 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacteristic AI Agents via Large Language Models
Mar 19, 2024



The advancement of Large Language Models (LLMs) has led to significant enhancements in the performance of chatbot systems. Many researchers have dedicated their efforts to the development of bringing characteristics to chatbots. While there have been commercial products for developing role-driven chatbots using LLMs, it is worth noting that academic research in this area remains relatively scarce. Our research focuses on investigating the performance of LLMs in constructing Characteristic AI Agents by simulating real-life individuals across different settings. Current investigations have primarily focused on act on roles with simple profiles. In response to this research gap, we create a benchmark for the characteristic AI agents task, including dataset, techniques, and evaluation metrics. A dataset called ``Character100'' is built for this benchmark, comprising the most-visited people on Wikipedia for language models to role-play. With the constructed dataset, we conduct comprehensive assessment of LLMs across various settings. In addition, we devise a set of automatic metrics for quantitative performance evaluation. The experimental results underscore the potential directions for further improvement in the capabilities of LLMs in constructing characteristic AI agents. The benchmark is available at https://github.com/nuaa-nlp/Character100.
An Empirical Investigation of Domain Adaptation Ability for Chinese Spelling Check Models
Jan 26, 2024Chinese Spelling Check (CSC) is a meaningful task in the area of Natural Language Processing (NLP) which aims at detecting spelling errors in Chinese texts and then correcting these errors. However, CSC models are based on pretrained language models, which are trained on a general corpus. Consequently, their performance may drop when confronted with downstream tasks involving domain-specific terms. In this paper, we conduct a thorough evaluation about the domain adaption ability of various typical CSC models by building three new datasets encompassing rich domain-specific terms from the financial, medical, and legal domains. Then we conduct empirical investigations in the corresponding domain-specific test datasets to ascertain the cross-domain adaptation ability of several typical CSC models. We also test the performance of the popular large language model ChatGPT. As shown in our experiments, the performances of the CSC models drop significantly in the new domains.
Medical Report Generation based on Segment-Enhanced Contrastive Representation Learning
Dec 26, 2023Automated radiology report generation has the potential to improve radiology reporting and alleviate the workload of radiologists. However, the medical report generation task poses unique challenges due to the limited availability of medical data and the presence of data bias. To maximize the utility of available data and reduce data bias, we propose MSCL (Medical image Segmentation with Contrastive Learning), a framework that utilizes the Segment Anything Model (SAM) to segment organs, abnormalities, bones, etc., and can pay more attention to the meaningful ROIs in the image to get better visual representations. Then we introduce a supervised contrastive loss that assigns more weight to reports that are semantically similar to the target while training. The design of this loss function aims to mitigate the impact of data bias and encourage the model to capture the essential features of a medical image and generate high-quality reports. Experimental results demonstrate the effectiveness of our proposed model, where we achieve state-of-the-art performance on the IU X-Ray public dataset.
ConsistentEE: A Consistent and Hardness-Guided Early Exiting Method for Accelerating Language Models Inference
Dec 19, 2023Early Exiting is one of the most popular methods to achieve efficient inference. Current early exiting methods adopt the (weighted) sum of the cross entropy loss of all internal classifiers during training, imposing all these classifiers to predict all instances correctly. However, during inference, as long as one internal classifier predicts an instance correctly, it can accelerate without losing accuracy. Thus, there is a notable gap between training and inference. We propose ConsistentEE, an early exiting method that is consistent in training and inference. ConsistentEE formulates the early exiting process as a reinforcement learning problem. A policy network is added to decide whether an instance should exit or continue. The training objective of ConsistentEE only require each instance to be predicted correctly by one internal classifier. Additionally, we introduce the concept Memorize Layer to measure the hardness of an instance. We incorporate memorized layer into reward function design, which allows ``easy'' instances to focus more on acceleration while ``hard'' instances to focus more on accuracy. Experimental results show that our method outperforms other baselines on various natural language understanding and generation tasks.
From Ultra-Fine to Fine: Fine-tuning Ultra-Fine Entity Typing Models to Fine-grained
Dec 11, 2023For the task of fine-grained entity typing (FET), due to the use of a large number of entity types, it is usually considered too costly to manually annotating a training dataset that contains an ample number of examples for each type. A common way to address this problem is to use distantly annotated training data that contains incorrect labels. However, the performance of models trained solely with such data can be limited by the errors in the automatic annotation. Recently, there are a few approaches that no longer follow this conventional way. But without using sufficient direct entity typing supervision may also cause them to yield inferior performance. In this paper, we propose a new approach that can avoid the need of creating distantly labeled data whenever there is a new type schema. We first train an entity typing model that have an extremely board type coverage by using the ultra-fine entity typing data. Then, when there is a need to produce a model for a newly designed fine-grained entity type schema. We can simply fine-tune the previously trained model with a small number of examples annotated under this schema. Experimental results show that our approach achieves outstanding performance for FET under the few-shot setting. It can also outperform state-of-the-art weak supervision based methods after fine-tuning the model with only a small size manually annotated training set.
Ultra-Fine Entity Typing with Weak Supervision from a Masked Language Model
Jun 08, 2021

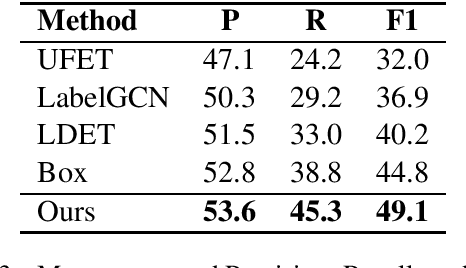
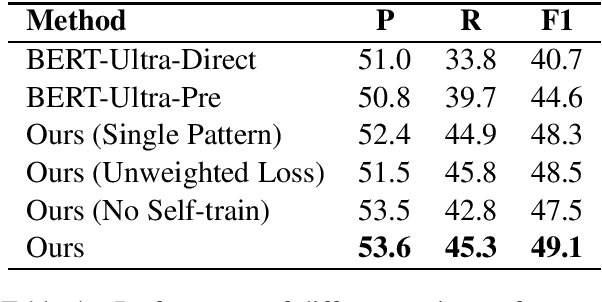
Recently, there is an effort to extend fine-grained entity typing by using a richer and ultra-fine set of types, and labeling noun phrases including pronouns and nominal nouns instead of just named entity mentions. A key challenge for this ultra-fine entity typing task is that human annotated data are extremely scarce, and the annotation ability of existing distant or weak supervision approaches is very limited. To remedy this problem, in this paper, we propose to obtain training data for ultra-fine entity typing by using a BERT Masked Language Model (MLM). Given a mention in a sentence, our approach constructs an input for the BERT MLM so that it predicts context dependent hypernyms of the mention, which can be used as type labels. Experimental results demonstrate that, with the help of these automatically generated labels, the performance of an ultra-fine entity typing model can be improved substantially. We also show that our approach can be applied to improve traditional fine-grained entity typing after performing simple type mapping.
A Chinese Corpus for Fine-grained Entity Typing
Apr 19, 2020
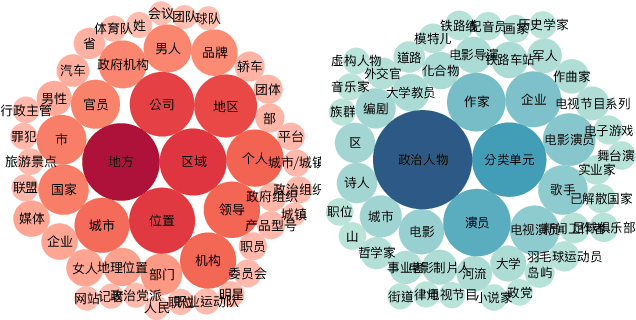
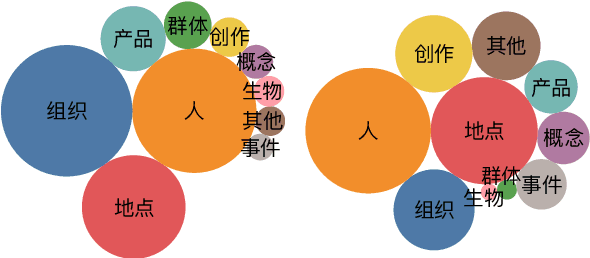

Fine-grained entity typing is a challenging task with wide applications. However, most existing datasets for this task are in English. In this paper, we introduce a corpus for Chinese fine-grained entity typing that contains 4,800 mentions manually labeled through crowdsourcing. Each mention is annotated with free-form entity types. To make our dataset useful in more possible scenarios, we also categorize all the fine-grained types into 10 general types. Finally, we conduct experiments with some neural models whose structures are typical in fine-grained entity typing and show how well they perform on our dataset. We also show the possibility of improving Chinese fine-grained entity typing through cross-lingual transfer learning.
Improving Fine-grained Entity Typing with Entity Linking
Sep 26, 2019

Fine-grained entity typing is a challenging problem since it usually involves a relatively large tag set and may require to understand the context of the entity mention. In this paper, we use entity linking to help with the fine-grained entity type classification process. We propose a deep neural model that makes predictions based on both the context and the information obtained from entity linking results. Experimental results on two commonly used datasets demonstrates the effectiveness of our approach. On both datasets, it achieves more than 5\% absolute strict accuracy improvement over the state of the art.
Neural Aspect and Opinion Term Extraction with Mined Rules as Weak Supervision
Jul 07, 2019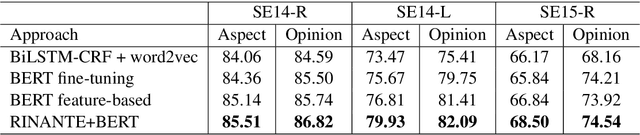
Lack of labeled training data is a major bottleneck for neural network based aspect and opinion term extraction on product reviews. To alleviate this problem, we first propose an algorithm to automatically mine extraction rules from existing training examples based on dependency parsing results. The mined rules are then applied to label a large amount of auxiliary data. Finally, we study training procedures to train a neural model which can learn from both the data automatically labeled by the rules and a small amount of data accurately annotated by human. Experimental results show that although the mined rules themselves do not perform well due to their limited flexibility, the combination of human annotated data and rule labeled auxiliary data can improve the neural model and allow it to achieve performance better than or comparable with the current state-of-the-art.