 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeabess: A Fast Best Subset Selection Library in Python and R
Oct 19, 2021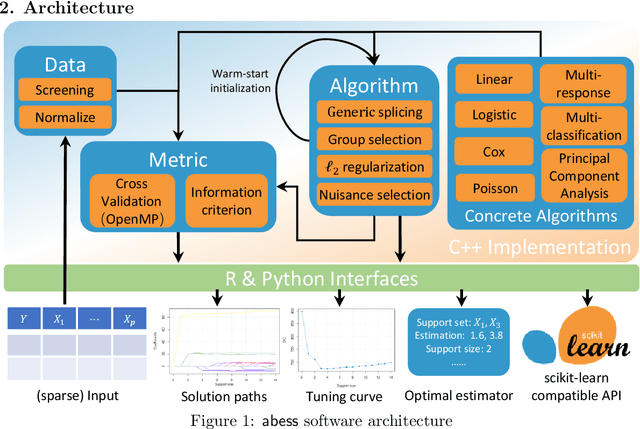


We introduce a new library named abess that implements a unified framework of best-subset selection for solving diverse machine learning problems, e.g., linear regression, classification, and principal component analysis. Particularly, the abess certifiably gets the optimal solution within polynomial times under the linear model. Our efficient implementation allows abess to attain the solution of best-subset selection problems as fast as or even 100x faster than existing competing variable (model) selection toolboxes. Furthermore, it supports common variants like best group subset selection and $\ell_2$ regularized best-subset selection. The core of the library is programmed in C++. For ease of use, a Python library is designed for conveniently integrating with scikit-learn, and it can be installed from the Python library Index. In addition, a user-friendly R library is available at the Comprehensive R Archive Network. The source code is available at: https://github.com/abess-team/abess.
Deep Learning for Stock Selection Based on High Frequency Price-Volume Data
Nov 06, 2019

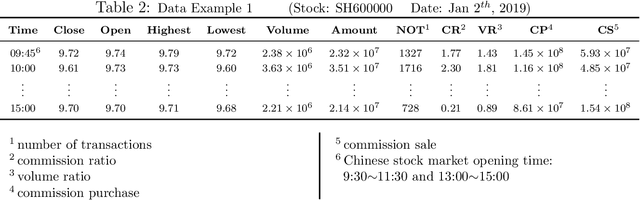

Training a practical and effective model for stock selection has been a greatly concerned problem in the field of artificial intelligence. Even though some of the models from previous works have achieved good performance in the U.S. market by using low-frequency data and features, training a suitable model with high-frequency stock data is still a problem worth exploring. Based on the high-frequency price data of the past several days, we construct two separate models-Convolution Neural Network and Long Short-Term Memory-which can predict the expected return rate of stocks on the current day, and select the stocks with the highest expected yield at the opening to maximize the total return. In our CNN model, we propose improvements on the CNNpred model presented by E. Hoseinzade and S. Haratizadeh in their paper which deals with low-frequency features. Such improvements enable our CNN model to exploit the convolution layer's ability to extract high-level factors and avoid excessive loss of original information at the same time. Our LSTM model utilizes Recurrent Neural Network'advantages in handling time series data. Despite considerable transaction fees due to the daily changes of our stock position, annualized net rate of return is 62.27% for our CNN model, and 50.31% for our LSTM model.
Deep Reinforcement Learning in Portfolio Management
Nov 01, 2018
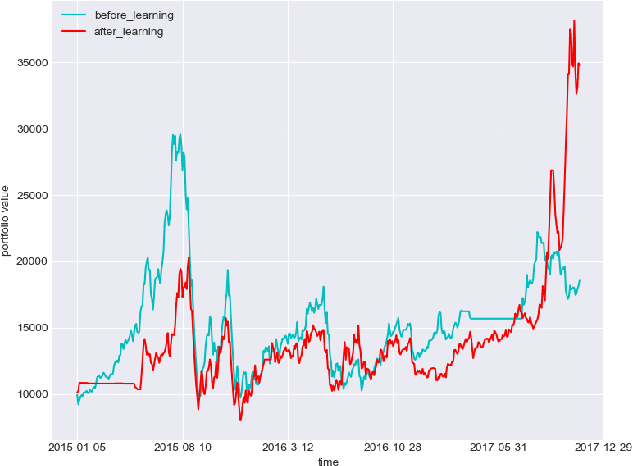

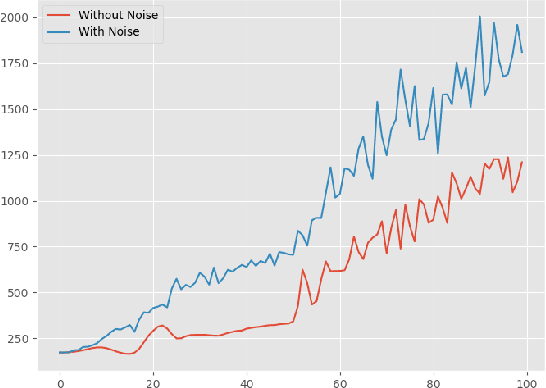
In this paper, we implement two state-of-art continuous reinforcement learning algorithms, Deep Deterministic Policy Gradient (DDPG) and Proximal Policy Optimization (PPO) in portfolio management. Both of them are widely-used in game playing and robot control. What's more, PPO has appealing theoretical propeties which is hopefully potential in portfolio management. We present the performances of them under different settings, including different learning rate, objective function, markets, feature combinations, in order to provide insights for parameter tuning, features selection and data preparation.