 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTGR: Industrial-Scale Generative Recommendation Framework in Meituan
May 24, 2025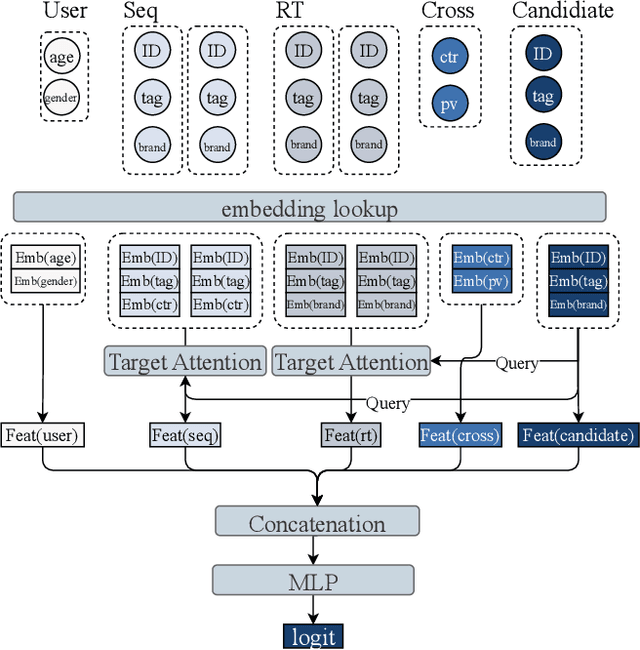
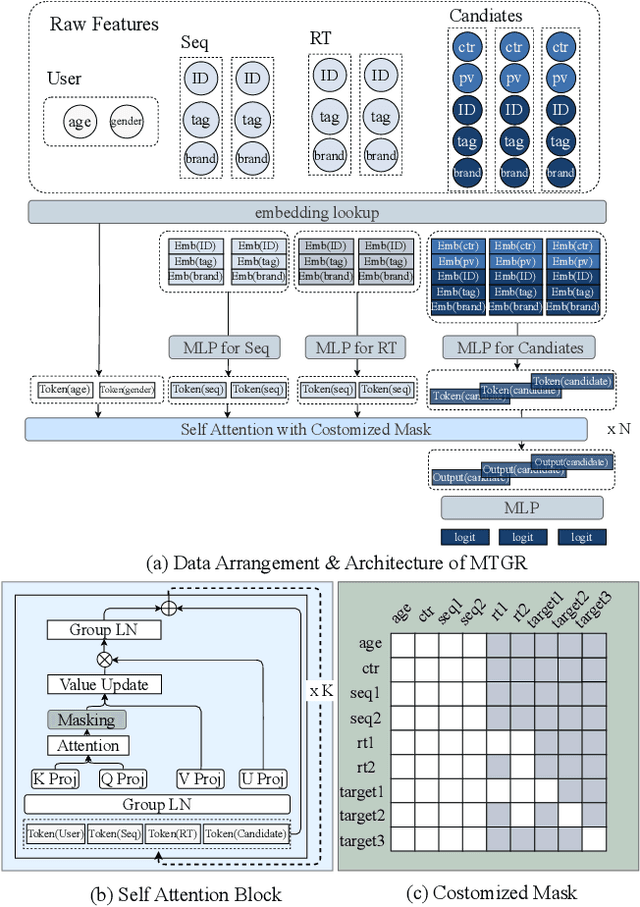

Scaling law has been extensively validated in many domains such as natural language processing and computer vision. In the recommendation system, recent work has adopted generative recommendations to achieve scalability, but their generative approaches require abandoning the carefully constructed cross features of traditional recommendation models. We found that this approach significantly degrades model performance, and scaling up cannot compensate for it at all. In this paper, we propose MTGR (Meituan Generative Recommendation) to address this issue. MTGR is modeling based on the HSTU architecture and can retain the original deep learning recommendation model (DLRM) features, including cross features. Additionally, MTGR achieves training and inference acceleration through user-level compression to ensure efficient scaling. We also propose Group-Layer Normalization (GLN) to enhance the performance of encoding within different semantic spaces and the dynamic masking strategy to avoid information leakage. We further optimize the training frameworks, enabling support for our models with 10 to 100 times computational complexity compared to the DLRM, without significant cost increases. MTGR achieved 65x FLOPs for single-sample forward inference compared to the DLRM model, resulting in the largest gain in nearly two years both offline and online. This breakthrough was successfully deployed on Meituan, the world's largest food delivery platform, where it has been handling the main traffic.
Scaling Laws for Black box Adversarial Attacks
Nov 25, 2024



A longstanding problem of deep learning models is their vulnerability to adversarial examples, which are often generated by applying imperceptible perturbations to natural examples. Adversarial examples exhibit cross-model transferability, enabling to attack black-box models with limited information about their architectures and parameters. Model ensembling is an effective strategy to improve the transferability by attacking multiple surrogate models simultaneously. However, as prior studies usually adopt few models in the ensemble, there remains an open question of whether scaling the number of models can further improve black-box attacks. Inspired by the findings in large foundation models, we investigate the scaling laws of black-box adversarial attacks in this work. By analyzing the relationship between the number of surrogate models and transferability of adversarial examples, we conclude with clear scaling laws, emphasizing the potential of using more surrogate models to enhance adversarial transferability. Extensive experiments verify the claims on standard image classifiers, multimodal large language models, and even proprietary models like GPT-4o, demonstrating consistent scaling effects and impressive attack success rates with more surrogate models. Further studies by visualization indicate that scaled attacks bring better interpretability in semantics, indicating that the common features of models are captured.
First Activations Matter: Training-Free Methods for Dynamic Activation in Large Language Models
Aug 21, 2024Dynamic activation (DA) techniques, such as DejaVu and MoEfication, have demonstrated their potential to significantly enhance the inference efficiency of large language models (LLMs). However, these techniques often rely on ReLU activation functions or require additional parameters and training to maintain performance. This paper introduces a training-free Threshold-based Dynamic Activation(TDA) method that leverage sequence information to exploit the inherent sparsity of models across various architectures. This method is designed to accelerate generation speed by 18-25\% without significantly compromising task performance, thereby addressing the limitations of existing DA techniques. Moreover, we delve into the root causes of LLM sparsity and theoretically analyze two of its critical features: history-related activation uncertainty and semantic-irrelevant activation inertia. Our comprehensive analyses not only provide a robust theoretical foundation for DA methods but also offer valuable insights to guide future research in optimizing LLMs for greater efficiency and effectiveness.
Diff-PIC: Revolutionizing Particle-In-Cell Simulation for Advancing Nuclear Fusion with Diffusion Models
Aug 03, 2024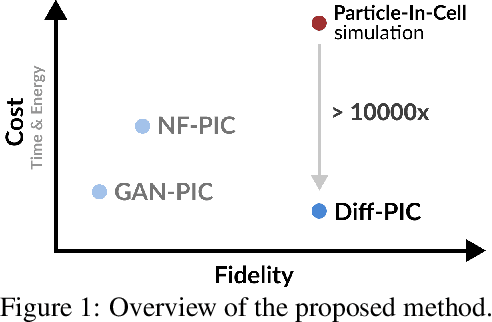
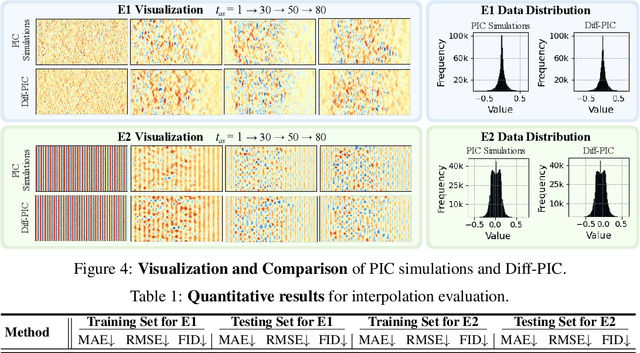
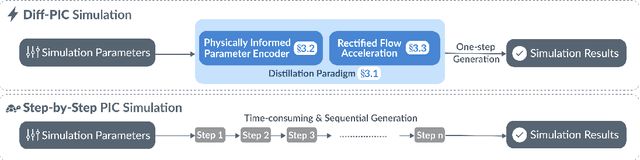
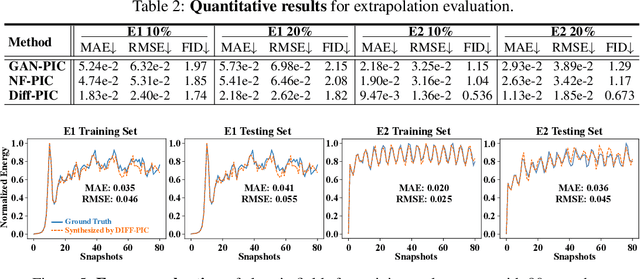
Sustainable energy is a crucial global challenge, and recent breakthroughs in nuclear fusion ignition underscore the potential of harnessing energy extracted from nuclear fusion in everyday life, thereby drawing significant attention to fusion ignition research, especially Laser-Plasma Interaction (LPI). Unfortunately, the complexity of LPI at ignition scale renders theory-based analysis nearly impossible -- instead, it has to rely heavily on Particle-in-Cell (PIC) simulations, which is extremely computationally intensive, making it a major bottleneck in advancing fusion ignition. In response, this work introduces Diff-PIC, a novel paradigm that leverages conditional diffusion models as a computationally efficient alternative to PIC simulations for generating high-fidelity scientific data. Specifically, we design a distillation paradigm to distill the physical patterns captured by PIC simulations into diffusion models, demonstrating both theoretical and practical feasibility. Moreover, to ensure practical effectiveness, we provide solutions for two critical challenges: (1) We develop a physically-informed conditional diffusion model that can learn and generate meaningful embeddings for mathematically continuous physical conditions. This model offers algorithmic generalization and adaptable transferability, effectively capturing the complex relationships between physical conditions and simulation outcomes; and (2) We employ the rectified flow technique to make our model a one-step conditional diffusion model, enhancing its efficiency further while maintaining high fidelity and physical validity. Diff-PIC establishes a new paradigm for using diffusion models to overcome the computational barriers in nuclear fusion research, setting a benchmark for future innovations and advancements in this field.
Inertial Confinement Fusion Forecasting via LLMs
Jul 15, 2024Controlled fusion energy is deemed pivotal for the advancement of human civilization. In this study, we introduce $\textbf{Fusion-LLM}$, a novel integration of Large Language Models (LLMs) with classical reservoir computing paradigms tailored to address challenges in Inertial Confinement Fusion ($\texttt{ICF}$). Our approach offers several key contributions: Firstly, we propose the $\textit{LLM-anchored Reservoir}$, augmented with a fusion-specific prompt, enabling accurate forecasting of hot electron dynamics during implosion. Secondly, we develop $\textit{Signal-Digesting Channels}$ to temporally and spatially describe the laser intensity across time, capturing the unique characteristics of $\texttt{ICF}$ inputs. Lastly, we design the $\textit{Confidence Scanner}$ to quantify the confidence level in forecasting, providing valuable insights for domain experts to design the $\texttt{ICF}$ process. Extensive experiments demonstrate the superior performance of our method, achieving 1.90 CAE, 0.14 $\texttt{top-1}$ MAE, and 0.11 $\texttt{top-5}$ MAE in predicting Hard X-ray ($\texttt{HXR}$) energies of $\texttt{ICF}$ tasks, which presents state-of-the-art comparisons against concurrent best systems. Additionally, we present $\textbf{Fusion4AI}$, the first $\texttt{ICF}$ benchmark based on physical experiments, aimed at fostering novel ideas in plasma physics research and enhancing the utility of LLMs in scientific exploration. Overall, our work strives to forge an innovative synergy between AI and plasma science for advancing fusion energy.
MOYU: A Theoretical Study on Massive Over-activation Yielded Uplifts in LLMs
Jun 18, 2024

Massive Over-activation Yielded Uplifts(MOYU) is an inherent property of large language models, and dynamic activation(DA) based on the MOYU property is a clever yet under-explored strategy designed to accelerate inference in these models. Existing methods that utilize MOYU often face a significant 'Impossible Trinity': struggling to simultaneously maintain model performance, enhance inference speed, and extend applicability across various architectures. Due to the theoretical ambiguities surrounding MOYU, this paper elucidates the root cause of the MOYU property and outlines the mechanisms behind two primary limitations encountered by current DA methods: 1) history-related activation uncertainty, and 2) semantic-irrelevant activation inertia. Our analysis not only underscores the limitations of current dynamic activation strategies within large-scale LLaMA models but also proposes opportunities for refining the design of future sparsity schemes.
QQQ: Quality Quattuor-Bit Quantization for Large Language Models
Jun 14, 2024



Quantization is a proven effective method for compressing large language models. Although popular techniques like W8A8 and W4A16 effectively maintain model performance, they often fail to concurrently speed up the prefill and decoding stages of inference. W4A8 is a promising strategy to accelerate both of them while usually leads to a significant performance degradation. To address these issues, we present QQQ, a Quality Quattuor-bit Quantization method with 4-bit weights and 8-bit activations. QQQ employs adaptive smoothing and Hessian-based compensation, significantly enhancing the performance of quantized models without extensive training. Furthermore, we meticulously engineer W4A8 GEMM kernels to increase inference speed. Our specialized per-channel W4A8 GEMM and per-group W4A8 GEMM achieve impressive speed increases of 3.67$\times$ and 3.29 $\times$ over FP16 GEMM. Our extensive experiments show that QQQ achieves performance on par with existing state-of-the-art LLM quantization methods while significantly accelerating inference, achieving speed boosts up to 2.24 $\times$, 2.10$\times$, and 1.25$\times$ compared to FP16, W8A8, and W4A16, respectively.
Incremental FastPitch: Chunk-based High Quality Text to Speech
Jan 03, 2024Parallel text-to-speech models have been widely applied for real-time speech synthesis, and they offer more controllability and a much faster synthesis process compared with conventional auto-regressive models. Although parallel models have benefits in many aspects, they become naturally unfit for incremental synthesis due to their fully parallel architecture such as transformer. In this work, we propose Incremental FastPitch, a novel FastPitch variant capable of incrementally producing high-quality Mel chunks by improving the architecture with chunk-based FFT blocks, training with receptive-field constrained chunk attention masks, and inference with fixed size past model states. Experimental results show that our proposal can produce speech quality comparable to the parallel FastPitch, with a significant lower latency that allows even lower response time for real-time speech applications.
Efficient Incremental Text-to-Speech on GPUs
Dec 05, 2022Incremental text-to-speech, also known as streaming TTS, has been increasingly applied to online speech applications that require ultra-low response latency to provide an optimal user experience. However, most of the existing speech synthesis pipelines deployed on GPU are still non-incremental, which uncovers limitations in high-concurrency scenarios, especially when the pipeline is built with end-to-end neural network models. To address this issue, we present a highly efficient approach to perform real-time incremental TTS on GPUs with Instant Request Pooling and Module-wise Dynamic Batching. Experimental results demonstrate that the proposed method is capable of producing high-quality speech with a first-chunk latency lower than 80ms under 100 QPS on a single NVIDIA A10 GPU and significantly outperforms the non-incremental twin in both concurrency and latency. Our work reveals the effectiveness of high-performance incremental TTS on GPUs.
Dynamic Normalization
Jan 15, 2021Batch Normalization has become one of the essential components in CNN. It allows the network to use a higher learning rate and speed up training. And the network doesn't need to be initialized carefully. However, in our work, we find that a simple extension of BN can increase the performance of the network. First, we extend BN to adaptively generate scale and shift parameters for each mini-batch data, called DN-C (Batch-shared and Channel-wise). We use the statistical characteristics of mini-batch data ($E[X], Std[X]\in\mathbb{R}^{c}$) as the input of SC module. Then we extend BN to adaptively generate scale and shift parameters for each channel of each sample, called DN-B (Batch and Channel-wise). Our experiments show that DN-C model can't train normally, but DN-B model has very good robustness. In classification task, DN-B can improve the accuracy of the MobileNetV2 on ImageNet-100 more than 2% with only 0.6% additional Mult-Adds. In detection task, DN-B can improve the accuracy of the SSDLite on MS-COCO nearly 4% mAP with the same settings. Compared with BN, DN-B has stable performance when using higher learning rate or smaller batch size.