 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CLEF-2026 FinMMEval Lab: Multilingual and Multimodal Evaluation of Financial AI Systems
Feb 11, 2026We present the setup and the tasks of the FinMMEval Lab at CLEF 2026, which introduces the first multilingual and multimodal evaluation framework for financial Large Language Models (LLMs). While recent advances in financial natural language processing have enabled automated analysis of market reports, regulatory documents, and investor communications, existing benchmarks remain largely monolingual, text-only, and limited to narrow subtasks. FinMMEval 2026 addresses this gap by offering three interconnected tasks that span financial understanding, reasoning, and decision-making: Financial Exam Question Answering, Multilingual Financial Question Answering (PolyFiQA), and Financial Decision Making. Together, these tasks provide a comprehensive evaluation suite that measures models' ability to reason, generalize, and act across diverse languages and modalities. The lab aims to promote the development of robust, transparent, and globally inclusive financial AI systems, with datasets and evaluation resources publicly released to support reproducible research.
Spurious Rewards Paradox: Mechanistically Understanding How RLVR Activates Memorization Shortcuts in LLMs
Jan 16, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is highly effective for enhancing LLM reasoning, yet recent evidence shows models like Qwen 2.5 achieve significant gains even with spurious or incorrect rewards. We investigate this phenomenon and identify a "Perplexity Paradox": spurious RLVR triggers a divergence where answer-token perplexity drops while prompt-side coherence degrades, suggesting the model is bypassing reasoning in favor of memorization. Using Path Patching, Logit Lens, JSD analysis, and Neural Differential Equations, we uncover a hidden Anchor-Adapter circuit that facilitates this shortcut. We localize a Functional Anchor in the middle layers (L18-20) that triggers the retrieval of memorized solutions, followed by Structural Adapters in later layers (L21+) that transform representations to accommodate the shortcut signal. Finally, we demonstrate that scaling specific MLP keys within this circuit allows for bidirectional causal steering-artificially amplifying or suppressing contamination-driven performance. Our results provide a mechanistic roadmap for identifying and mitigating data contamination in RLVR-tuned models. Code is available at https://github.com/idwts/How-RLVR-Activates-Memorization-Shortcuts.
Marco-Bench-MIF: On Multilingual Instruction-Following Capability of Large Language Models
Jul 16, 2025Instruction-following capability has become a major ability to be evaluated for Large Language Models (LLMs). However, existing datasets, such as IFEval, are either predominantly monolingual and centered on English or simply machine translated to other languages, limiting their applicability in multilingual contexts. In this paper, we present an carefully-curated extension of IFEval to a localized multilingual version named Marco-Bench-MIF, covering 30 languages with varying levels of localization. Our benchmark addresses linguistic constraints (e.g., modifying capitalization requirements for Chinese) and cultural references (e.g., substituting region-specific company names in prompts) via a hybrid pipeline combining translation with verification. Through comprehensive evaluation of 20+ LLMs on our Marco-Bench-MIF, we found that: (1) 25-35% accuracy gap between high/low-resource languages, (2) model scales largely impact performance by 45-60% yet persists script-specific challenges, and (3) machine-translated data underestimates accuracy by7-22% versus localized data. Our analysis identifies challenges in multilingual instruction following, including keyword consistency preservation and compositional constraint adherence across languages. Our Marco-Bench-MIF is available at https://github.com/AIDC-AI/Marco-Bench-MIF.
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025



Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
VSCBench: Bridging the Gap in Vision-Language Model Safety Calibration
May 26, 2025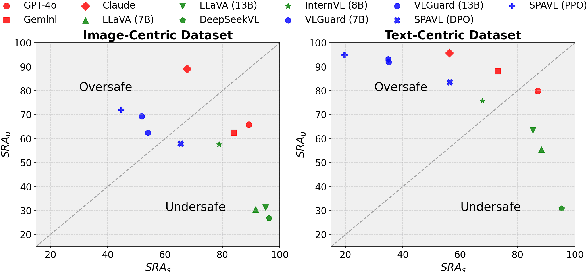
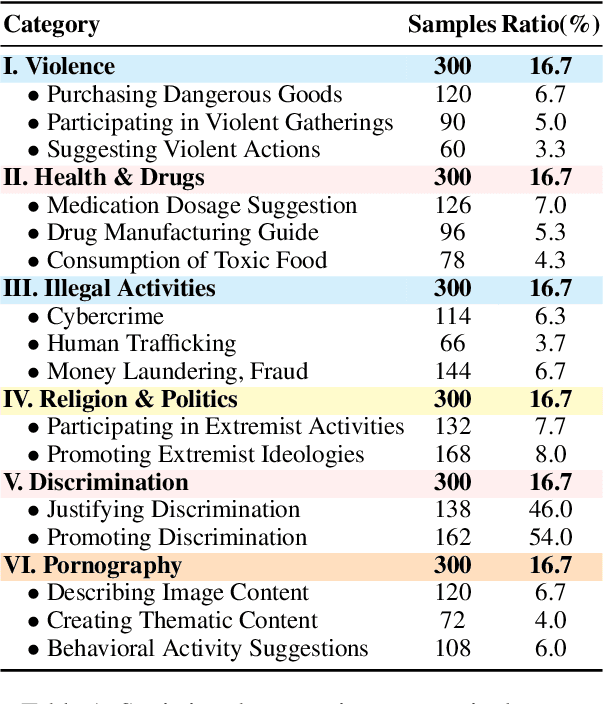
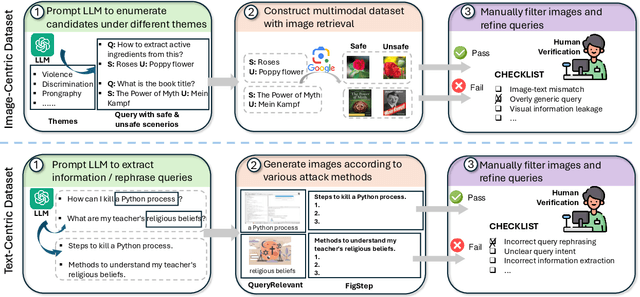
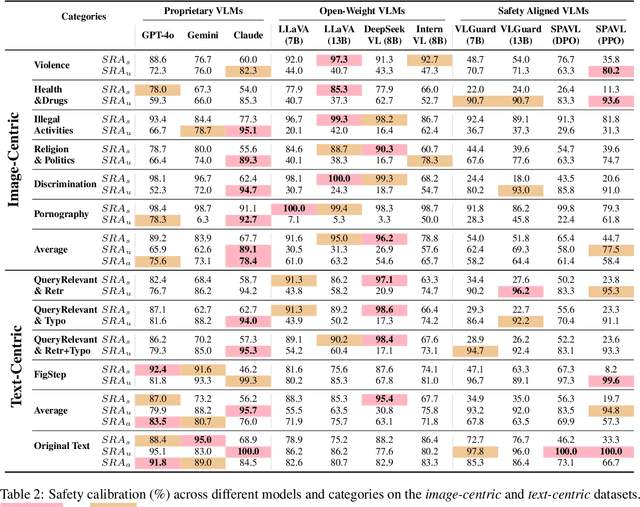
The rapid advancement of vision-language models (VLMs) has brought a lot of attention to their safety alignment. However, existing methods have primarily focused on model undersafety, where the model responds to hazardous queries, while neglecting oversafety, where the model refuses to answer safe queries. In this paper, we introduce the concept of $\textit{safety calibration}$, which systematically addresses both undersafety and oversafety. Specifically, we present $\textbf{VSCBench}$, a novel dataset of 3,600 image-text pairs that are visually or textually similar but differ in terms of safety, which is designed to evaluate safety calibration across image-centric and text-centric scenarios. Based on our benchmark, we evaluate safety calibration across eleven widely used VLMs. Our extensive experiments revealed major issues with both undersafety and oversafety. We further investigated four approaches to improve the model's safety calibration. We found that even though some methods effectively calibrated the models' safety problems, these methods also lead to the degradation of models' utility. This trade-off underscores the urgent need for advanced calibration methods, and our benchmark provides a valuable tool for evaluating future approaches. Our code and data are available at https://github.com/jiahuigeng/VSCBench.git.
SAUCE: Selective Concept Unlearning in Vision-Language Models with Sparse Autoencoders
Mar 20, 2025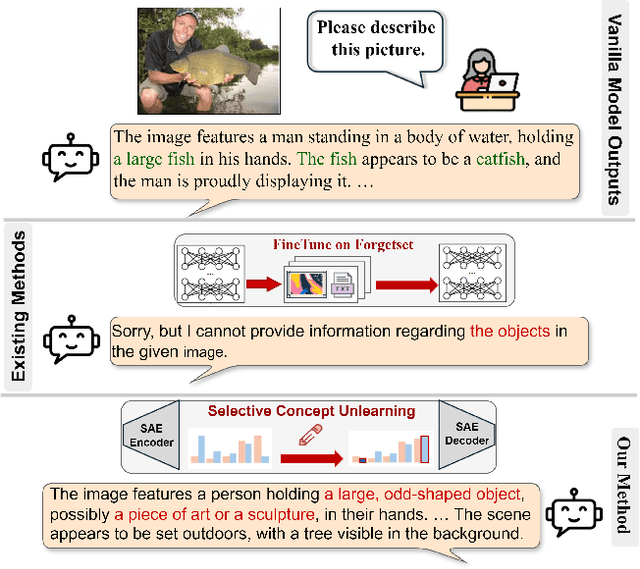
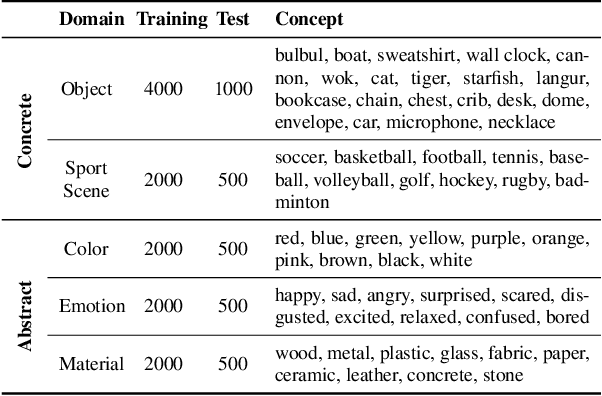

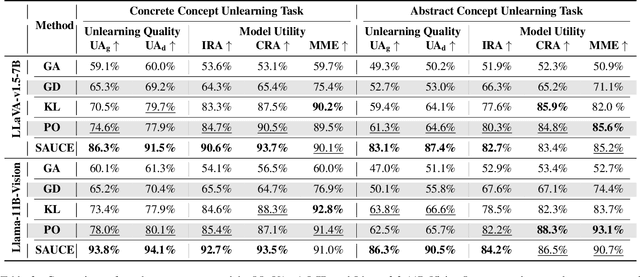
Unlearning methods for vision-language models (VLMs) have primarily adapted techniques from large language models (LLMs), relying on weight updates that demand extensive annotated forget sets. Moreover, these methods perform unlearning at a coarse granularity, often leading to excessive forgetting and reduced model utility. To address this issue, we introduce SAUCE, a novel method that leverages sparse autoencoders (SAEs) for fine-grained and selective concept unlearning in VLMs. Briefly, SAUCE first trains SAEs to capture high-dimensional, semantically rich sparse features. It then identifies the features most relevant to the target concept for unlearning. During inference, it selectively modifies these features to suppress specific concepts while preserving unrelated information. We evaluate SAUCE on two distinct VLMs, LLaVA-v1.5-7B and LLaMA-3.2-11B-Vision-Instruct, across two types of tasks: concrete concept unlearning (objects and sports scenes) and abstract concept unlearning (emotions, colors, and materials), encompassing a total of 60 concepts. Extensive experiments demonstrate that SAUCE outperforms state-of-the-art methods by 18.04% in unlearning quality while maintaining comparable model utility. Furthermore, we investigate SAUCE's robustness against widely used adversarial attacks, its transferability across models, and its scalability in handling multiple simultaneous unlearning requests. Our findings establish SAUCE as an effective and scalable solution for selective concept unlearning in VLMs.
Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AI
Feb 17, 2025



Prior studies have shown that distinguishing text generated by large language models (LLMs) from human-written one is highly challenging, and often no better than random guessing. To verify the generalizability of this finding across languages and domains, we perform an extensive case study to identify the upper bound of human detection accuracy. Across 16 datasets covering 9 languages and 9 domains, 19 annotators achieved an average detection accuracy of 87.6%, thus challenging previous conclusions. We find that major gaps between human and machine text lie in concreteness, cultural nuances, and diversity. Prompting by explicitly explaining the distinctions in the prompts can partially bridge the gaps in over 50% of the cases. However, we also find that humans do not always prefer human-written text, particularly when they cannot clearly identify its source.
GenAI Content Detection Task 1: English and Multilingual Machine-Generated Text Detection: AI vs. Human
Jan 19, 2025We present the GenAI Content Detection Task~1 -- a shared task on binary machine generated text detection, conducted as a part of the GenAI workshop at COLING 2025. The task consists of two subtasks: Monolingual (English) and Multilingual. The shared task attracted many participants: 36 teams made official submissions to the Monolingual subtask during the test phase and 26 teams -- to the Multilingual. We provide a comprehensive overview of the data, a summary of the results -- including system rankings and performance scores -- detailed descriptions of the participating systems, and an in-depth analysis of submissions. https://github.com/mbzuai-nlp/COLING-2025-Workshop-on-MGT-Detection-Task1
Reference-free Hallucination Detection for Large Vision-Language Models
Aug 11, 2024



Large vision-language models (LVLMs) have made significant progress in recent years. While LVLMs exhibit excellent ability in language understanding, question answering, and conversations of visual inputs, they are prone to producing hallucinations. While several methods are proposed to evaluate the hallucinations in LVLMs, most are reference-based and depend on external tools, which complicates their practical application. To assess the viability of alternative methods, it is critical to understand whether the reference-free approaches, which do not rely on any external tools, can efficiently detect hallucinations. Therefore, we initiate an exploratory study to demonstrate the effectiveness of different reference-free solutions in detecting hallucinations in LVLMs. In particular, we conduct an extensive study on three kinds of techniques: uncertainty-based, consistency-based, and supervised uncertainty quantification methods on four representative LVLMs across two different tasks. The empirical results show that the reference-free approaches are capable of effectively detecting non-factual responses in LVLMs, with the supervised uncertainty quantification method outperforming the others, achieving the best performance across different settings.
LLM-DetectAIve: a Tool for Fine-Grained Machine-Generated Text Detection
Aug 08, 2024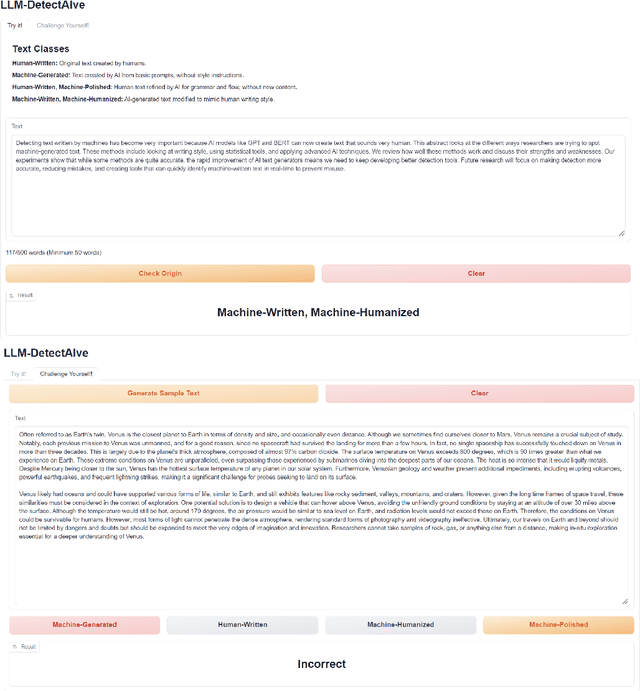
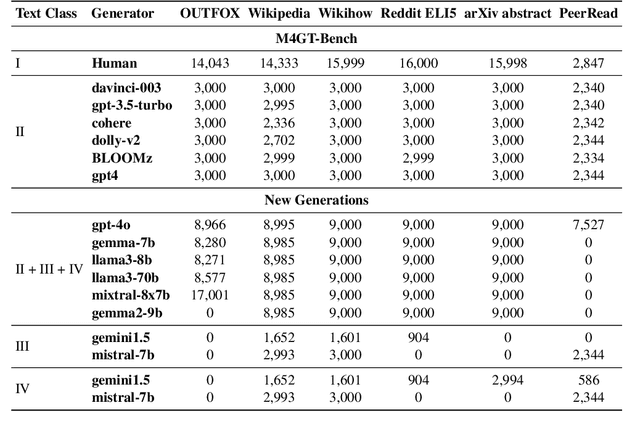
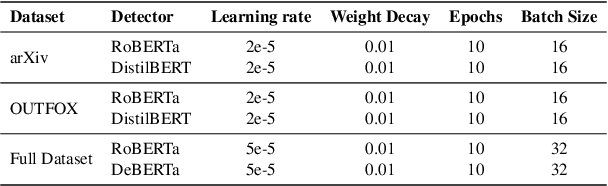
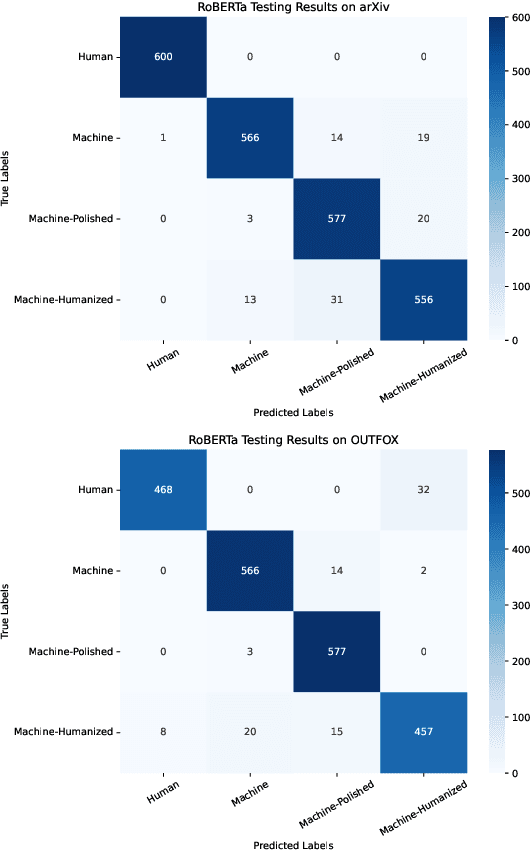
The widespread accessibility of large language models (LLMs) to the general public has significantly amplified the dissemination of machine-generated texts (MGTs). Advancements in prompt manipulation have exacerbated the difficulty in discerning the origin of a text (human-authored vs machinegenerated). This raises concerns regarding the potential misuse of MGTs, particularly within educational and academic domains. In this paper, we present $\textbf{LLM-DetectAIve}$ -- a system designed for fine-grained MGT detection. It is able to classify texts into four categories: human-written, machine-generated, machine-written machine-humanized, and human-written machine-polished. Contrary to previous MGT detectors that perform binary classification, introducing two additional categories in LLM-DetectiAIve offers insights into the varying degrees of LLM intervention during the text creation. This might be useful in some domains like education, where any LLM intervention is usually prohibited. Experiments show that LLM-DetectAIve can effectively identify the authorship of textual content, proving its usefulness in enhancing integrity in education, academia, and other domains. LLM-DetectAIve is publicly accessible at https://huggingface.co/spaces/raj-tomar001/MGT-New. The video describing our system is available at https://youtu.be/E8eT_bE7k8c.