 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Guidance for Large Language Models
Jan 29, 2026Contrastive Decoding (CD) enhances the generation quality of large language models (LLMs) but incurs significant additional computational overhead due to the need for an auxiliary model. Existing internal self-contrastive decoding methods, such as Decoding by Contrasting Layers (DoLa), focus on discrepancies across different layers, which are notably unstable on small-scale models. In this work, based on the observation that LLMs exhibit local preferences, we propose a novel contrastive guidance strategy along the temporal dimension, namely Temporal Guidance (TeGu). Our method ingeniously leverages Multi-Token Prediction (MTP) to construct weaker amateur predictions for model self-contrast. To standardize the implementation of this mechanism, we further introduce a lightweight Conditional MTP Projector (cMTPP), which avoids maintaining multiple independent networks as required by other MTP modules. Across various model series and benchmarks, TeGu achieves significant performance improvements while maintaining low additional memory consumption and computational overhead.
Hallucination Mitigating for Medical Report Generation
Jan 22, 2026In the realm of medical report generation (MRG), the integration of natural language processing has emerged as a vital tool to alleviate the workload of radiologists. Despite the impressive capabilities demonstrated by large vision language models (LVLMs) in understanding natural language, their susceptibility to generating plausible yet inaccurate claims, known as ``hallucinations'', raises concerns-especially in the nuanced and critical field of medical. In this work, we introduce a framework, \textbf{K}nowledge-\textbf{E}nhanced with Fine-Grained \textbf{R}einforced Rewards \textbf{M}edical Report Generation (KERM), to tackle the issue. Our approach refines the input to the LVLM by first utilizing MedCLIP for knowledge retrieval, incorporating relevant lesion fact sentences from a curated knowledge corpus. We then introduce a novel purification module to ensure the retrieved knowledge is contextually relevant to the patient's clinical context. Subsequently, we employ fine-grained rewards to guide these models in generating highly supportive and clinically relevant descriptions, ensuring the alignment of model's outputs with desired behaviors. Experimental results on IU-Xray and MIMIC-CXR datasets validate the effectiveness of our approach in mitigating hallucinations and enhancing report quality.
Retrieval-augmented Prompt Learning for Pre-trained Foundation Models
Dec 23, 2025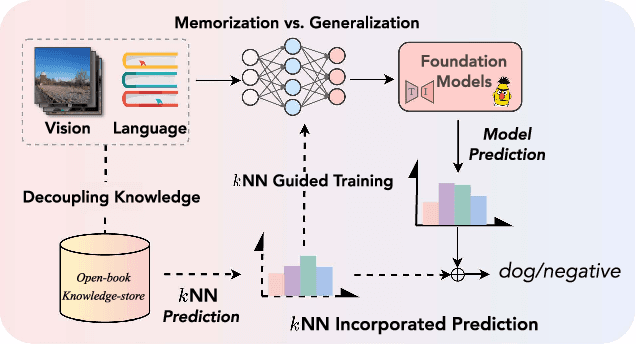
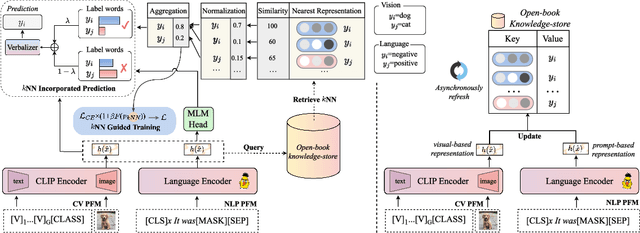
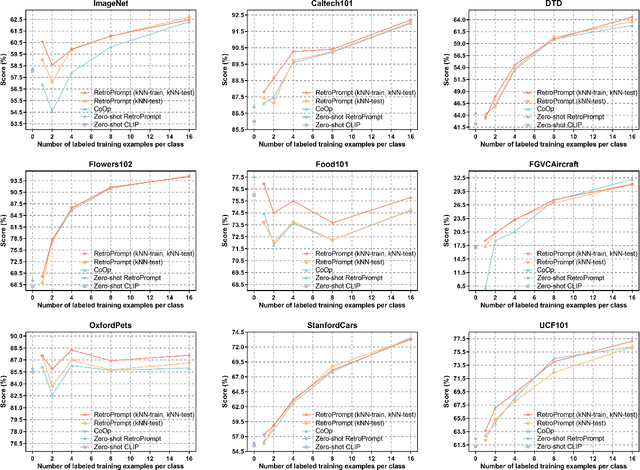
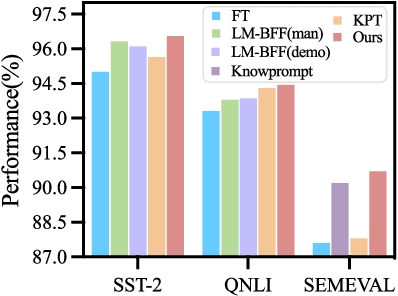
The pre-trained foundation models (PFMs) have become essential for facilitating large-scale multimodal learning. Researchers have effectively employed the ``pre-train, prompt, and predict'' paradigm through prompt learning to induce improved few-shot performance. However, prompt learning approaches for PFMs still follow a parametric learning paradigm. As such, the stability of generalization in memorization and rote learning can be compromised. More specifically, conventional prompt learning might face difficulties in fully utilizing atypical instances and avoiding overfitting to shallow patterns with limited data during the process of fully-supervised training. To overcome these constraints, we present our approach, named RetroPrompt, which aims to achieve a balance between memorization and generalization by decoupling knowledge from mere memorization. Unlike traditional prompting methods, RetroPrompt leverages a publicly accessible knowledge base generated from the training data and incorporates a retrieval mechanism throughout the input, training, and inference stages. This enables the model to actively retrieve relevant contextual information from the corpus, thereby enhancing the available cues. We conduct comprehensive experiments on a variety of datasets across natural language processing and computer vision tasks to demonstrate the superior performance of our proposed approach, RetroPrompt, in both zero-shot and few-shot scenarios. Through detailed analysis of memorization patterns, we observe that RetroPrompt effectively reduces the reliance on rote memorization, leading to enhanced generalization.
M-BRe: Discovering Training Samples for Relation Extraction from Unlabeled Texts with Large Language Models
Sep 10, 2025For Relation Extraction (RE), the manual annotation of training data may be prohibitively expensive, since the sentences that contain the target relations in texts can be very scarce and difficult to find. It is therefore beneficial to develop an efficient method that can automatically extract training instances from unlabeled texts for training RE models. Recently, large language models (LLMs) have been adopted in various natural language processing tasks, with RE also benefiting from their advances. However, when leveraging LLMs for RE with predefined relation categories, two key challenges arise. First, in a multi-class classification setting, LLMs often struggle to comprehensively capture the semantics of every relation, leading to suboptimal results. Second, although employing binary classification for each relation individually can mitigate this issue, it introduces significant computational overhead, resulting in impractical time complexity for real-world applications. Therefore, this paper proposes a framework called M-BRe to extract training instances from unlabeled texts for RE. It utilizes three modules to combine the advantages of both of the above classification approaches: Relation Grouping, Relation Extraction, and Label Decision. Extensive experiments confirm its superior capability in discovering high-quality training samples from unlabeled texts for RE.
Investigating Advanced Reasoning of Large Language Models via Black-Box Interaction
Aug 26, 2025Existing tasks fall short in evaluating reasoning ability of Large Language Models (LLMs) in an interactive, unknown environment. This deficiency leads to the isolated assessment of deductive, inductive, and abductive reasoning, neglecting the integrated reasoning process that is indispensable for humans discovery of real world. We introduce a novel evaluation paradigm, \textit{black-box interaction}, to tackle this challenge. A black-box is defined by a hidden function that maps a specific set of inputs to outputs. LLMs are required to unravel the hidden function behind the black-box by interacting with it in given exploration turns, and reasoning over observed input-output pairs. Leveraging this idea, we build the \textsc{Oracle} benchmark which comprises 6 types of black-box task and 96 black-boxes. 19 modern LLMs are benchmarked. o3 ranks first in 5 of the 6 tasks, achieving over 70\% accuracy on most easy black-boxes. But it still struggles with some hard black-box tasks, where its average performance drops below 40\%. Further analysis indicates a universal difficulty among LLMs: They lack the high-level planning capability to develop efficient and adaptive exploration strategies for hypothesis refinement.
Improving Brain-to-Image Reconstruction via Fine-Grained Text Bridging
May 29, 2025Brain-to-Image reconstruction aims to recover visual stimuli perceived by humans from brain activity. However, the reconstructed visual stimuli often missing details and semantic inconsistencies, which may be attributed to insufficient semantic information. To address this issue, we propose an approach named Fine-grained Brain-to-Image reconstruction (FgB2I), which employs fine-grained text as bridge to improve image reconstruction. FgB2I comprises three key stages: detail enhancement, decoding fine-grained text descriptions, and text-bridged brain-to-image reconstruction. In the detail-enhancement stage, we leverage large vision-language models to generate fine-grained captions for visual stimuli and experimentally validate its importance. We propose three reward metrics (object accuracy, text-image semantic similarity, and image-image semantic similarity) to guide the language model in decoding fine-grained text descriptions from fMRI signals. The fine-grained text descriptions can be integrated into existing reconstruction methods to achieve fine-grained Brain-to-Image reconstruction.
Generating Diverse Training Samples for Relation Extraction with Large Language Models
May 29, 2025Using Large Language Models (LLMs) to generate training data can potentially be a preferable way to improve zero or few-shot NLP tasks. However, many problems remain to be investigated for this direction. For the task of Relation Extraction (RE), we find that samples generated by directly prompting LLMs may easily have high structural similarities with each other. They tend to use a limited variety of phrasing while expressing the relation between a pair of entities. Therefore, in this paper, we study how to effectively improve the diversity of the training samples generated with LLMs for RE, while also maintaining their correctness. We first try to make the LLMs produce dissimilar samples by directly giving instructions in In-Context Learning (ICL) prompts. Then, we propose an approach to fine-tune LLMs for diversity training sample generation through Direct Preference Optimization (DPO). Our experiments on commonly used RE datasets show that both attempts can improve the quality of the generated training data. We also find that comparing with directly performing RE with an LLM, training a non-LLM RE model with its generated samples may lead to better performance.
Improve Language Model and Brain Alignment via Associative Memory
May 20, 2025Associative memory engages in the integration of relevant information for comprehension in the human cognition system. In this work, we seek to improve alignment between language models and human brain while processing speech information by integrating associative memory. After verifying the alignment between language model and brain by mapping language model activations to brain activity, the original text stimuli expanded with simulated associative memory are regarded as input to computational language models. We find the alignment between language model and brain is improved in brain regions closely related to associative memory processing. We also demonstrate large language models after specific supervised fine-tuning better align with brain response, by building the \textit{Association} dataset containing 1000 samples of stories, with instructions encouraging associative memory as input and associated content as output.
DBudgetKV: Dynamic Budget in KV Cache Compression for Ensuring Optimal Performance
Feb 24, 2025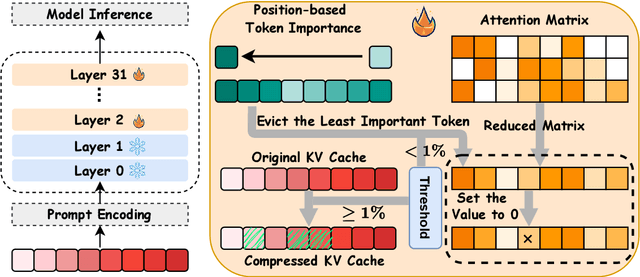
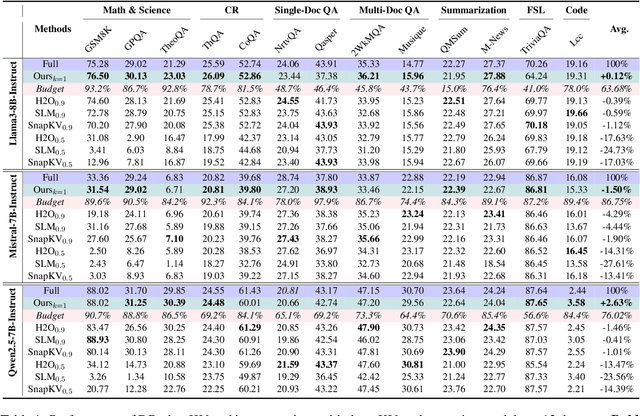
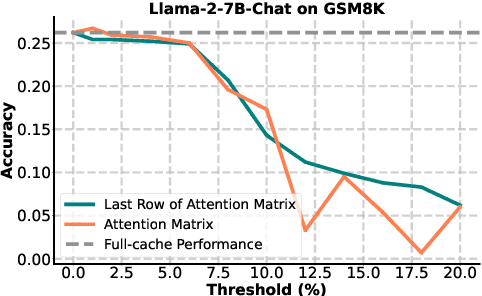
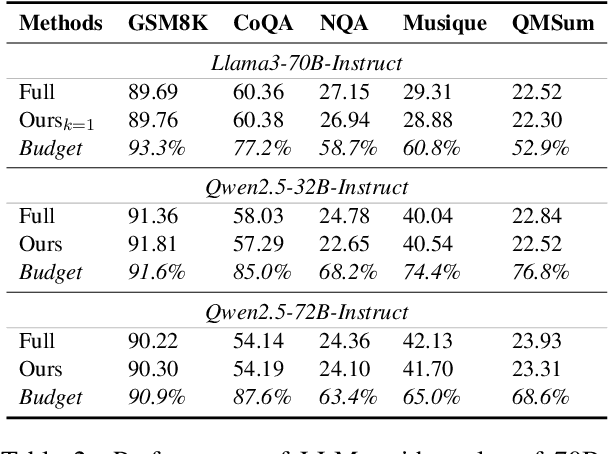
To alleviate memory burden during inference of large language models (LLMs), numerous studies have focused on compressing the KV cache by exploring aspects such as attention sparsity. However, these techniques often require a pre-defined cache budget; as the optimal budget varies with different input lengths and task types, it limits their practical deployment accepting open-domain instructions. To address this limitation, we propose a new KV cache compression objective: to always ensure the full-cache performance regardless of specific inputs, while maximizing KV cache pruning as much as possible. To achieve this goal, we introduce a novel KV cache compression method dubbed DBudgetKV, which features an attention-based metric to signal when the remaining KV cache is unlikely to match the full-cache performance, then halting the pruning process. Empirical evaluation spanning diverse context lengths, task types, and model sizes suggests that our method achieves lossless KV pruning effectively and robustly, exceeding 25% compression ratio on average. Furthermore, our method is easy to integrate within LLM inference, not only optimizing memory space, but also showing reduced inference time compared to existing methods.
Generative Visual Commonsense Answering and Explaining with Generative Scene Graph Constructing
Jan 15, 2025Visual Commonsense Reasoning, which is regarded as one challenging task to pursue advanced visual scene comprehension, has been used to diagnose the reasoning ability of AI systems. However, reliable reasoning requires a good grasp of the scene's details. Existing work fails to effectively exploit the real-world object relationship information present within the scene, and instead overly relies on knowledge from training memory. Based on these observations, we propose a novel scene-graph-enhanced visual commonsense reasoning generation method named \textit{\textbf{G2}}, which first utilizes the image patches and LLMs to construct a location-free scene graph, and then answer and explain based on the scene graph's information. We also propose automatic scene graph filtering and selection strategies to absorb valuable scene graph information during training. Extensive experiments are conducted on the tasks and datasets of scene graph constructing and visual commonsense answering and explaining, respectively. Experimental results and ablation analysis demonstrate the effectiveness of our proposed framework.