 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplacing Multi-Step Assembly of Data Preparation Pipelines with One-Step LLM Pipeline Generation for Table QA
Feb 26, 2026Table Question Answering (TQA) aims to answer natural language questions over structured tables. Large Language Models (LLMs) enable promising solutions to this problem, with operator-centric solutions that generate table manipulation pipelines in a multi-step manner offering state-of-the-art performance. However, these solutions rely on multiple LLM calls, resulting in prohibitive latencies and computational costs. We propose Operation-R1, the first framework that trains lightweight LLMs (e.g., Qwen-4B/1.7B) via a novel variant of reinforcement learning with verifiable rewards to produce high-quality data-preparation pipelines for TQA in a single inference step. To train such an LLM, we first introduce a self-supervised rewarding mechanism to automatically obtain fine-grained pipeline-wise supervision signals for LLM training. We also propose variance-aware group resampling to mitigate training instability. To further enhance robustness of pipeline generation, we develop two complementary mechanisms: operation merge, which filters spurious operations through multi-candidate consensus, and adaptive rollback, which offers runtime protection against information loss in data transformation. Experiments on two benchmark datasets show that, with the same LLM backbone, Operation-R1 achieves average absolute accuracy gains of 9.55 and 6.08 percentage points over multi-step preparation baselines, with 79\% table compression and a 2.2$\times$ reduction in monetary cost.
DIMT25@ICDAR2025: HW-TSC's End-to-End Document Image Machine Translation System Leveraging Large Vision-Language Model
Apr 24, 2025This paper presents the technical solution proposed by Huawei Translation Service Center (HW-TSC) for the "End-to-End Document Image Machine Translation for Complex Layouts" competition at the 19th International Conference on Document Analysis and Recognition (DIMT25@ICDAR2025). Leveraging state-of-the-art open-source large vision-language model (LVLM), we introduce a training framework that combines multi-task learning with perceptual chain-of-thought to develop a comprehensive end-to-end document translation system. During the inference phase, we apply minimum Bayesian decoding and post-processing strategies to further enhance the system's translation capabilities. Our solution uniquely addresses both OCR-based and OCR-free document image translation tasks within a unified framework. This paper systematically details the training methods, inference strategies, LVLM base models, training data, experimental setups, and results, demonstrating an effective approach to document image machine translation.
AIstorian lets AI be a historian: A KG-powered multi-agent system for accurate biography generation
Mar 14, 2025

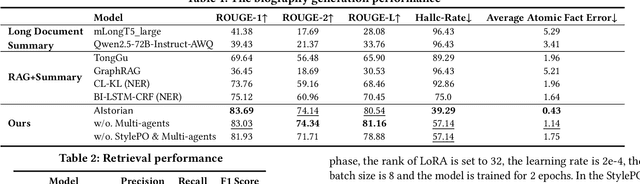

Huawei has always been committed to exploring the AI application in historical research. Biography generation, as a specialized form of abstractive summarization, plays a crucial role in historical research but faces unique challenges that existing large language models (LLMs) struggle to address. These challenges include maintaining stylistic adherence to historical writing conventions, ensuring factual fidelity, and handling fragmented information across multiple documents. We present AIstorian, a novel end-to-end agentic system featured with a knowledge graph (KG)-powered retrieval-augmented generation (RAG) and anti-hallucination multi-agents. Specifically, AIstorian introduces an in-context learning based chunking strategy and a KG-based index for accurate and efficient reference retrieval. Meanwhile, AIstorian orchestrates multi-agents to conduct on-the-fly hallucination detection and error-type-aware correction. Additionally, to teach LLMs a certain language style, we finetune LLMs based on a two-step training approach combining data augmentation-enhanced supervised fine-tuning with stylistic preference optimization. Extensive experiments on a real-life historical Jinshi dataset demonstrate that AIstorian achieves a 3.8x improvement in factual accuracy and a 47.6% reduction in hallucination rate compared to existing baselines. The data and code are available at: https://github.com/ZJU-DAILY/AIstorian.
Automatic Instruction Optimization for Open-source LLM Instruction Tuning
Nov 22, 2023



Instruction tuning is crucial for enabling Language Learning Models (LLMs) in responding to human instructions. The quality of instruction pairs used for tuning greatly affects the performance of LLMs. However, the manual creation of high-quality instruction datasets is costly, leading to the adoption of automatic generation of instruction pairs by LLMs as a popular alternative in the training of open-source LLMs. To ensure the high quality of LLM-generated instruction datasets, several approaches have been proposed. Nevertheless, existing methods either compromise dataset integrity by filtering a large proportion of samples, or are unsuitable for industrial applications. In this paper, instead of discarding low-quality samples, we propose CoachLM, a novel approach to enhance the quality of instruction datasets through automatic revisions on samples in the dataset. CoachLM is trained from the samples revised by human experts and significantly increases the proportion of high-quality samples in the dataset from 17.7% to 78.9%. The effectiveness of CoachLM is further assessed on various real-world instruction test sets. The results show that CoachLM improves the instruction-following capabilities of the instruction-tuned LLM by an average of 29.9%, which even surpasses larger LLMs with nearly twice the number of parameters. Furthermore, CoachLM is successfully deployed in a data management system for LLMs at Huawei, resulting in an efficiency improvement of up to 20% in the cleaning of 40k real-world instruction pairs. We release the training data and code of CoachLM (https://github.com/lunyiliu/CoachLM).
Missing Modality meets Meta Sampling (M3S): An Efficient Universal Approach for Multimodal Sentiment Analysis with Missing Modality
Oct 07, 2022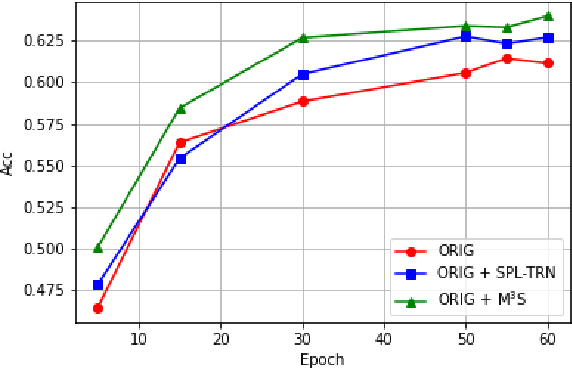
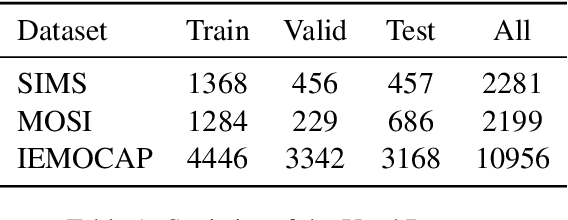
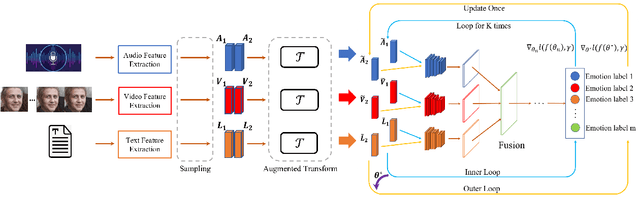
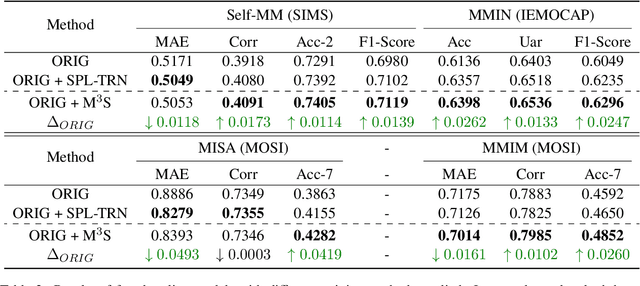
Multimodal sentiment analysis (MSA) is an important way of observing mental activities with the help of data captured from multiple modalities. However, due to the recording or transmission error, some modalities may include incomplete data. Most existing works that address missing modalities usually assume a particular modality is completely missing and seldom consider a mixture of missing across multiple modalities. In this paper, we propose a simple yet effective meta-sampling approach for multimodal sentiment analysis with missing modalities, namely Missing Modality-based Meta Sampling (M3S). To be specific, M3S formulates a missing modality sampling strategy into the modal agnostic meta-learning (MAML) framework. M3S can be treated as an efficient add-on training component on existing models and significantly improve their performances on multimodal data with a mixture of missing modalities. We conduct experiments on IEMOCAP, SIMS and CMU-MOSI datasets, and superior performance is achieved compared with recent state-of-the-art methods.
Deep Reinforcement Learning in Portfolio Management
Nov 01, 2018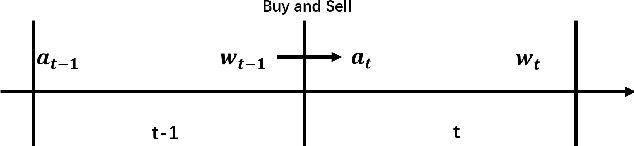
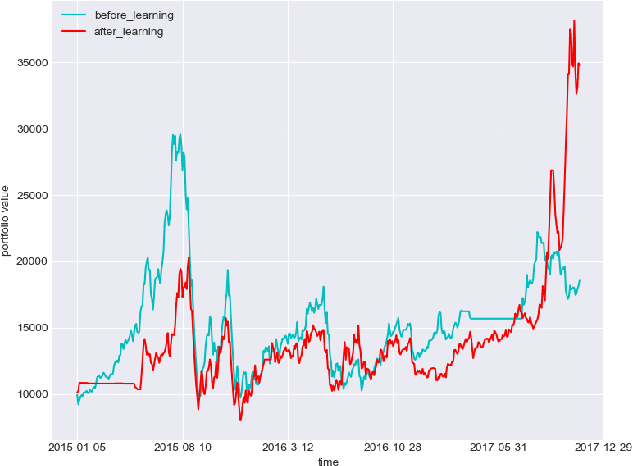

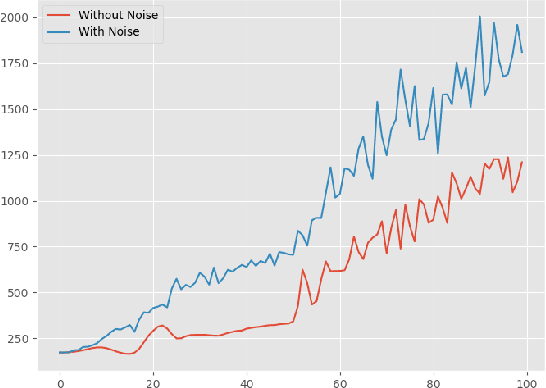
In this paper, we implement two state-of-art continuous reinforcement learning algorithms, Deep Deterministic Policy Gradient (DDPG) and Proximal Policy Optimization (PPO) in portfolio management. Both of them are widely-used in game playing and robot control. What's more, PPO has appealing theoretical propeties which is hopefully potential in portfolio management. We present the performances of them under different settings, including different learning rate, objective function, markets, feature combinations, in order to provide insights for parameter tuning, features selection and data preparation.