 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models
Jul 16, 2024



We present VLMEvalKit: an open-source toolkit for evaluating large multi-modality models based on PyTorch. The toolkit aims to provide a user-friendly and comprehensive framework for researchers and developers to evaluate existing multi-modality models and publish reproducible evaluation results. In VLMEvalKit, we implement over 70 different large multi-modality models, including both proprietary APIs and open-source models, as well as more than 20 different multi-modal benchmarks. By implementing a single interface, new models can be easily added to the toolkit, while the toolkit automatically handles the remaining workloads, including data preparation, distributed inference, prediction post-processing, and metric calculation. Although the toolkit is currently mainly used for evaluating large vision-language models, its design is compatible with future updates that incorporate additional modalities, such as audio and video. Based on the evaluation results obtained with the toolkit, we host OpenVLM Leaderboard, a comprehensive leaderboard to track the progress of multi-modality learning research. The toolkit is released at https://github.com/open-compass/VLMEvalKit and is actively maintained.
Prism: A Framework for Decoupling and Assessing the Capabilities of VLMs
Jun 20, 2024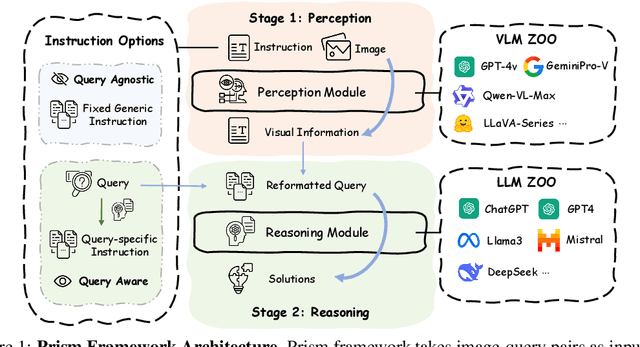
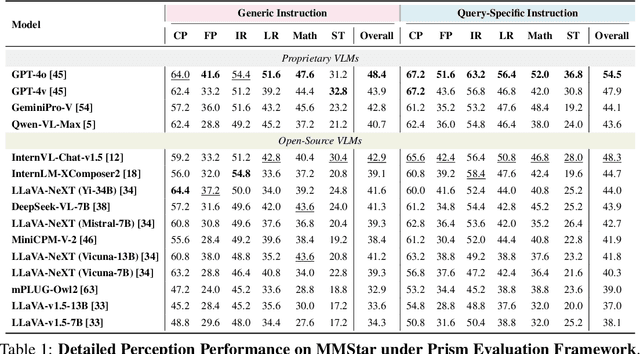
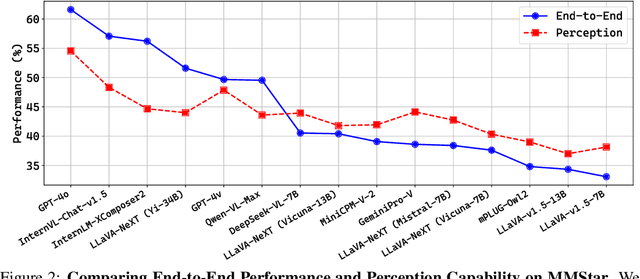
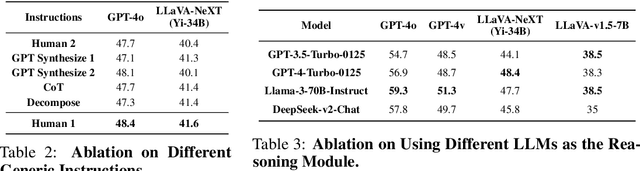
Vision Language Models (VLMs) demonstrate remarkable proficiency in addressing a wide array of visual questions, which requires strong perception and reasoning faculties. Assessing these two competencies independently is crucial for model refinement, despite the inherent difficulty due to the intertwined nature of seeing and reasoning in existing VLMs. To tackle this issue, we present Prism, an innovative framework designed to disentangle the perception and reasoning processes involved in visual question solving. Prism comprises two distinct stages: a perception stage that utilizes a VLM to extract and articulate visual information in textual form, and a reasoning stage that formulates responses based on the extracted visual information using a Large Language Model (LLM). This modular design enables the systematic comparison and assessment of both proprietary and open-source VLM for their perception and reasoning strengths. Our analytical framework provides several valuable insights, underscoring Prism's potential as a cost-effective solution for vision-language tasks. By combining a streamlined VLM focused on perception with a powerful LLM tailored for reasoning, Prism achieves superior results in general vision-language tasks while substantially cutting down on training and operational expenses. Quantitative evaluations show that Prism, when configured with a vanilla 2B LLaVA and freely accessible GPT-3.5, delivers performance on par with VLMs $10 \times$ larger on the rigorous multimodal benchmark MMStar. The project is released at: https://github.com/SparksJoe/Prism.
CoCoT: Contrastive Chain-of-Thought Prompting for Large Multimodal Models with Multiple Image Inputs
Jan 05, 2024When exploring the development of Artificial General Intelligence (AGI), a critical task for these models involves interpreting and processing information from multiple image inputs. However, Large Multimodal Models (LMMs) encounter two issues in such scenarios: (1) a lack of fine-grained perception, and (2) a tendency to blend information across multiple images. We first extensively investigate the capability of LMMs to perceive fine-grained visual details when dealing with multiple input images. The research focuses on two aspects: first, image-to-image matching (to evaluate whether LMMs can effectively reason and pair relevant images), and second, multi-image-to-text matching (to assess whether LMMs can accurately capture and summarize detailed image information). We conduct evaluations on a range of both open-source and closed-source large models, including GPT-4V, Gemini, OpenFlamingo, and MMICL. To enhance model performance, we further develop a Contrastive Chain-of-Thought (CoCoT) prompting approach based on multi-input multimodal models. This method requires LMMs to compare the similarities and differences among multiple image inputs, and then guide the models to answer detailed questions about multi-image inputs based on the identified similarities and differences. Our experimental results showcase CoCoT's proficiency in enhancing the multi-image comprehension capabilities of large multimodal models.
Model-based Offline Policy Optimization with Adversarial Network
Sep 05, 2023Model-based offline reinforcement learning (RL), which builds a supervised transition model with logging dataset to avoid costly interactions with the online environment, has been a promising approach for offline policy optimization. As the discrepancy between the logging data and online environment may result in a distributional shift problem, many prior works have studied how to build robust transition models conservatively and estimate the model uncertainty accurately. However, the over-conservatism can limit the exploration of the agent, and the uncertainty estimates may be unreliable. In this work, we propose a novel Model-based Offline policy optimization framework with Adversarial Network (MOAN). The key idea is to use adversarial learning to build a transition model with better generalization, where an adversary is introduced to distinguish between in-distribution and out-of-distribution samples. Moreover, the adversary can naturally provide a quantification of the model's uncertainty with theoretical guarantees. Extensive experiments showed that our approach outperforms existing state-of-the-art baselines on widely studied offline RL benchmarks. It can also generate diverse in-distribution samples, and quantify the uncertainty more accurately.
Collaborative World Models: An Online-Offline Transfer RL Approach
May 25, 2023

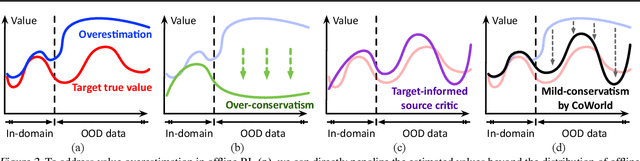

Training visual reinforcement learning (RL) models in offline datasets is challenging due to overfitting issues in representation learning and overestimation problems in value function. In this paper, we propose a transfer learning method called Collaborative World Models (CoWorld) to improve the performance of visual RL under offline conditions. The core idea is to use an easy-to-interact, off-the-shelf simulator to train an auxiliary RL model as the online "test bed" for the offline policy learned in the target domain, which provides a flexible constraint for the value function -- Intuitively, we want to mitigate the overestimation problem of value functions outside the offline data distribution without impeding the exploration of actions with potential advantages. Specifically, CoWorld performs domain-collaborative representation learning to bridge the gap between online and offline hidden state distributions. Furthermore, it performs domain-collaborative behavior learning that enables the source RL agent to provide target-aware value estimation, allowing for effective offline policy regularization. Experiments show that CoWorld significantly outperforms existing methods in offline visual control tasks in DeepMind Control and Meta-World.
Deep Learning for Stock Selection Based on High Frequency Price-Volume Data
Nov 06, 2019

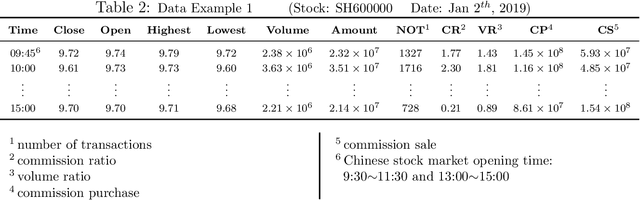

Training a practical and effective model for stock selection has been a greatly concerned problem in the field of artificial intelligence. Even though some of the models from previous works have achieved good performance in the U.S. market by using low-frequency data and features, training a suitable model with high-frequency stock data is still a problem worth exploring. Based on the high-frequency price data of the past several days, we construct two separate models-Convolution Neural Network and Long Short-Term Memory-which can predict the expected return rate of stocks on the current day, and select the stocks with the highest expected yield at the opening to maximize the total return. In our CNN model, we propose improvements on the CNNpred model presented by E. Hoseinzade and S. Haratizadeh in their paper which deals with low-frequency features. Such improvements enable our CNN model to exploit the convolution layer's ability to extract high-level factors and avoid excessive loss of original information at the same time. Our LSTM model utilizes Recurrent Neural Network'advantages in handling time series data. Despite considerable transaction fees due to the daily changes of our stock position, annualized net rate of return is 62.27% for our CNN model, and 50.31% for our LSTM model.