 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Exposure Imaging with Events
Apr 11, 2026By combining complementary benefits of short- and long-exposure images, Dual-Exposure Imaging (DEI) enhances image quality in low-light scenarios. However, existing DEI approaches inevitably suffer from producing artifacts due to spatial displacement from scene motion and image feature discrepancies from different exposure times. To tackle this problem, we propose a novel Event-based DEI (E-DEI) algorithm, which reconstructs high-quality images from dual-exposure image pairs and events, leveraging high temporal resolution of event cameras to provide accurate inter-/intra-frame dynamic information. Specifically, we decompose this complex task into an integration of two sub-tasks, i.e., event-based motion deblurring and low-light image enhancement tasks, which guides us to design E-DEI network as a dual-path parallel feature propagation architecture. We propose a Dual-path Feature Alignment and Fusion (DFAF) module to effectively align and fuse features extracted from dual-exposure images with assistance of events. Furthermore, we build a real-world Dataset containing Paired low-/normal-light Images and Events (PIED). Experiments on multiple datasets show the superiority of our method. The code and dataset are available at github.
SpecForge: A Flexible and Efficient Open-Source Training Framework for Speculative Decoding
Mar 19, 2026Large language models incur high inference latency due to sequential autoregressive decoding. Speculative decoding alleviates this bottleneck by using a lightweight draft model to propose multiple tokens for batched verification. However, its adoption has been limited by the lack of high-quality draft models and scalable training infrastructure. We introduce SpecForge, an open-source, production-oriented framework for training speculative decoding models with full support for EAGLE-3. SpecForge incorporates target-draft decoupling, hybrid parallelism, optimized training kernels, and integration with production-grade inference engines, enabling up to 9.9x faster EAGLE-3 training for Qwen3-235B-A22B. In addition, we release SpecBundle, a suite of production-grade EAGLE-3 draft models trained with SpecForge for mainstream open-source LLMs. Through a systematic study of speculative decoding training recipes, SpecBundle addresses the scarcity of high-quality drafts in the community, and our draft models achieve up to 4.48x end-to-end inference speedup on SGLang, establishing SpecForge as a practical foundation for real-world speculative decoding deployment.
MTFM: A Scalable and Alignment-free Foundation Model for Industrial Recommendation in Meituan
Feb 13, 2026Industrial recommendation systems typically involve multiple scenarios, yet existing cross-domain (CDR) and multi-scenario (MSR) methods often require prohibitive resources and strict input alignment, limiting their extensibility. We propose MTFM (Meituan Foundation Model for Recommendation), a transformer-based framework that addresses these challenges. Instead of pre-aligning inputs, MTFM transforms cross-domain data into heterogeneous tokens, capturing multi-scenario knowledge in an alignment-free manner. To enhance efficiency, we first introduce a multi-scenario user-level sample aggregation that significantly enhances training throughput by reducing the total number of instances. We further integrate Grouped-Query Attention and a customized Hybrid Target Attention to minimize memory usage and computational complexity. Furthermore, we implement various system-level optimizations, such as kernel fusion and the elimination of CPU-GPU blocking, to further enhance both training and inference throughput. Offline and online experiments validate the effectiveness of MTFM, demonstrating that significant performance gains are achieved by scaling both model capacity and multi-scenario training data.
DynaWeb: Model-Based Reinforcement Learning of Web Agents
Jan 29, 2026The development of autonomous web agents, powered by Large Language Models (LLMs) and reinforcement learning (RL), represents a significant step towards general-purpose AI assistants. However, training these agents is severely hampered by the challenges of interacting with the live internet, which is inefficient, costly, and fraught with risks. Model-based reinforcement learning (MBRL) offers a promising solution by learning a world model of the environment to enable simulated interaction. This paper introduces DynaWeb, a novel MBRL framework that trains web agents through interacting with a web world model trained to predict naturalistic web page representations given agent actions. This model serves as a synthetic web environment where an agent policy can dream by generating vast quantities of rollout action trajectories for efficient online reinforcement learning. Beyond free policy rollouts, DynaWeb incorporates real expert trajectories from training data, which are randomly interleaved with on-policy rollouts during training to improve stability and sample efficiency. Experiments conducted on the challenging WebArena and WebVoyager benchmarks demonstrate that DynaWeb consistently and significantly improves the performance of state-of-the-art open-source web agent models. Our findings establish the viability of training web agents through imagination, offering a scalable and efficient way to scale up online agentic RL.
Augmenting Question Answering with A Hybrid RAG Approach
Jan 19, 2026Retrieval-Augmented Generation (RAG) has emerged as a powerful technique for enhancing the quality of responses in Question-Answering (QA) tasks. However, existing approaches often struggle with retrieving contextually relevant information, leading to incomplete or suboptimal answers. In this paper, we introduce Structured-Semantic RAG (SSRAG), a hybrid architecture that enhances QA quality by integrating query augmentation, agentic routing, and a structured retrieval mechanism combining vector and graph based techniques with context unification. By refining retrieval processes and improving contextual grounding, our approach improves both answer accuracy and informativeness. We conduct extensive evaluations on three popular QA datasets, TruthfulQA, SQuAD and WikiQA, across five Large Language Models (LLMs), demonstrating that our proposed approach consistently improves response quality over standard RAG implementations.
MCPAgentBench: A Real-world Task Benchmark for Evaluating LLM Agent MCP Tool Use
Dec 31, 2025Large Language Models (LLMs) are increasingly serving as autonomous agents, and their utilization of external tools via the Model Context Protocol (MCP) is considered a future trend. Current MCP evaluation sets suffer from issues such as reliance on external MCP services and a lack of difficulty awareness. To address these limitations, we propose MCPAgentBench, a benchmark based on real-world MCP definitions designed to evaluate the tool-use capabilities of agents. We construct a dataset containing authentic tasks and simulated MCP tools. The evaluation employs a dynamic sandbox environment that presents agents with candidate tool lists containing distractors, thereby testing their tool selection and discrimination abilities. Furthermore, we introduce comprehensive metrics to measure both task completion rates and execution efficiency. Experiments conducted on various latest mainstream Large Language Models reveal significant performance differences in handling complex, multi-step tool invocations. All code is open-source at Github.
In-Context Probing for Membership Inference in Fine-Tuned Language Models
Dec 21, 2025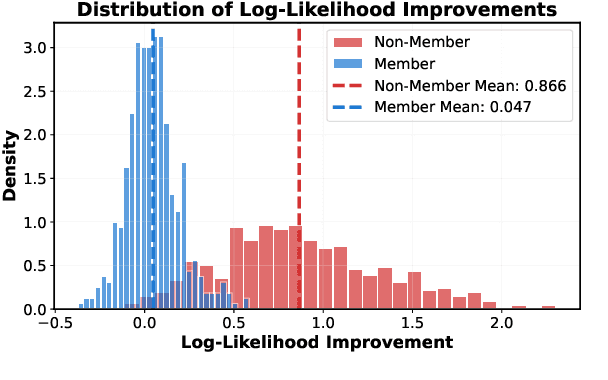
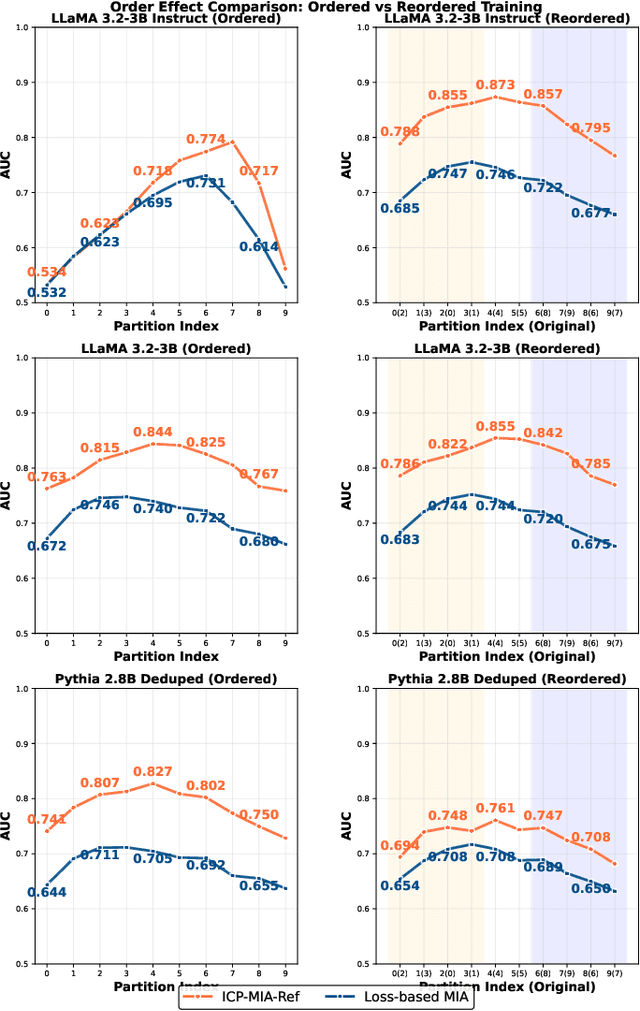
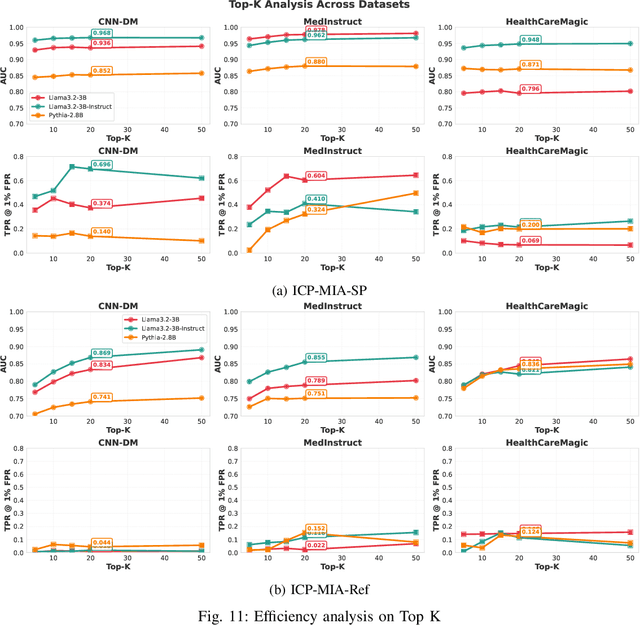
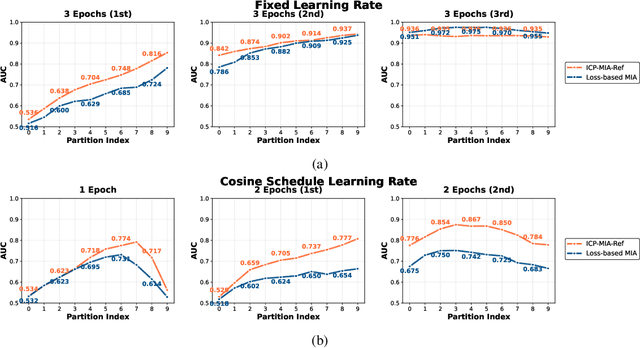
Membership inference attacks (MIAs) pose a critical privacy threat to fine-tuned large language models (LLMs), especially when models are adapted to domain-specific tasks using sensitive data. While prior black-box MIA techniques rely on confidence scores or token likelihoods, these signals are often entangled with a sample's intrinsic properties - such as content difficulty or rarity - leading to poor generalization and low signal-to-noise ratios. In this paper, we propose ICP-MIA, a novel MIA framework grounded in the theory of training dynamics, particularly the phenomenon of diminishing returns during optimization. We introduce the Optimization Gap as a fundamental signal of membership: at convergence, member samples exhibit minimal remaining loss-reduction potential, while non-members retain significant potential for further optimization. To estimate this gap in a black-box setting, we propose In-Context Probing (ICP), a training-free method that simulates fine-tuning-like behavior via strategically constructed input contexts. We propose two probing strategies: reference-data-based (using semantically similar public samples) and self-perturbation (via masking or generation). Experiments on three tasks and multiple LLMs show that ICP-MIA significantly outperforms prior black-box MIAs, particularly at low false positive rates. We further analyze how reference data alignment, model type, PEFT configurations, and training schedules affect attack effectiveness. Our findings establish ICP-MIA as a practical and theoretically grounded framework for auditing privacy risks in deployed LLMs.
GenePheno: Interpretable Gene Knockout-Induced Phenotype Abnormality Prediction from Gene Sequences
Nov 14, 2025
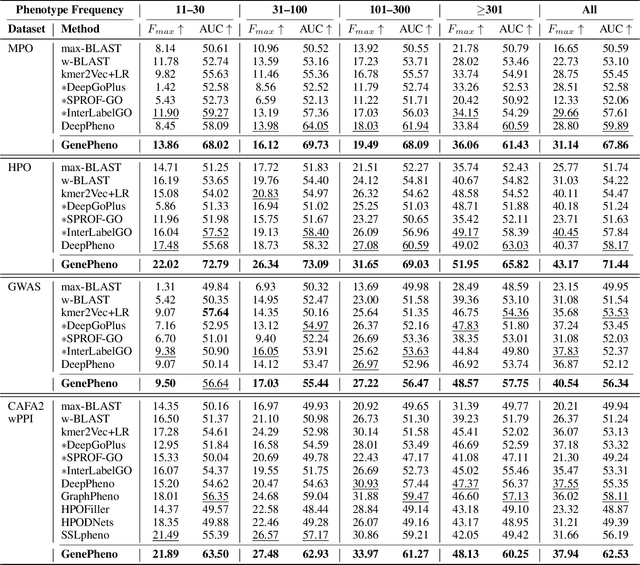
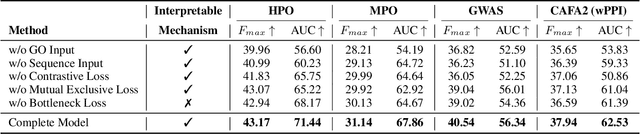
Exploring how genetic sequences shape phenotypes is a fundamental challenge in biology and a key step toward scalable, hypothesis-driven experimentation. The task is complicated by the large modality gap between sequences and phenotypes, as well as the pleiotropic nature of gene-phenotype relationships. Existing sequence-based efforts focus on the degree to which variants of specific genes alter a limited set of phenotypes, while general gene knockout induced phenotype abnormality prediction methods heavily rely on curated genetic information as inputs, which limits scalability and generalizability. As a result, the task of broadly predicting the presence of multiple phenotype abnormalities under gene knockout directly from gene sequences remains underexplored. We introduce GenePheno, the first interpretable multi-label prediction framework that predicts knockout induced phenotypic abnormalities from gene sequences. GenePheno employs a contrastive multi-label learning objective that captures inter-phenotype correlations, complemented by an exclusive regularization that enforces biological consistency. It further incorporates a gene function bottleneck layer, offering human interpretable concepts that reflect functional mechanisms behind phenotype formation. To support progress in this area, we curate four datasets with canonical gene sequences as input and multi-label phenotypic abnormalities induced by gene knockouts as targets. Across these datasets, GenePheno achieves state-of-the-art gene-centric $F_{\text{max}}$ and phenotype-centric AUC, and case studies demonstrate its ability to reveal gene functional mechanisms.
SEDM: Scalable Self-Evolving Distributed Memory for Agents
Sep 11, 2025Long-term multi-agent systems inevitably generate vast amounts of trajectories and historical interactions, which makes efficient memory management essential for both performance and scalability. Existing methods typically depend on vector retrieval and hierarchical storage, yet they are prone to noise accumulation, uncontrolled memory expansion, and limited generalization across domains. To address these challenges, we present SEDM, Self-Evolving Distributed Memory, a verifiable and adaptive framework that transforms memory from a passive repository into an active, self-optimizing component. SEDM integrates verifiable write admission based on reproducible replay, a self-scheduling memory controller that dynamically ranks and consolidates entries according to empirical utility, and cross-domain knowledge diffusion that abstracts reusable insights to support transfer across heterogeneous tasks. Evaluations on benchmark datasets demonstrate that SEDM improves reasoning accuracy while reducing token overhead compared with strong memory baselines, and further enables knowledge distilled from fact verification to enhance multi-hop reasoning. The results highlight SEDM as a scalable and sustainable memory mechanism for open-ended multi-agent collaboration. The code will be released in the later stage of this project.
EVDI++: Event-based Video Deblurring and Interpolation via Self-Supervised Learning
Sep 10, 2025



Frame-based cameras with extended exposure times often produce perceptible visual blurring and information loss between frames, significantly degrading video quality. To address this challenge, we introduce EVDI++, a unified self-supervised framework for Event-based Video Deblurring and Interpolation that leverages the high temporal resolution of event cameras to mitigate motion blur and enable intermediate frame prediction. Specifically, the Learnable Double Integral (LDI) network is designed to estimate the mapping relation between reference frames and sharp latent images. Then, we refine the coarse results and optimize overall training efficiency by introducing a learning-based division reconstruction module, enabling images to be converted with varying exposure intervals. We devise an adaptive parameter-free fusion strategy to obtain the final results, utilizing the confidence embedded in the LDI outputs of concurrent events. A self-supervised learning framework is proposed to enable network training with real-world blurry videos and events by exploring the mutual constraints among blurry frames, latent images, and event streams. We further construct a dataset with real-world blurry images and events using a DAVIS346c camera, demonstrating the generalizability of the proposed EVDI++ in real-world scenarios. Extensive experiments on both synthetic and real-world datasets show that our method achieves state-of-the-art performance in video deblurring and interpolation tasks.