 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrduMMLU: A Massive Multitask Benchmark for Urdu Language Understanding
Jun 05, 2026Meaningful multilingual evaluation must test models in the target language and educational context. Urdu, spoken by more than 230 million people, lacks a broad MMLU-style benchmark built from native educational sources. We introduce UrduMMLU, a benchmark of 26,431 Urdu MCQs across 26 subjects and five domains, collected from native Urdu MCQ banks and public examination PDFs. Unlike translation-based resources, UrduMMLU covers both standard academic subjects and Urdu- and region-specific content. We label the exam-derived portion through dual human annotation with strict consensus filtering. We evaluate 30 LLMs under English and Urdu prompts, yielding 60 zero-shot evaluations, and further evaluate four open-source LLMs under multiple few-shot settings across both prompt languages. Gemini-3.5-Flash performs best, reaching 90.20% and 90.34% accuracy, while no other model exceeds 85%. The strongest open-source model trails by 7.79 and 8.92 points, and many models lose 25 to 40 points on Urdu-centered Humanities subjects compared with STEM. Few-shot prompting yields only modest gains. UrduMMLU shows that Urdu knowledge remains uneven in current LLMs, especially for regionally grounded content.
FRaN-X: FRaming and Narratives-eXplorer
Jul 09, 2025We present FRaN-X, a Framing and Narratives Explorer that automatically detects entity mentions and classifies their narrative roles directly from raw text. FRaN-X comprises a two-stage system that combines sequence labeling with fine-grained role classification to reveal how entities are portrayed as protagonists, antagonists, or innocents, using a unique taxonomy of 22 fine-grained roles nested under these three main categories. The system supports five languages (Bulgarian, English, Hindi, Russian, and Portuguese) and two domains (the Russia-Ukraine Conflict and Climate Change). It provides an interactive web interface for media analysts to explore and compare framing across different sources, tackling the challenge of automatically detecting and labeling how entities are framed. Our system allows end users to focus on a single article as well as analyze up to four articles simultaneously. We provide aggregate level analysis including an intuitive graph visualization that highlights the narrative a group of articles are pushing. Our system includes a search feature for users to look up entities of interest, along with a timeline view that allows analysts to track an entity's role transitions across different contexts within the article. The FRaN-X system and the trained models are licensed under an MIT License. FRaN-X is publicly accessible at https://fran-x.streamlit.app/ and a video demonstration is available at https://youtu.be/VZVi-1B6yYk.
NeuralNexus at BEA 2025 Shared Task: Retrieval-Augmented Prompting for Mistake Identification in AI Tutors
Jun 12, 2025This paper presents our system for Track 1: Mistake Identification in the BEA 2025 Shared Task on Pedagogical Ability Assessment of AI-powered Tutors. The task involves evaluating whether a tutor's response correctly identifies a mistake in a student's mathematical reasoning. We explore four approaches: (1) an ensemble of machine learning models over pooled token embeddings from multiple pretrained language models (LMs); (2) a frozen sentence-transformer using [CLS] embeddings with an MLP classifier; (3) a history-aware model with multi-head attention between token-level history and response embeddings; and (4) a retrieval-augmented few-shot prompting system with a large language model (LLM) i.e. GPT 4o. Our final system retrieves semantically similar examples, constructs structured prompts, and uses schema-guided output parsing to produce interpretable predictions. It outperforms all baselines, demonstrating the effectiveness of combining example-driven prompting with LLM reasoning for pedagogical feedback assessment. Our code is available at https://github.com/NaumanNaeem/BEA_2025.
UrduFactCheck: An Agentic Fact-Checking Framework for Urdu with Evidence Boosting and Benchmarking
May 21, 2025The rapid use of large language models (LLMs) has raised critical concerns regarding the factual reliability of their outputs, especially in low-resource languages such as Urdu. Existing automated fact-checking solutions overwhelmingly focus on English, leaving a significant gap for the 200+ million Urdu speakers worldwide. In this work, we introduce UrduFactCheck, the first comprehensive, modular fact-checking framework specifically tailored for Urdu. Our system features a dynamic, multi-strategy evidence retrieval pipeline that combines monolingual and translation-based approaches to address the scarcity of high-quality Urdu evidence. We curate and release two new hand-annotated benchmarks: UrduFactBench for claim verification and UrduFactQA for evaluating LLM factuality. Extensive experiments demonstrate that UrduFactCheck, particularly its translation-augmented variants, consistently outperforms baselines and open-source alternatives on multiple metrics. We further benchmark twelve state-of-the-art (SOTA) LLMs on factual question answering in Urdu, highlighting persistent gaps between proprietary and open-source models. UrduFactCheck's code and datasets are open-sourced and publicly available at https://github.com/mbzuai-nlp/UrduFactCheck.
PSF-4D: A Progressive Sampling Framework for View Consistent 4D Editing
Mar 14, 2025Instruction-guided generative models, especially those using text-to-image (T2I) and text-to-video (T2V) diffusion frameworks, have advanced the field of content editing in recent years. To extend these capabilities to 4D scene, we introduce a progressive sampling framework for 4D editing (PSF-4D) that ensures temporal and multi-view consistency by intuitively controlling the noise initialization during forward diffusion. For temporal coherence, we design a correlated Gaussian noise structure that links frames over time, allowing each frame to depend meaningfully on prior frames. Additionally, to ensure spatial consistency across views, we implement a cross-view noise model, which uses shared and independent noise components to balance commonalities and distinct details among different views. To further enhance spatial coherence, PSF-4D incorporates view-consistent iterative refinement, embedding view-aware information into the denoising process to ensure aligned edits across frames and views. Our approach enables high-quality 4D editing without relying on external models, addressing key challenges in previous methods. Through extensive evaluation on multiple benchmarks and multiple editing aspects (e.g., style transfer, multi-attribute editing, object removal, local editing, etc.), we show the effectiveness of our proposed method. Experimental results demonstrate that our proposed method outperforms state-of-the-art 4D editing methods in diverse benchmarks.
EVLM: Self-Reflective Multimodal Reasoning for Cross-Dimensional Visual Editing
Dec 13, 2024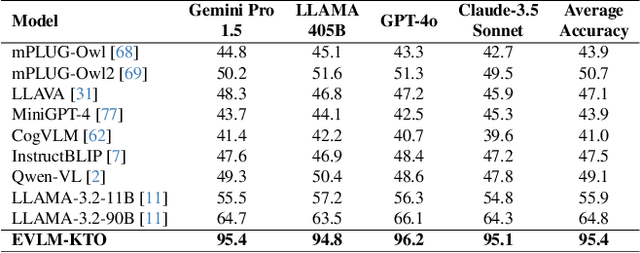



Editing complex visual content based on ambiguous instructions remains a challenging problem in vision-language modeling. While existing models can contextualize content, they often struggle to grasp the underlying intent within a reference image or scene, leading to misaligned edits. We introduce the Editing Vision-Language Model (EVLM), a system designed to interpret such instructions in conjunction with reference visuals, producing precise and context-aware editing prompts. Leveraging Chain-of-Thought (CoT) reasoning and KL-Divergence Target Optimization (KTO) alignment technique, EVLM captures subjective editing preferences without requiring binary labels. Fine-tuned on a dataset of 30,000 CoT examples, with rationale paths rated by human evaluators, EVLM demonstrates substantial improvements in alignment with human intentions. Experiments across image, video, 3D, and 4D editing tasks show that EVLM generates coherent, high-quality instructions, supporting a scalable framework for complex vision-language applications.
LLM-DetectAIve: a Tool for Fine-Grained Machine-Generated Text Detection
Aug 08, 2024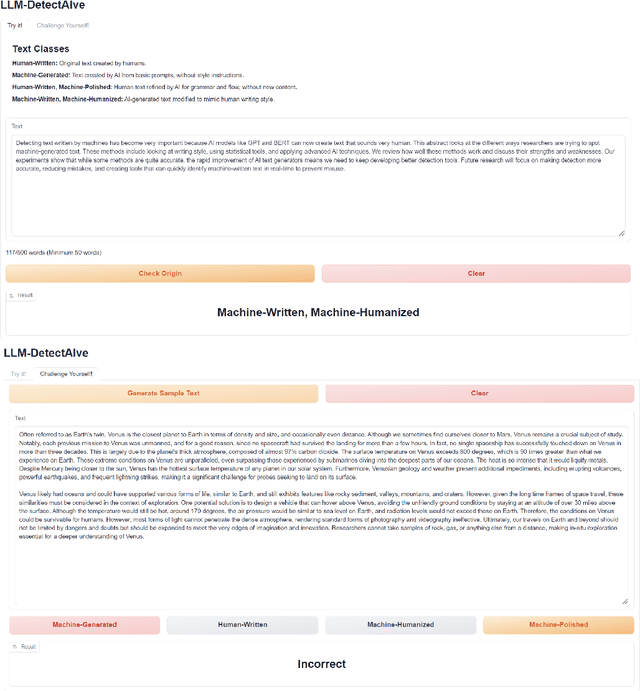
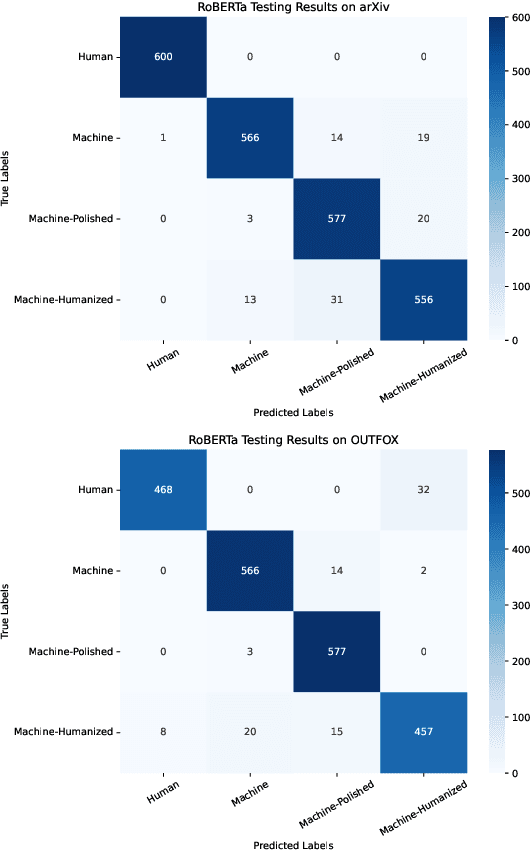
The widespread accessibility of large language models (LLMs) to the general public has significantly amplified the dissemination of machine-generated texts (MGTs). Advancements in prompt manipulation have exacerbated the difficulty in discerning the origin of a text (human-authored vs machinegenerated). This raises concerns regarding the potential misuse of MGTs, particularly within educational and academic domains. In this paper, we present $\textbf{LLM-DetectAIve}$ -- a system designed for fine-grained MGT detection. It is able to classify texts into four categories: human-written, machine-generated, machine-written machine-humanized, and human-written machine-polished. Contrary to previous MGT detectors that perform binary classification, introducing two additional categories in LLM-DetectiAIve offers insights into the varying degrees of LLM intervention during the text creation. This might be useful in some domains like education, where any LLM intervention is usually prohibited. Experiments show that LLM-DetectAIve can effectively identify the authorship of textual content, proving its usefulness in enhancing integrity in education, academia, and other domains. LLM-DetectAIve is publicly accessible at https://huggingface.co/spaces/raj-tomar001/MGT-New. The video describing our system is available at https://youtu.be/E8eT_bE7k8c.
3DEgo: 3D Editing on the Go!
Jul 14, 2024We introduce 3DEgo to address a novel problem of directly synthesizing photorealistic 3D scenes from monocular videos guided by textual prompts. Conventional methods construct a text-conditioned 3D scene through a three-stage process, involving pose estimation using Structure-from-Motion (SfM) libraries like COLMAP, initializing the 3D model with unedited images, and iteratively updating the dataset with edited images to achieve a 3D scene with text fidelity. Our framework streamlines the conventional multi-stage 3D editing process into a single-stage workflow by overcoming the reliance on COLMAP and eliminating the cost of model initialization. We apply a diffusion model to edit video frames prior to 3D scene creation by incorporating our designed noise blender module for enhancing multi-view editing consistency, a step that does not require additional training or fine-tuning of T2I diffusion models. 3DEgo utilizes 3D Gaussian Splatting to create 3D scenes from the multi-view consistent edited frames, capitalizing on the inherent temporal continuity and explicit point cloud data. 3DEgo demonstrates remarkable editing precision, speed, and adaptability across a variety of video sources, as validated by extensive evaluations on six datasets, including our own prepared GS25 dataset. Project Page: https://3dego.github.io/
OpenFactCheck: A Unified Framework for Factuality Evaluation of LLMs
May 09, 2024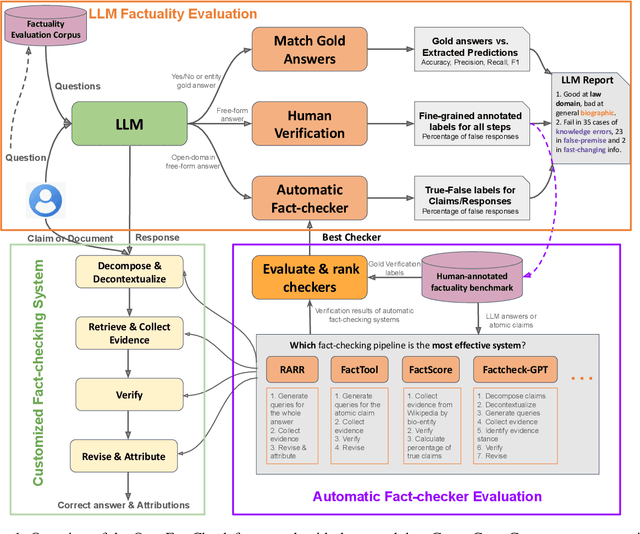

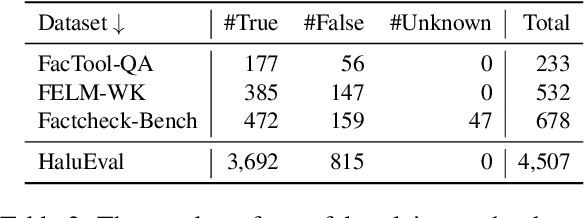
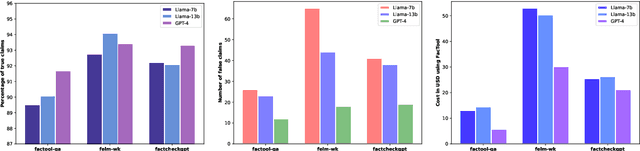
The increased use of large language models (LLMs) across a variety of real-world applications calls for mechanisms to verify the factual accuracy of their outputs. Difficulties lie in assessing the factuality of free-form responses in open domains. Also, different papers use disparate evaluation benchmarks and measurements, which renders them hard to compare and hampers future progress. To mitigate these issues, we propose OpenFactCheck, a unified factuality evaluation framework for LLMs. OpenFactCheck consists of three modules: (i) CUSTCHECKER allows users to easily customize an automatic fact-checker and verify the factual correctness of documents and claims, (ii) LLMEVAL, a unified evaluation framework assesses LLM's factuality ability from various perspectives fairly, and (iii) CHECKEREVAL is an extensible solution for gauging the reliability of automatic fact-checkers' verification results using human-annotated datasets. OpenFactCheck is publicly released at https://github.com/yuxiaw/OpenFactCheck.
Free-Editor: Zero-shot Text-driven 3D Scene Editing
Dec 21, 2023



Text-to-Image (T2I) diffusion models have gained popularity recently due to their multipurpose and easy-to-use nature, e.g. image and video generation as well as editing. However, training a diffusion model specifically for 3D scene editing is not straightforward due to the lack of large-scale datasets. To date, editing 3D scenes requires either re-training the model to adapt to various 3D edited scenes or design-specific methods for each special editing type. Furthermore, state-of-the-art (SOTA) methods require multiple synchronized edited images from the same scene to facilitate the scene editing. Due to the current limitations of T2I models, it is very challenging to apply consistent editing effects to multiple images, i.e. multi-view inconsistency in editing. This in turn compromises the desired 3D scene editing performance if these images are used. In our work, we propose a novel training-free 3D scene editing technique, Free-Editor, which allows users to edit 3D scenes without further re-training the model during test time. Our proposed method successfully avoids the multi-view style inconsistency issue in SOTA methods with the help of a "single-view editing" scheme. Specifically, we show that editing a particular 3D scene can be performed by only modifying a single view. To this end, we introduce an Edit Transformer that enforces intra-view consistency and inter-view style transfer by utilizing self- and cross-attention, respectively. Since it is no longer required to re-train the model and edit every view in a scene, the editing time, as well as memory resources, are reduced significantly, e.g., the runtime being $\sim \textbf{20} \times$ faster than SOTA. We have conducted extensive experiments on a wide range of benchmark datasets and achieve diverse editing capabilities with our proposed technique.