 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Latent Reasoning and Target-Language Generation via Retrieval-Transition Heads
Feb 25, 2026Recent work has identified a subset of attention heads in Transformer as retrieval heads, which are responsible for retrieving information from the context. In this work, we first investigate retrieval heads in multilingual contexts. In multilingual language models, we find that retrieval heads are often shared across multiple languages. Expanding the study to cross-lingual setting, we identify Retrieval-Transition heads(RTH), which govern the transition to specific target-language output. Our experiments reveal that RTHs are distinct from retrieval heads and more vital for Chain-of-Thought reasoning in multilingual LLMs. Across four multilingual benchmarks (MMLU-ProX, MGSM, MLQA, and XQuaD) and two model families (Qwen-2.5 and Llama-3.1), we demonstrate that masking RTH induces bigger performance drop than masking Retrieval Heads (RH). Our work advances understanding of multilingual LMs by isolating the attention heads responsible for mapping to target languages.
Precise In-Parameter Concept Erasure in Large Language Models
May 28, 2025Large language models (LLMs) often acquire knowledge during pretraining that is undesirable in downstream deployments, e.g., sensitive information or copyrighted content. Existing approaches for removing such knowledge rely on fine-tuning, training low-rank adapters or fact-level editing, but these are either too coarse, too shallow, or ineffective. In this work, we propose PISCES (Precise In-parameter Suppression for Concept EraSure), a novel framework for precisely erasing entire concepts from model parameters by directly editing directions that encode them in parameter space. PISCES uses a disentangler model to decompose MLP vectors into interpretable features, identifies those associated with a target concept using automated interpretability techniques, and removes them from model parameters. Experiments on Gemma 2 and Llama 3.1 over various concepts show that PISCES achieves modest gains in efficacy over leading erasure methods, reducing accuracy on the target concept to as low as 7.7%, while dramatically improving erasure specificity (by up to 31%) and robustness (by up to 38%). Overall, these results demonstrate that feature-based in-parameter editing enables a more precise and reliable approach for removing conceptual knowledge in language models.
The Rise of Parameter Specialization for Knowledge Storage in Large Language Models
May 22, 2025Over time, a growing wave of large language models from various series has been introduced to the community. Researchers are striving to maximize the performance of language models with constrained parameter sizes. However, from a microscopic perspective, there has been limited research on how to better store knowledge in model parameters, particularly within MLPs, to enable more effective utilization of this knowledge by the model. In this work, we analyze twenty publicly available open-source large language models to investigate the relationship between their strong performance and the way knowledge is stored in their corresponding MLP parameters. Our findings reveal that as language models become more advanced and demonstrate stronger knowledge capabilities, their parameters exhibit increased specialization. Specifically, parameters in the MLPs tend to be more focused on encoding similar types of knowledge. We experimentally validate that this specialized distribution of knowledge contributes to improving the efficiency of knowledge utilization in these models. Furthermore, by conducting causal training experiments, we confirm that this specialized knowledge distribution plays a critical role in improving the model's efficiency in leveraging stored knowledge.
The Reasoning-Memorization Interplay in Language Models Is Mediated by a Single Direction
Mar 29, 2025



Large language models (LLMs) excel on a variety of reasoning benchmarks, but previous studies suggest they sometimes struggle to generalize to unseen questions, potentially due to over-reliance on memorized training examples. However, the precise conditions under which LLMs switch between reasoning and memorization during text generation remain unclear. In this work, we provide a mechanistic understanding of LLMs' reasoning-memorization dynamics by identifying a set of linear features in the model's residual stream that govern the balance between genuine reasoning and memory recall. These features not only distinguish reasoning tasks from memory-intensive ones but can also be manipulated to causally influence model performance on reasoning tasks. Additionally, we show that intervening in these reasoning features helps the model more accurately activate the most relevant problem-solving capabilities during answer generation. Our findings offer new insights into the underlying mechanisms of reasoning and memory in LLMs and pave the way for the development of more robust and interpretable generative AI systems.
Dissecting Fine-Tuning Unlearning in Large Language Models
Oct 09, 2024

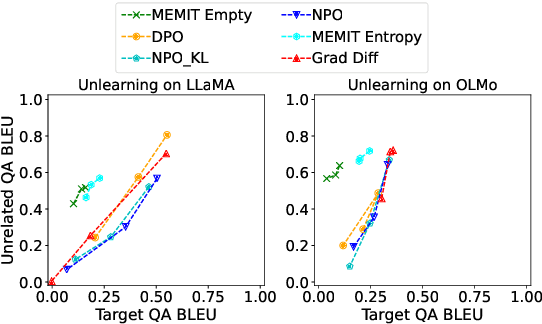

Fine-tuning-based unlearning methods prevail for preventing targeted harmful, sensitive, or copyrighted information within large language models while preserving overall capabilities. However, the true effectiveness of these methods is unclear. In this paper, we delve into the limitations of fine-tuning-based unlearning through activation patching and parameter restoration experiments. Our findings reveal that these methods alter the model's knowledge retrieval process, rather than genuinely erasing the problematic knowledge embedded in the model parameters. Furthermore, behavioral tests demonstrate that the unlearning mechanisms inevitably impact the global behavior of the models, affecting unrelated knowledge or capabilities. Our work advocates the development of more resilient unlearning techniques for truly erasing knowledge. Our code is released at https://github.com/yihuaihong/Dissecting-FT-Unlearning.
Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces
Jun 17, 2024

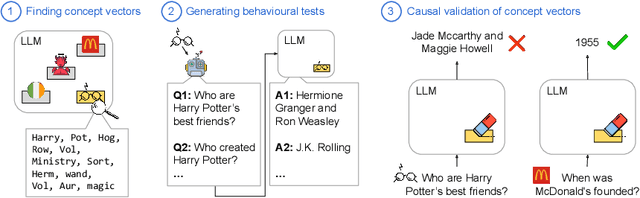

The task of "unlearning" certain concepts in large language models (LLMs) has attracted immense attention recently, due to its importance for mitigating undesirable model behaviours, such as the generation of harmful, private, or incorrect information. Current protocols to evaluate unlearning methods largely rely on behavioral tests, without monitoring the presence of unlearned knowledge within the model's parameters. This residual knowledge can be adversarially exploited to recover the erased information post-unlearning. We argue that unlearning should also be evaluated internally, by considering changes in the parametric knowledge traces of the unlearned concepts. To this end, we propose a general methodology for eliciting directions in the parameter space (termed "concept vectors") that encode concrete concepts, and construct ConceptVectors, a benchmark dataset containing hundreds of common concepts and their parametric knowledge traces within two open-source LLMs. Evaluation on ConceptVectors shows that existing unlearning methods minimally impact concept vectors, while directly ablating these vectors demonstrably removes the associated knowledge from the LLMs and significantly reduces their susceptibility to adversarial manipulation. Our results highlight limitations in behavioral-based unlearning evaluations and call for future work to include parametric-based evaluations. To support this, we release our code and benchmark at https://github.com/yihuaihong/ConceptVectors.
ConsistentEE: A Consistent and Hardness-Guided Early Exiting Method for Accelerating Language Models Inference
Dec 19, 2023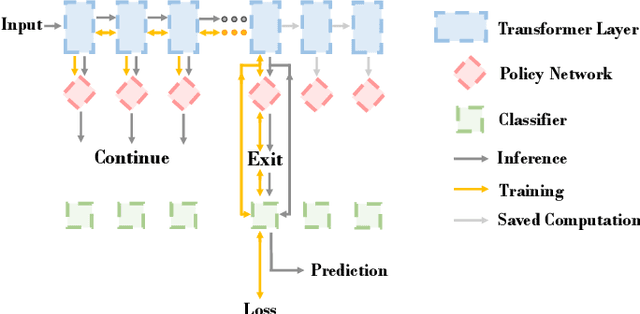

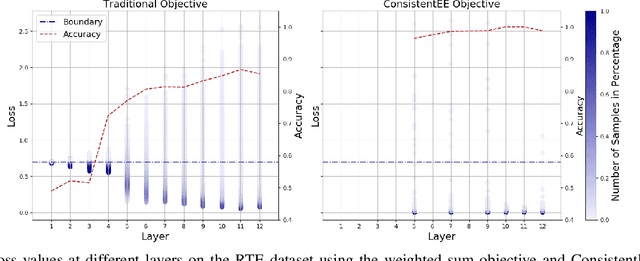
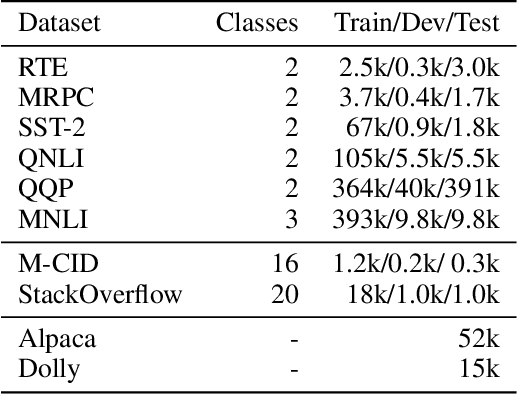
Early Exiting is one of the most popular methods to achieve efficient inference. Current early exiting methods adopt the (weighted) sum of the cross entropy loss of all internal classifiers during training, imposing all these classifiers to predict all instances correctly. However, during inference, as long as one internal classifier predicts an instance correctly, it can accelerate without losing accuracy. Thus, there is a notable gap between training and inference. We propose ConsistentEE, an early exiting method that is consistent in training and inference. ConsistentEE formulates the early exiting process as a reinforcement learning problem. A policy network is added to decide whether an instance should exit or continue. The training objective of ConsistentEE only require each instance to be predicted correctly by one internal classifier. Additionally, we introduce the concept Memorize Layer to measure the hardness of an instance. We incorporate memorized layer into reward function design, which allows ``easy'' instances to focus more on acceleration while ``hard'' instances to focus more on accuracy. Experimental results show that our method outperforms other baselines on various natural language understanding and generation tasks.