 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTGR: Industrial-Scale Generative Recommendation Framework in Meituan
May 24, 2025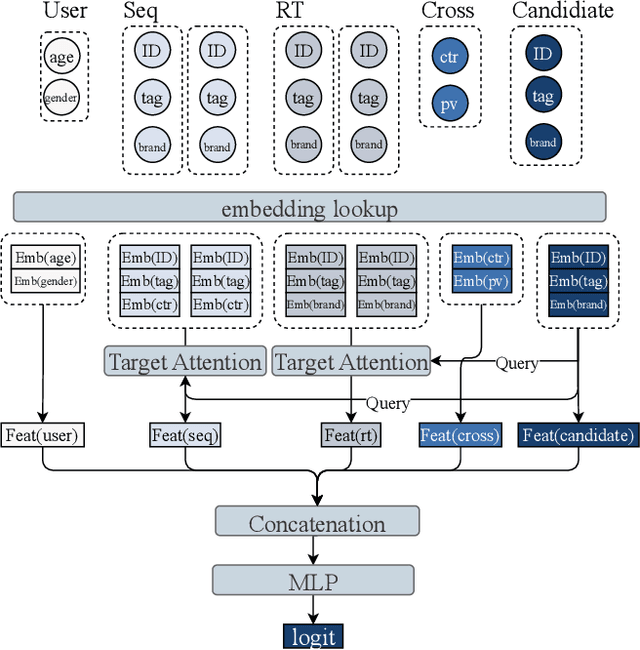
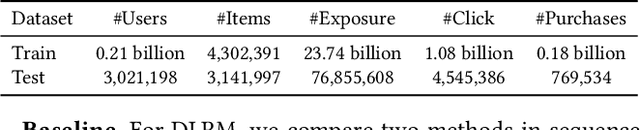
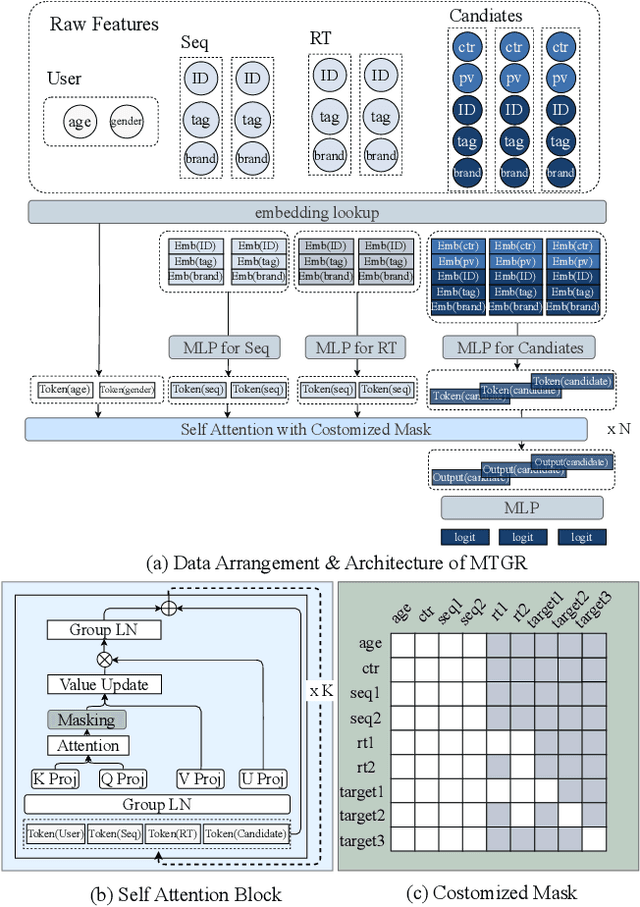

Scaling law has been extensively validated in many domains such as natural language processing and computer vision. In the recommendation system, recent work has adopted generative recommendations to achieve scalability, but their generative approaches require abandoning the carefully constructed cross features of traditional recommendation models. We found that this approach significantly degrades model performance, and scaling up cannot compensate for it at all. In this paper, we propose MTGR (Meituan Generative Recommendation) to address this issue. MTGR is modeling based on the HSTU architecture and can retain the original deep learning recommendation model (DLRM) features, including cross features. Additionally, MTGR achieves training and inference acceleration through user-level compression to ensure efficient scaling. We also propose Group-Layer Normalization (GLN) to enhance the performance of encoding within different semantic spaces and the dynamic masking strategy to avoid information leakage. We further optimize the training frameworks, enabling support for our models with 10 to 100 times computational complexity compared to the DLRM, without significant cost increases. MTGR achieved 65x FLOPs for single-sample forward inference compared to the DLRM model, resulting in the largest gain in nearly two years both offline and online. This breakthrough was successfully deployed on Meituan, the world's largest food delivery platform, where it has been handling the main traffic.
First Activations Matter: Training-Free Methods for Dynamic Activation in Large Language Models
Aug 21, 2024Dynamic activation (DA) techniques, such as DejaVu and MoEfication, have demonstrated their potential to significantly enhance the inference efficiency of large language models (LLMs). However, these techniques often rely on ReLU activation functions or require additional parameters and training to maintain performance. This paper introduces a training-free Threshold-based Dynamic Activation(TDA) method that leverage sequence information to exploit the inherent sparsity of models across various architectures. This method is designed to accelerate generation speed by 18-25\% without significantly compromising task performance, thereby addressing the limitations of existing DA techniques. Moreover, we delve into the root causes of LLM sparsity and theoretically analyze two of its critical features: history-related activation uncertainty and semantic-irrelevant activation inertia. Our comprehensive analyses not only provide a robust theoretical foundation for DA methods but also offer valuable insights to guide future research in optimizing LLMs for greater efficiency and effectiveness.
MOYU: A Theoretical Study on Massive Over-activation Yielded Uplifts in LLMs
Jun 18, 2024

Massive Over-activation Yielded Uplifts(MOYU) is an inherent property of large language models, and dynamic activation(DA) based on the MOYU property is a clever yet under-explored strategy designed to accelerate inference in these models. Existing methods that utilize MOYU often face a significant 'Impossible Trinity': struggling to simultaneously maintain model performance, enhance inference speed, and extend applicability across various architectures. Due to the theoretical ambiguities surrounding MOYU, this paper elucidates the root cause of the MOYU property and outlines the mechanisms behind two primary limitations encountered by current DA methods: 1) history-related activation uncertainty, and 2) semantic-irrelevant activation inertia. Our analysis not only underscores the limitations of current dynamic activation strategies within large-scale LLaMA models but also proposes opportunities for refining the design of future sparsity schemes.
QQQ: Quality Quattuor-Bit Quantization for Large Language Models
Jun 14, 2024



Quantization is a proven effective method for compressing large language models. Although popular techniques like W8A8 and W4A16 effectively maintain model performance, they often fail to concurrently speed up the prefill and decoding stages of inference. W4A8 is a promising strategy to accelerate both of them while usually leads to a significant performance degradation. To address these issues, we present QQQ, a Quality Quattuor-bit Quantization method with 4-bit weights and 8-bit activations. QQQ employs adaptive smoothing and Hessian-based compensation, significantly enhancing the performance of quantized models without extensive training. Furthermore, we meticulously engineer W4A8 GEMM kernels to increase inference speed. Our specialized per-channel W4A8 GEMM and per-group W4A8 GEMM achieve impressive speed increases of 3.67$\times$ and 3.29 $\times$ over FP16 GEMM. Our extensive experiments show that QQQ achieves performance on par with existing state-of-the-art LLM quantization methods while significantly accelerating inference, achieving speed boosts up to 2.24 $\times$, 2.10$\times$, and 1.25$\times$ compared to FP16, W8A8, and W4A16, respectively.
Dynamic Activation Pitfalls in LLaMA Models: An Empirical Study
May 15, 2024In this work, we systematically investigate the efficacy of dynamic activation mechanisms within the LLaMA family of language models. Despite the potential of dynamic activation methods to reduce computation and increase speed in models using the ReLU activation function, our empirical findings have uncovered several inherent pitfalls in the current dynamic activation schemes. Through extensive experiments across various dynamic activation strategies, we demonstrate that LLaMA models usually underperform when compared to their ReLU counterparts, particularly in scenarios demanding high sparsity ratio. We attribute these deficiencies to a combination of factors: 1) the inherent complexity of dynamically predicting activation heads and neurons; 2) the inadequate sparsity resulting from activation functions; 3) the insufficient preservation of information resulting from KV cache skipping. Our analysis not only sheds light on the limitations of dynamic activation in the context of large-scale LLaMA models but also proposes roadmaps for enhancing the design of future sparsity schemes.
Re-evaluating the Memory-balanced Pipeline Parallelism: BPipe
Jan 04, 2024



Pipeline parallelism is an essential technique in the training of large-scale Transformer models. However, it suffers from imbalanced memory consumption, leading to insufficient memory utilization. The BPipe technique was proposed to address this issue and has proven effective in the GPT-3 model. Nevertheless, our experiments have not yielded similar benefits for LLaMA training. Additionally, BPipe only yields negligible benefits for GPT-3 training when applying flash attention. We analyze the underlying causes of the divergent performance of BPipe on GPT-3 and LLaMA. Furthermore, we introduce a novel method to estimate the performance of BPipe.