 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture for Fast and Reliable Coagulation Assessment in Clinical Settings: Leveraging Thromboelastography
Jan 12, 2026In an ideal medical environment, real-time coagulation monitoring can enable early detection and prompt remediation of risks. However, traditional Thromboelastography (TEG), a widely employed diagnostic modality, can only provide such outputs after nearly 1 hour of measurement. The delay might lead to elevated mortality rates. These issues clearly point out one of the key challenges for medical AI development: Mak-ing reasonable predictions based on very small data sets and accounting for variation between different patient populations, a task where conventional deep learning methods typically perform poorly. We present Physiological State Reconstruc-tion (PSR), a new algorithm specifically designed to take ad-vantage of dynamic changes between individuals and to max-imize useful information produced by small amounts of clini-cal data through mapping to reliable predictions and diagnosis. We develop MDFE to facilitate integration of varied temporal signals using multi-domain learning, and jointly learn high-level temporal interactions together with attentions via HLA; furthermore, the parameterized DAM we designed maintains the stability of the computed vital signs. PSR evaluates with 4 TEG-specialized data sets and establishes remarkable perfor-mance -- predictions of R2 > 0.98 for coagulation traits and error reduction around half compared to the state-of-the-art methods, and halving the inferencing time too. Drift-aware learning suggests a new future, with potential uses well be-yond thrombophilia discovery towards medical AI applica-tions with data scarcity.
MixKVQ: Query-Aware Mixed-Precision KV Cache Quantization for Long-Context Reasoning
Dec 22, 2025Long Chain-of-Thought (CoT) reasoning has significantly advanced the capabilities of Large Language Models (LLMs), but this progress is accompanied by substantial memory and latency overhead from the extensive Key-Value (KV) cache. Although KV cache quantization is a promising compression technique, existing low-bit quantization methods often exhibit severe performance degradation on complex reasoning tasks. Fixed-precision quantization struggles to handle outlier channels in the key cache, while current mixed-precision strategies fail to accurately identify components requiring high-precision representation. We find that an effective low-bit KV cache quantization strategy must consider two factors: a key channel's intrinsic quantization difficulty and its relevance to the query. Based on this insight, we propose MixKVQ, a novel plug-and-play method that introduces a lightweight, query-aware algorithm to identify and preserve critical key channels that need higher precision, while applying per-token quantization for value cache. Experiments on complex reasoning datasets demonstrate that our approach significantly outperforms existing low-bit methods, achieving performance comparable to a full-precision baseline at a substantially reduced memory footprint.
Context Reasoner: Incentivizing Reasoning Capability for Contextualized Privacy and Safety Compliance via Reinforcement Learning
May 20, 2025While Large Language Models (LLMs) exhibit remarkable capabilities, they also introduce significant safety and privacy risks. Current mitigation strategies often fail to preserve contextual reasoning capabilities in risky scenarios. Instead, they rely heavily on sensitive pattern matching to protect LLMs, which limits the scope. Furthermore, they overlook established safety and privacy standards, leading to systemic risks for legal compliance. To address these gaps, we formulate safety and privacy issues into contextualized compliance problems following the Contextual Integrity (CI) theory. Under the CI framework, we align our model with three critical regulatory standards: GDPR, EU AI Act, and HIPAA. Specifically, we employ reinforcement learning (RL) with a rule-based reward to incentivize contextual reasoning capabilities while enhancing compliance with safety and privacy norms. Through extensive experiments, we demonstrate that our method not only significantly enhances legal compliance (achieving a +17.64% accuracy improvement in safety/privacy benchmarks) but also further improves general reasoning capability. For OpenThinker-7B, a strong reasoning model that significantly outperforms its base model Qwen2.5-7B-Instruct across diverse subjects, our method enhances its general reasoning capabilities, with +2.05% and +8.98% accuracy improvement on the MMLU and LegalBench benchmark, respectively.
Semantic Shift Estimation via Dual-Projection and Classifier Reconstruction for Exemplar-Free Class-Incremental Learning
Mar 07, 2025


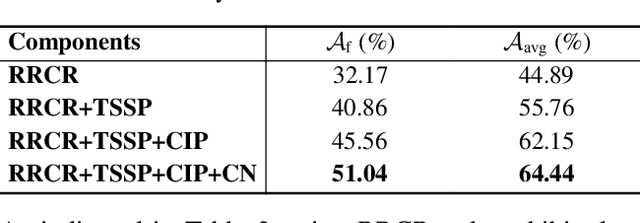
Exemplar-Free Class-Incremental Learning (EFCIL) aims to sequentially learn from distinct categories without retaining exemplars but easily suffers from catastrophic forgetting of learned knowledge. While existing EFCIL methods leverage knowledge distillation to alleviate forgetting, they still face two critical challenges: semantic shift and decision bias. Specifically, the embeddings of old tasks shift in the embedding space after learning new tasks, and the classifier becomes biased towards new tasks due to training solely with new data, thereby hindering the balance between old and new knowledge. To address these issues, we propose the Dual-Projection Shift Estimation and Classifier Reconstruction (DPCR) approach for EFCIL. DPCR effectively estimates semantic shift through a dual-projection, which combines a learnable transformation with a row-space projection to capture both task-wise and category-wise shifts. Furthermore, to mitigate decision bias, DPCR employs ridge regression to reformulate classifier training as a reconstruction process. This reconstruction exploits previous information encoded in covariance and prototype of each class after calibration with estimated shift, thereby reducing decision bias. Extensive experiments demonstrate that, across various datasets, DPCR effectively balances old and new tasks, outperforming state-of-the-art EFCIL methods.
RewardDS: Privacy-Preserving Fine-Tuning for Large Language Models via Reward Driven Data Synthesis
Feb 23, 2025



The success of large language models (LLMs) has attracted many individuals to fine-tune them for domain-specific tasks by uploading their data. However, in sensitive areas like healthcare and finance, privacy concerns often arise. One promising solution is to sample synthetic data with Differential Privacy (DP) guarantees to replace private data. However, these synthetic data contain significant flawed data, which are considered as noise. Existing solutions typically rely on naive filtering by comparing ROUGE-L scores or embedding similarities, which are ineffective in addressing the noise. To address this issue, we propose RewardDS, a novel privacy-preserving framework that fine-tunes a reward proxy model and uses reward signals to guide the synthetic data generation. Our RewardDS introduces two key modules, Reward Guided Filtering and Self-Optimizing Refinement, to both filter and refine the synthetic data, effectively mitigating the noise. Extensive experiments across medical, financial, and code generation domains demonstrate the effectiveness of our method.
SEA: Low-Resource Safety Alignment for Multimodal Large Language Models via Synthetic Embeddings
Feb 18, 2025



Multimodal Large Language Models (MLLMs) have serious security vulnerabilities.While safety alignment using multimodal datasets consisting of text and data of additional modalities can effectively enhance MLLM's security, it is costly to construct these datasets. Existing low-resource security alignment methods, including textual alignment, have been found to struggle with the security risks posed by additional modalities. To address this, we propose Synthetic Embedding augmented safety Alignment (SEA), which optimizes embeddings of additional modality through gradient updates to expand textual datasets. This enables multimodal safety alignment training even when only textual data is available. Extensive experiments on image, video, and audio-based MLLMs demonstrate that SEA can synthesize a high-quality embedding on a single RTX3090 GPU within 24 seconds. SEA significantly improves the security of MLLMs when faced with threats from additional modalities. To assess the security risks introduced by video and audio, we also introduced a new benchmark called VA-SafetyBench. High attack success rates across multiple MLLMs validate its challenge. Our code and data will be available at https://github.com/ZeroNLP/SEA.
Dissecting Fine-Tuning Unlearning in Large Language Models
Oct 09, 2024Fine-tuning-based unlearning methods prevail for preventing targeted harmful, sensitive, or copyrighted information within large language models while preserving overall capabilities. However, the true effectiveness of these methods is unclear. In this paper, we delve into the limitations of fine-tuning-based unlearning through activation patching and parameter restoration experiments. Our findings reveal that these methods alter the model's knowledge retrieval process, rather than genuinely erasing the problematic knowledge embedded in the model parameters. Furthermore, behavioral tests demonstrate that the unlearning mechanisms inevitably impact the global behavior of the models, affecting unrelated knowledge or capabilities. Our work advocates the development of more resilient unlearning techniques for truly erasing knowledge. Our code is released at https://github.com/yihuaihong/Dissecting-FT-Unlearning.
PsFuture: A Pseudo-Future-based Zero-Shot Adaptive Policy for Simultaneous Machine Translation
Oct 05, 2024



Simultaneous Machine Translation (SiMT) requires target tokens to be generated in real-time as streaming source tokens are consumed. Traditional approaches to SiMT typically require sophisticated architectures and extensive parameter configurations for training adaptive read/write policies, which in turn demand considerable computational power and memory. We propose PsFuture, the first zero-shot adaptive read/write policy for SiMT, enabling the translation model to independently determine read/write actions without the necessity for additional training. Furthermore, we introduce a novel training strategy, Prefix-to-Full (P2F), specifically tailored to adjust offline translation models for SiMT applications, exploiting the advantages of the bidirectional attention mechanism inherent in offline models. Experiments across multiple benchmarks demonstrate that our zero-shot policy attains performance on par with strong baselines and the P2F method can further enhance performance, achieving an outstanding trade-off between translation quality and latency.
AIR: Analytic Imbalance Rectifier for Continual Learning
Aug 19, 2024Continual learning enables AI models to learn new data sequentially without retraining in real-world scenarios. Most existing methods assume the training data are balanced, aiming to reduce the catastrophic forgetting problem that models tend to forget previously generated data. However, data imbalance and the mixture of new and old data in real-world scenarios lead the model to ignore categories with fewer training samples. To solve this problem, we propose an analytic imbalance rectifier algorithm (AIR), a novel online exemplar-free continual learning method with an analytic (i.e., closed-form) solution for data-imbalanced class-incremental learning (CIL) and generalized CIL scenarios in real-world continual learning. AIR introduces an analytic re-weighting module (ARM) that calculates a re-weighting factor for each class for the loss function to balance the contribution of each category to the overall loss and solve the problem of imbalanced training data. AIR uses the least squares technique to give a non-discriminatory optimal classifier and its iterative update method in continual learning. Experimental results on multiple datasets show that AIR significantly outperforms existing methods in long-tailed and generalized CIL scenarios. The source code is available at https://github.com/fang-d/AIR.
GenderAlign: An Alignment Dataset for Mitigating Gender Bias in Large Language Models
Jun 20, 2024



Large Language Models (LLMs) are prone to generating content that exhibits gender biases, raising significant ethical concerns. Alignment, the process of fine-tuning LLMs to better align with desired behaviors, is recognized as an effective approach to mitigate gender biases. Although proprietary LLMs have made significant strides in mitigating gender bias, their alignment datasets are not publicly available. The commonly used and publicly available alignment dataset, HH-RLHF, still exhibits gender bias to some extent. There is a lack of publicly available alignment datasets specifically designed to address gender bias. Hence, we developed a new dataset named GenderAlign, aiming at mitigating a comprehensive set of gender biases in LLMs. This dataset comprises 8k single-turn dialogues, each paired with a "chosen" and a "rejected" response. Compared to the "rejected" responses, the "chosen" responses demonstrate lower levels of gender bias and higher quality. Furthermore, we categorized the gender biases in the "rejected" responses of GenderAlign into 4 principal categories. The experimental results show the effectiveness of GenderAlign in reducing gender bias in LLMs.