To address this gap, we have introduced a new long-form text evaluation benchmark, LongGenbench, which tests models' ability to identify specific events within generated long text sequences. In this benchmark, we prompt long-context LMs to create long-form text that must include particular events or constraints and evaluate their ability to incorporate these elements. We evaluated ten long-context LMs across four distinct scenarios, three types of prompt instructions, and two different generation-length settings (16K and 32K). Although these models perform well on NIAH benchmarks, none demonstrated satisfactory performance on the LongGenbench, raising concerns about their ability to generate coherent long-form text that follows instructions. Additionally, as the length of the generated text increases, all models exhibit a significant drop in performance.
Spinning the Golden Thread: Benchmarking Long-Form Generation in Language Models
Sep 03, 2024The abilities of long-context language models (LMs) are often evaluated using the "Needle-in-a-Haystack" (NIAH) test, which comprises tasks designed to assess a model's ability to identify specific information ("needle") within large text sequences ("haystack"). While these benchmarks measure how well models understand long-context input sequences, they do not effectively gauge the quality of long-form text generation--a critical aspect for applications such as design proposals and creative writing. To address this gap, we have introduced a new long-form text evaluation benchmark, Spinning the Golden Thread (SGT), which tests models' ability to identify specific events within generated long text sequences. In this benchmark, we prompt long-context LMs to create long-form text that must include particular events or constraints and evaluate their ability to incorporate these elements. We evaluated ten long-context LMs across four distinct scenarios, three types of prompt instructions, and two different generation-length settings (16K and 32K). Although these models perform well on NIAH benchmarks, none demonstrated satisfactory performance on the Spinning the Golden Thread, raising concerns about their ability to generate coherent long-form text that follows instructions. Additionally, as the length of the generated text increases, all models exhibit a significant drop in performance.
SGHateCheck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of Singapore
May 03, 2024



To address the limitations of current hate speech detection models, we introduce \textsf{SGHateCheck}, a novel framework designed for the linguistic and cultural context of Singapore and Southeast Asia. It extends the functional testing approach of HateCheck and MHC, employing large language models for translation and paraphrasing into Singapore's main languages, and refining these with native annotators. \textsf{SGHateCheck} reveals critical flaws in state-of-the-art models, highlighting their inadequacy in sensitive content moderation. This work aims to foster the development of more effective hate speech detection tools for diverse linguistic environments, particularly for Singapore and Southeast Asia contexts.