 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRaN-X: FRaming and Narratives-eXplorer
Jul 09, 2025We present FRaN-X, a Framing and Narratives Explorer that automatically detects entity mentions and classifies their narrative roles directly from raw text. FRaN-X comprises a two-stage system that combines sequence labeling with fine-grained role classification to reveal how entities are portrayed as protagonists, antagonists, or innocents, using a unique taxonomy of 22 fine-grained roles nested under these three main categories. The system supports five languages (Bulgarian, English, Hindi, Russian, and Portuguese) and two domains (the Russia-Ukraine Conflict and Climate Change). It provides an interactive web interface for media analysts to explore and compare framing across different sources, tackling the challenge of automatically detecting and labeling how entities are framed. Our system allows end users to focus on a single article as well as analyze up to four articles simultaneously. We provide aggregate level analysis including an intuitive graph visualization that highlights the narrative a group of articles are pushing. Our system includes a search feature for users to look up entities of interest, along with a timeline view that allows analysts to track an entity's role transitions across different contexts within the article. The FRaN-X system and the trained models are licensed under an MIT License. FRaN-X is publicly accessible at https://fran-x.streamlit.app/ and a video demonstration is available at https://youtu.be/VZVi-1B6yYk.
Entity Framing and Role Portrayal in the News
Feb 20, 2025



We introduce a novel multilingual hierarchical corpus annotated for entity framing and role portrayal in news articles. The dataset uses a unique taxonomy inspired by storytelling elements, comprising 22 fine-grained roles, or archetypes, nested within three main categories: protagonist, antagonist, and innocent. Each archetype is carefully defined, capturing nuanced portrayals of entities such as guardian, martyr, and underdog for protagonists; tyrant, deceiver, and bigot for antagonists; and victim, scapegoat, and exploited for innocents. The dataset includes 1,378 recent news articles in five languages (Bulgarian, English, Hindi, European Portuguese, and Russian) focusing on two critical domains of global significance: the Ukraine-Russia War and Climate Change. Over 5,800 entity mentions have been annotated with role labels. This dataset serves as a valuable resource for research into role portrayal and has broader implications for news analysis. We describe the characteristics of the dataset and the annotation process, and we report evaluation results on fine-tuned state-of-the-art multilingual transformers and hierarchical zero-shot learning using LLMs at the level of a document, a paragraph, and a sentence.
Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AI
Feb 17, 2025



Prior studies have shown that distinguishing text generated by large language models (LLMs) from human-written one is highly challenging, and often no better than random guessing. To verify the generalizability of this finding across languages and domains, we perform an extensive case study to identify the upper bound of human detection accuracy. Across 16 datasets covering 9 languages and 9 domains, 19 annotators achieved an average detection accuracy of 87.6%, thus challenging previous conclusions. We find that major gaps between human and machine text lie in concreteness, cultural nuances, and diversity. Prompting by explicitly explaining the distinctions in the prompts can partially bridge the gaps in over 50% of the cases. However, we also find that humans do not always prefer human-written text, particularly when they cannot clearly identify its source.
GenAI Content Detection Task 1: English and Multilingual Machine-Generated Text Detection: AI vs. Human
Jan 19, 2025We present the GenAI Content Detection Task~1 -- a shared task on binary machine generated text detection, conducted as a part of the GenAI workshop at COLING 2025. The task consists of two subtasks: Monolingual (English) and Multilingual. The shared task attracted many participants: 36 teams made official submissions to the Monolingual subtask during the test phase and 26 teams -- to the Multilingual. We provide a comprehensive overview of the data, a summary of the results -- including system rankings and performance scores -- detailed descriptions of the participating systems, and an in-depth analysis of submissions. https://github.com/mbzuai-nlp/COLING-2025-Workshop-on-MGT-Detection-Task1
LLM-DetectAIve: a Tool for Fine-Grained Machine-Generated Text Detection
Aug 08, 2024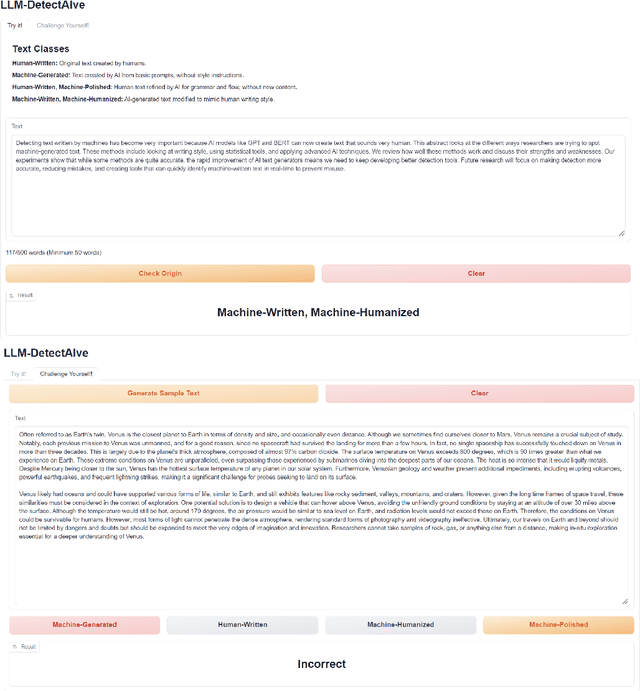
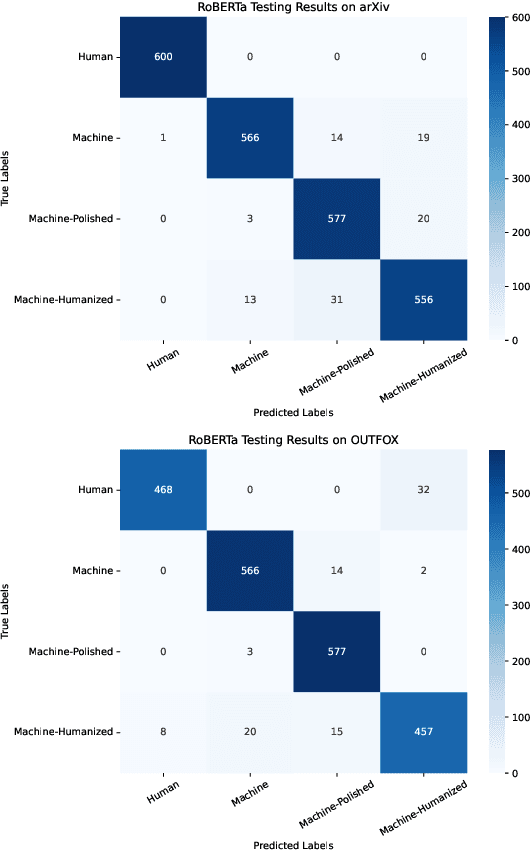
The widespread accessibility of large language models (LLMs) to the general public has significantly amplified the dissemination of machine-generated texts (MGTs). Advancements in prompt manipulation have exacerbated the difficulty in discerning the origin of a text (human-authored vs machinegenerated). This raises concerns regarding the potential misuse of MGTs, particularly within educational and academic domains. In this paper, we present $\textbf{LLM-DetectAIve}$ -- a system designed for fine-grained MGT detection. It is able to classify texts into four categories: human-written, machine-generated, machine-written machine-humanized, and human-written machine-polished. Contrary to previous MGT detectors that perform binary classification, introducing two additional categories in LLM-DetectiAIve offers insights into the varying degrees of LLM intervention during the text creation. This might be useful in some domains like education, where any LLM intervention is usually prohibited. Experiments show that LLM-DetectAIve can effectively identify the authorship of textual content, proving its usefulness in enhancing integrity in education, academia, and other domains. LLM-DetectAIve is publicly accessible at https://huggingface.co/spaces/raj-tomar001/MGT-New. The video describing our system is available at https://youtu.be/E8eT_bE7k8c.
SemEval-2024 Task 8: Multidomain, Multimodel and Multilingual Machine-Generated Text Detection
Apr 22, 2024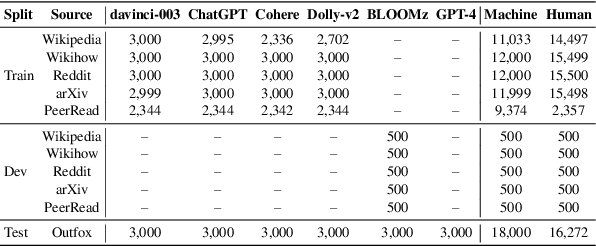

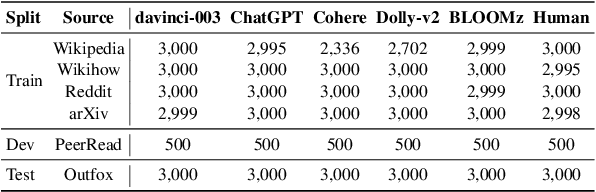

We present the results and the main findings of SemEval-2024 Task 8: Multigenerator, Multidomain, and Multilingual Machine-Generated Text Detection. The task featured three subtasks. Subtask A is a binary classification task determining whether a text is written by a human or generated by a machine. This subtask has two tracks: a monolingual track focused solely on English texts and a multilingual track. Subtask B is to detect the exact source of a text, discerning whether it is written by a human or generated by a specific LLM. Subtask C aims to identify the changing point within a text, at which the authorship transitions from human to machine. The task attracted a large number of participants: subtask A monolingual (126), subtask A multilingual (59), subtask B (70), and subtask C (30). In this paper, we present the task, analyze the results, and discuss the system submissions and the methods they used. For all subtasks, the best systems used LLMs.
* 23 pages, 12 tables
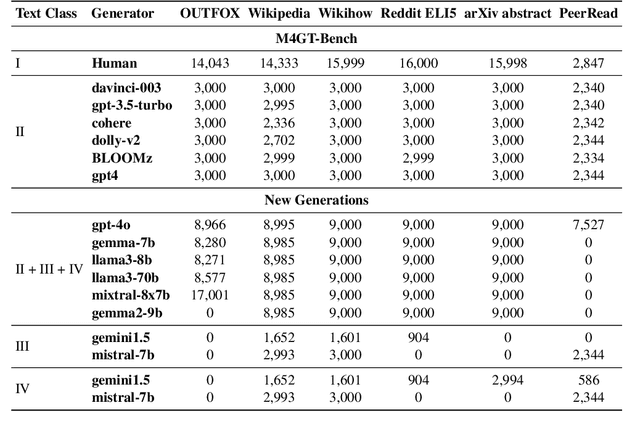
M4GT-Bench: Evaluation Benchmark for Black-Box Machine-Generated Text Detection
Feb 17, 2024



The advent of Large Language Models (LLMs) has brought an unprecedented surge in machine-generated text (MGT) across diverse channels. This raises legitimate concerns about its potential misuse and societal implications. The need to identify and differentiate such content from genuine human-generated text is critical in combating disinformation, preserving the integrity of education and scientific fields, and maintaining trust in communication. In this work, we address this problem by introducing a new benchmark involving multilingual, multi-domain and multi-generator for MGT detection -- M4GT-Bench. It is collected for three task formulations: (1) mono-lingual and multi-lingual binary MGT detection; (2) multi-way detection identifies which particular model generates the text; and (3) human-machine mixed text detection, where a word boundary delimiting MGT from human-written content should be determined. Human evaluation for Task 2 shows less than random guess performance, demonstrating the challenges to distinguish unique LLMs. Promising results always occur when training and test data distribute within the same domain or generators.
M4: Multi-generator, Multi-domain, and Multi-lingual Black-Box Machine-Generated Text Detection
May 24, 2023



Large language models (LLMs) have demonstrated remarkable capability to generate fluent responses to a wide variety of user queries, but this has also resulted in concerns regarding the potential misuse of such texts in journalism, educational, and academic context. In this work, we aim to develop automatic systems to identify machine-generated text and to detect potential misuse. We first introduce a large-scale benchmark M4, which is multi-generator, multi-domain, and multi-lingual corpus for machine-generated text detection. Using the dataset, we experiment with a number of methods and we show that it is challenging for detectors to generalize well on unseen examples if they are either from different domains or are generated by different large language models. In such cases, detectors tend to misclassify machine-generated text as human-written. These results show that the problem is far from solved and there is a lot of room for improvement. We believe that our dataset M4, which covers different generators, domains and languages, will enable future research towards more robust approaches for this pressing societal problem. The M4 dataset is available at https://github.com/mbzuai-nlp/M4.