 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-PIC: Revolutionizing Particle-In-Cell Simulation for Advancing Nuclear Fusion with Diffusion Models
Aug 03, 2024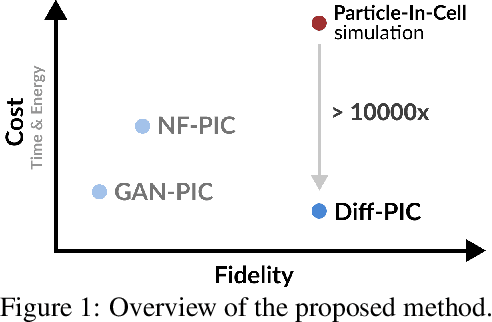
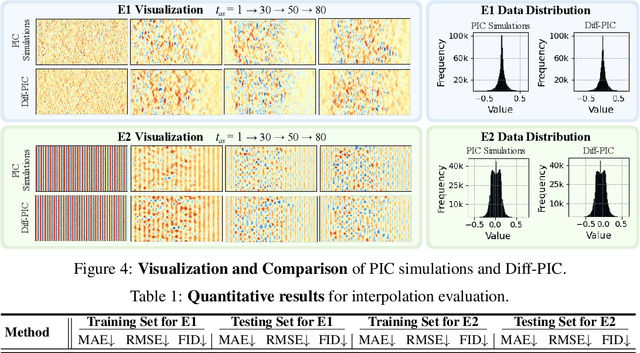
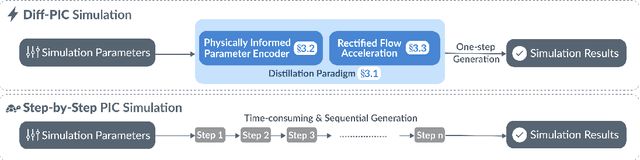
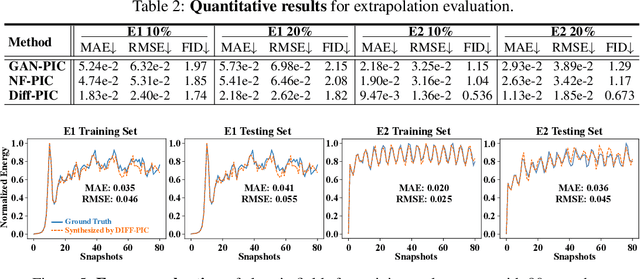
Sustainable energy is a crucial global challenge, and recent breakthroughs in nuclear fusion ignition underscore the potential of harnessing energy extracted from nuclear fusion in everyday life, thereby drawing significant attention to fusion ignition research, especially Laser-Plasma Interaction (LPI). Unfortunately, the complexity of LPI at ignition scale renders theory-based analysis nearly impossible -- instead, it has to rely heavily on Particle-in-Cell (PIC) simulations, which is extremely computationally intensive, making it a major bottleneck in advancing fusion ignition. In response, this work introduces Diff-PIC, a novel paradigm that leverages conditional diffusion models as a computationally efficient alternative to PIC simulations for generating high-fidelity scientific data. Specifically, we design a distillation paradigm to distill the physical patterns captured by PIC simulations into diffusion models, demonstrating both theoretical and practical feasibility. Moreover, to ensure practical effectiveness, we provide solutions for two critical challenges: (1) We develop a physically-informed conditional diffusion model that can learn and generate meaningful embeddings for mathematically continuous physical conditions. This model offers algorithmic generalization and adaptable transferability, effectively capturing the complex relationships between physical conditions and simulation outcomes; and (2) We employ the rectified flow technique to make our model a one-step conditional diffusion model, enhancing its efficiency further while maintaining high fidelity and physical validity. Diff-PIC establishes a new paradigm for using diffusion models to overcome the computational barriers in nuclear fusion research, setting a benchmark for future innovations and advancements in this field.
Inertial Confinement Fusion Forecasting via LLMs
Jul 15, 2024Controlled fusion energy is deemed pivotal for the advancement of human civilization. In this study, we introduce $\textbf{Fusion-LLM}$, a novel integration of Large Language Models (LLMs) with classical reservoir computing paradigms tailored to address challenges in Inertial Confinement Fusion ($\texttt{ICF}$). Our approach offers several key contributions: Firstly, we propose the $\textit{LLM-anchored Reservoir}$, augmented with a fusion-specific prompt, enabling accurate forecasting of hot electron dynamics during implosion. Secondly, we develop $\textit{Signal-Digesting Channels}$ to temporally and spatially describe the laser intensity across time, capturing the unique characteristics of $\texttt{ICF}$ inputs. Lastly, we design the $\textit{Confidence Scanner}$ to quantify the confidence level in forecasting, providing valuable insights for domain experts to design the $\texttt{ICF}$ process. Extensive experiments demonstrate the superior performance of our method, achieving 1.90 CAE, 0.14 $\texttt{top-1}$ MAE, and 0.11 $\texttt{top-5}$ MAE in predicting Hard X-ray ($\texttt{HXR}$) energies of $\texttt{ICF}$ tasks, which presents state-of-the-art comparisons against concurrent best systems. Additionally, we present $\textbf{Fusion4AI}$, the first $\texttt{ICF}$ benchmark based on physical experiments, aimed at fostering novel ideas in plasma physics research and enhancing the utility of LLMs in scientific exploration. Overall, our work strives to forge an innovative synergy between AI and plasma science for advancing fusion energy.
CoCoT: Contrastive Chain-of-Thought Prompting for Large Multimodal Models with Multiple Image Inputs
Jan 05, 2024When exploring the development of Artificial General Intelligence (AGI), a critical task for these models involves interpreting and processing information from multiple image inputs. However, Large Multimodal Models (LMMs) encounter two issues in such scenarios: (1) a lack of fine-grained perception, and (2) a tendency to blend information across multiple images. We first extensively investigate the capability of LMMs to perceive fine-grained visual details when dealing with multiple input images. The research focuses on two aspects: first, image-to-image matching (to evaluate whether LMMs can effectively reason and pair relevant images), and second, multi-image-to-text matching (to assess whether LMMs can accurately capture and summarize detailed image information). We conduct evaluations on a range of both open-source and closed-source large models, including GPT-4V, Gemini, OpenFlamingo, and MMICL. To enhance model performance, we further develop a Contrastive Chain-of-Thought (CoCoT) prompting approach based on multi-input multimodal models. This method requires LMMs to compare the similarities and differences among multiple image inputs, and then guide the models to answer detailed questions about multi-image inputs based on the identified similarities and differences. Our experimental results showcase CoCoT's proficiency in enhancing the multi-image comprehension capabilities of large multimodal models.
Aggregation of Disentanglement: Reconsidering Domain Variations in Domain Generalization
Feb 05, 2023Domain Generalization (DG) is a fundamental challenge for machine learning models, which aims to improve model generalization on various domains. Previous methods focus on generating domain invariant features from various source domains. However, we argue that the domain variantions also contain useful information, ie, classification-aware information, for downstream tasks, which has been largely ignored. Different from learning domain invariant features from source domains, we decouple the input images into Domain Expert Features and noise. The proposed domain expert features lie in a learned latent space where the images in each domain can be classified independently, enabling the implicit use of classification-aware domain variations. Based on the analysis, we proposed a novel paradigm called Domain Disentanglement Network (DDN) to disentangle the domain expert features from the source domain images and aggregate the source domain expert features for representing the target test domain. We also propound a new contrastive learning method to guide the domain expert features to form a more balanced and separable feature space. Experiments on the widely-used benchmarks of PACS, VLCS, OfficeHome, DomainNet, and TerraIncognita demonstrate the competitive performance of our method compared to the recently proposed alternatives.