 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarco-Bench-MIF: On Multilingual Instruction-Following Capability of Large Language Models
Jul 16, 2025Instruction-following capability has become a major ability to be evaluated for Large Language Models (LLMs). However, existing datasets, such as IFEval, are either predominantly monolingual and centered on English or simply machine translated to other languages, limiting their applicability in multilingual contexts. In this paper, we present an carefully-curated extension of IFEval to a localized multilingual version named Marco-Bench-MIF, covering 30 languages with varying levels of localization. Our benchmark addresses linguistic constraints (e.g., modifying capitalization requirements for Chinese) and cultural references (e.g., substituting region-specific company names in prompts) via a hybrid pipeline combining translation with verification. Through comprehensive evaluation of 20+ LLMs on our Marco-Bench-MIF, we found that: (1) 25-35% accuracy gap between high/low-resource languages, (2) model scales largely impact performance by 45-60% yet persists script-specific challenges, and (3) machine-translated data underestimates accuracy by7-22% versus localized data. Our analysis identifies challenges in multilingual instruction following, including keyword consistency preservation and compositional constraint adherence across languages. Our Marco-Bench-MIF is available at https://github.com/AIDC-AI/Marco-Bench-MIF.
Towards Widening The Distillation Bottleneck for Reasoning Models
Mar 03, 2025Large Reasoning Models(LRMs) such as OpenAI o1 and DeepSeek-R1 have shown remarkable reasoning capabilities by scaling test-time compute and generating long Chain-of-Thought(CoT). Distillation--post-training on LRMs-generated data--is a straightforward yet effective method to enhance the reasoning abilities of smaller models, but faces a critical bottleneck: we found that distilled long CoT data poses learning difficulty for small models and leads to the inheritance of biases (i.e. over-thinking) when using Supervised Fine-tuning(SFT) and Reinforcement Learning(RL) methods. To alleviate this bottleneck, we propose constructing tree-based CoT data from scratch via Monte Carlo Tree Search(MCTS). We then exploit a set of CoT-aware approaches, including Thoughts Length Balance, Fine-grained DPO, and Joint Post-training Objective, to enhance SFT and RL on the construted data.
DBudgetKV: Dynamic Budget in KV Cache Compression for Ensuring Optimal Performance
Feb 24, 2025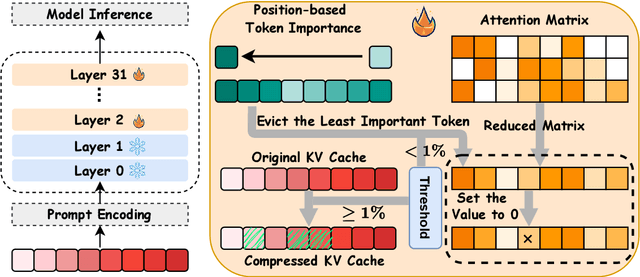
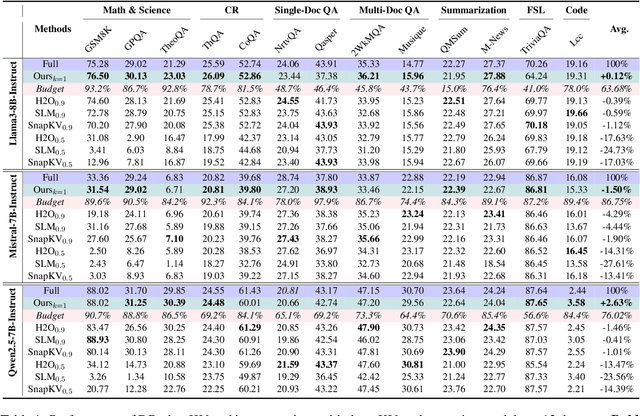
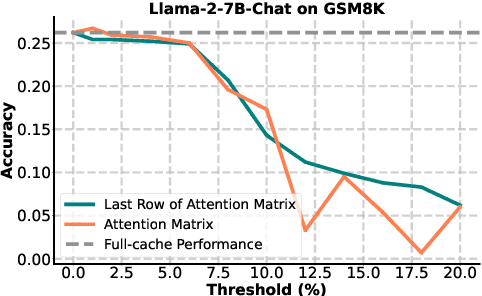
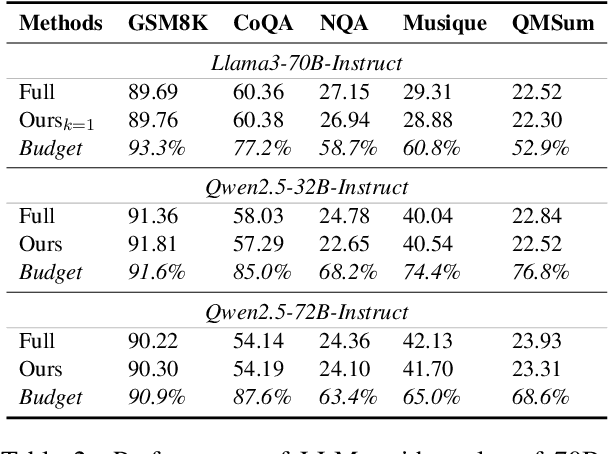
To alleviate memory burden during inference of large language models (LLMs), numerous studies have focused on compressing the KV cache by exploring aspects such as attention sparsity. However, these techniques often require a pre-defined cache budget; as the optimal budget varies with different input lengths and task types, it limits their practical deployment accepting open-domain instructions. To address this limitation, we propose a new KV cache compression objective: to always ensure the full-cache performance regardless of specific inputs, while maximizing KV cache pruning as much as possible. To achieve this goal, we introduce a novel KV cache compression method dubbed DBudgetKV, which features an attention-based metric to signal when the remaining KV cache is unlikely to match the full-cache performance, then halting the pruning process. Empirical evaluation spanning diverse context lengths, task types, and model sizes suggests that our method achieves lossless KV pruning effectively and robustly, exceeding 25% compression ratio on average. Furthermore, our method is easy to integrate within LLM inference, not only optimizing memory space, but also showing reduced inference time compared to existing methods.
XL$^2$Bench: A Benchmark for Extremely Long Context Understanding with Long-range Dependencies
Apr 08, 2024Large Language Models (LLMs) have demonstrated remarkable performance across diverse tasks but are constrained by their small context window sizes. Various efforts have been proposed to expand the context window to accommodate even up to 200K input tokens. Meanwhile, building high-quality benchmarks with much longer text lengths and more demanding tasks to provide comprehensive evaluations is of immense practical interest to facilitate long context understanding research of LLMs. However, prior benchmarks create datasets that ostensibly cater to long-text comprehension by expanding the input of traditional tasks, which falls short to exhibit the unique characteristics of long-text understanding, including long dependency tasks and longer text length compatible with modern LLMs' context window size. In this paper, we introduce a benchmark for extremely long context understanding with long-range dependencies, XL$^2$Bench, which includes three scenarios: Fiction Reading, Paper Reading, and Law Reading, and four tasks of increasing complexity: Memory Retrieval, Detailed Understanding, Overall Understanding, and Open-ended Generation, covering 27 subtasks in English and Chinese. It has an average length of 100K+ words (English) and 200K+ characters (Chinese). Evaluating six leading LLMs on XL$^2$Bench, we find that their performance significantly lags behind human levels. Moreover, the observed decline in performance across both the original and enhanced datasets underscores the efficacy of our approach to mitigating data contamination.
Unified Text Structuralization with Instruction-tuned Language Models
Mar 30, 2023Text structuralization is one of the important fields of natural language processing (NLP) consists of information extraction (IE) and structure formalization. However, current studies of text structuralization suffer from a shortage of manually annotated high-quality datasets from different domains and languages, which require specialized professional knowledge. In addition, most IE methods are designed for a specific type of structured data, e.g., entities, relations, and events, making them hard to generalize to others. In this work, we propose a simple and efficient approach to instruct large language model (LLM) to extract a variety of structures from texts. More concretely, we add a prefix and a suffix instruction to indicate the desired IE task and structure type, respectively, before feeding the text into a LLM. Experiments on two LLMs show that this approach can enable language models to perform comparable with other state-of-the-art methods on datasets of a variety of languages and knowledge, and can generalize to other IE sub-tasks via changing the content of instruction. Another benefit of our approach is that it can help researchers to build datasets in low-source and domain-specific scenarios, e.g., fields in finance and law, with low cost.