 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving the Catastrophic Forgetting Problem in Generalized Category Discovery
Jan 09, 2025Generalized Category Discovery (GCD) aims to identify a mix of known and novel categories within unlabeled data sets, providing a more realistic setting for image recognition. Essentially, GCD needs to remember existing patterns thoroughly to recognize novel categories. Recent state-of-the-art method SimGCD transfers the knowledge from known-class data to the learning of novel classes through debiased learning. However, some patterns are catastrophically forgot during adaptation and thus lead to poor performance in novel categories classification. To address this issue, we propose a novel learning approach, LegoGCD, which is seamlessly integrated into previous methods to enhance the discrimination of novel classes while maintaining performance on previously encountered known classes. Specifically, we design two types of techniques termed as Local Entropy Regularization (LER) and Dual-views Kullback Leibler divergence constraint (DKL). The LER optimizes the distribution of potential known class samples in unlabeled data, thus ensuring the preservation of knowledge related to known categories while learning novel classes. Meanwhile, DKL introduces Kullback Leibler divergence to encourage the model to produce a similar prediction distribution of two view samples from the same image. In this way, it successfully avoids mismatched prediction and generates more reliable potential known class samples simultaneously. Extensive experiments validate that the proposed LegoGCD effectively addresses the known category forgetting issue across all datasets, eg, delivering a 7.74% and 2.51% accuracy boost on known and novel classes in CUB, respectively. Our code is available at: https://github.com/Cliffia123/LegoGCD.
User-Aware Prefix-Tuning is a Good Learner for Personalized Image Captioning
Dec 08, 2023Image captioning bridges the gap between vision and language by automatically generating natural language descriptions for images. Traditional image captioning methods often overlook the preferences and characteristics of users. Personalized image captioning solves this problem by incorporating user prior knowledge into the model, such as writing styles and preferred vocabularies. Most existing methods emphasize the user context fusion process by memory networks or transformers. However, these methods ignore the distinct domains of each dataset. Therefore, they need to update the entire caption model parameters when meeting new samples, which is time-consuming and calculation-intensive. To address this challenge, we propose a novel personalized image captioning framework that leverages user context to consider personality factors. Additionally, our framework utilizes the prefix-tuning paradigm to extract knowledge from a frozen large language model, reducing the gap between different language domains. Specifically, we employ CLIP to extract the visual features of an image and align the semantic space using a query-guided mapping network. By incorporating the transformer layer, we merge the visual features with the user's contextual prior knowledge to generate informative prefixes. Moreover, we employ GPT-2 as the frozen large language model. With a small number of parameters to be trained, our model performs efficiently and effectively. Our model outperforms existing baseline models on Instagram and YFCC100M datasets across five evaluation metrics, demonstrating its superiority, including twofold improvements in metrics such as BLEU-4 and CIDEr.
Sam-Guided Enhanced Fine-Grained Encoding with Mixed Semantic Learning for Medical Image Captioning
Nov 02, 2023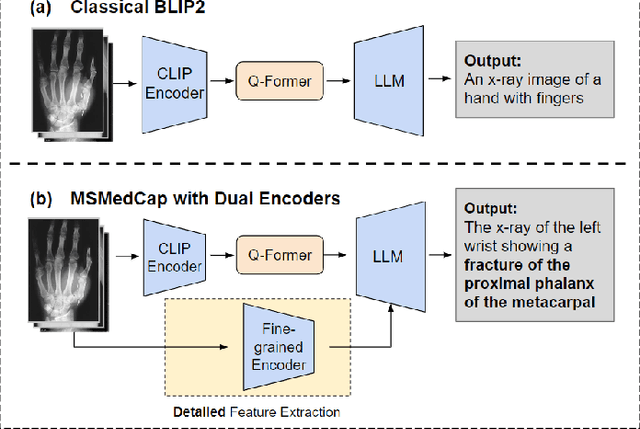
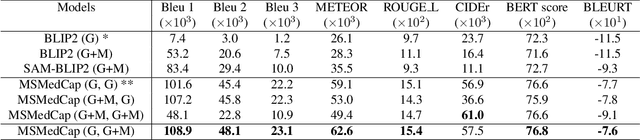
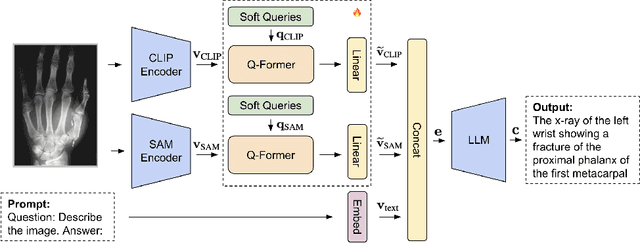
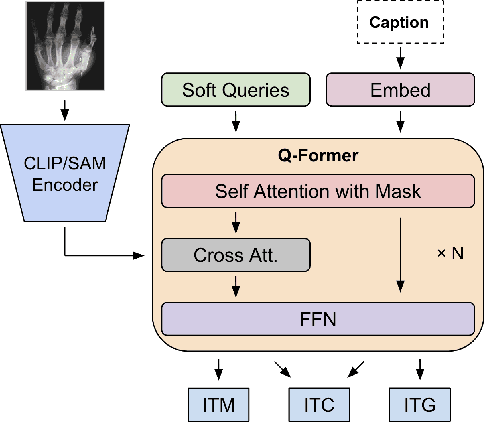
With the development of multimodality and large language models, the deep learning-based technique for medical image captioning holds the potential to offer valuable diagnostic recommendations. However, current generic text and image pre-trained models do not yield satisfactory results when it comes to describing intricate details within medical images. In this paper, we present a novel medical image captioning method guided by the segment anything model (SAM) to enable enhanced encoding with both general and detailed feature extraction. In addition, our approach employs a distinctive pre-training strategy with mixed semantic learning to simultaneously capture both the overall information and finer details within medical images. We demonstrate the effectiveness of this approach, as it outperforms the pre-trained BLIP2 model on various evaluation metrics for generating descriptions of medical images.
FrameRS: A Video Frame Compression Model Composed by Self supervised Video Frame Reconstructor and Key Frame Selector
Sep 16, 2023


In this paper, we present frame reconstruction model: FrameRS. It consists self-supervised video frame reconstructor and key frame selector. The frame reconstructor, FrameMAE, is developed by adapting the principles of the Masked Autoencoder for Images (MAE) for video context. The key frame selector, Frame Selector, is built on CNN architecture. By taking the high-level semantic information from the encoder of FrameMAE as its input, it can predicted the key frames with low computation costs. Integrated with our bespoke Frame Selector, FrameMAE can effectively compress a video clip by retaining approximately 30% of its pivotal frames. Performance-wise, our model showcases computational efficiency and competitive accuracy, marking a notable improvement over traditional Key Frame Extract algorithms. The implementation is available on Github
MovieChat: From Dense Token to Sparse Memory for Long Video Understanding
Jul 31, 2023



Recently, integrating video foundation models and large language models to build a video understanding system overcoming the limitations of specific pre-defined vision tasks. Yet, existing systems can only handle videos with very few frames. For long videos, the computation complexity, memory cost, and long-term temporal connection are the remaining challenges. Inspired by Atkinson-Shiffrin memory model, we develop an memory mechanism including a rapidly updated short-term memory and a compact thus sustained long-term memory. We employ tokens in Transformers as the carriers of memory. MovieChat achieves state-of-the-art performace in long video understanding.
A Survey of Deep Learning in Sports Applications: Perception, Comprehension, and Decision
Jul 07, 2023Deep learning has the potential to revolutionize sports performance, with applications ranging from perception and comprehension to decision. This paper presents a comprehensive survey of deep learning in sports performance, focusing on three main aspects: algorithms, datasets and virtual environments, and challenges. Firstly, we discuss the hierarchical structure of deep learning algorithms in sports performance which includes perception, comprehension and decision while comparing their strengths and weaknesses. Secondly, we list widely used existing datasets in sports and highlight their characteristics and limitations. Finally, we summarize current challenges and point out future trends of deep learning in sports. Our survey provides valuable reference material for researchers interested in deep learning in sports applications.
Answering Private Linear Queries Adaptively using the Common Mechanism
Nov 30, 2022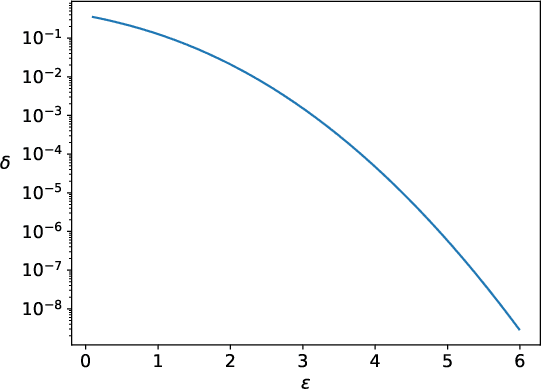

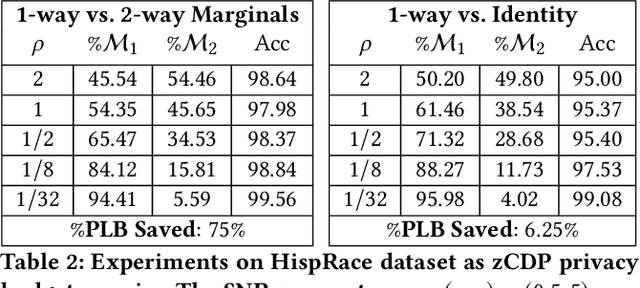
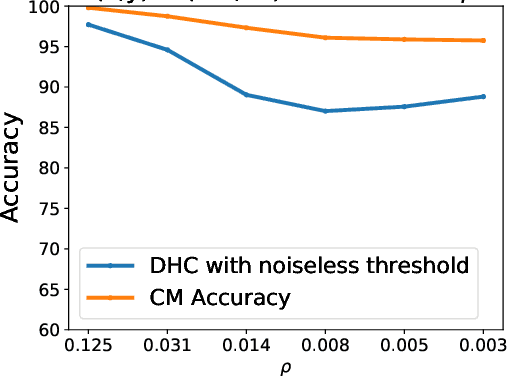
When analyzing confidential data through a privacy filter, a data scientist often needs to decide which queries will best support their intended analysis. For example, an analyst may wish to study noisy two-way marginals in a dataset produced by a mechanism M1. But, if the data are relatively sparse, the analyst may choose to examine noisy one-way marginals, produced by a mechanism M2 instead. Since the choice of whether to use M1 or M2 is data-dependent, a typical differentially private workflow is to first split the privacy loss budget rho into two parts: rho1 and rho2, then use the first part rho1 to determine which mechanism to use, and the remainder rho2 to obtain noisy answers from the chosen mechanism. In a sense, the first step seems wasteful because it takes away part of the privacy loss budget that could have been used to make the query answers more accurate. In this paper, we consider the question of whether the choice between M1 and M2 can be performed without wasting any privacy loss budget. For linear queries, we propose a method for decomposing M1 and M2 into three parts: (1) a mechanism M* that captures their shared information, (2) a mechanism M1' that captures information that is specific to M1, (3) a mechanism M2' that captures information that is specific to M2. Running M* and M1' together is completely equivalent to running M1 (both in terms of query answer accuracy and total privacy cost rho). Similarly, running M* and M2' together is completely equivalent to running M2. Since M* will be used no matter what, the analyst can use its output to decide whether to subsequently run M1'(thus recreating the analysis supported by M1) or M2'(recreating the analysis supported by M2), without wasting privacy loss budget.
Missing Modality meets Meta Sampling (M3S): An Efficient Universal Approach for Multimodal Sentiment Analysis with Missing Modality
Oct 07, 2022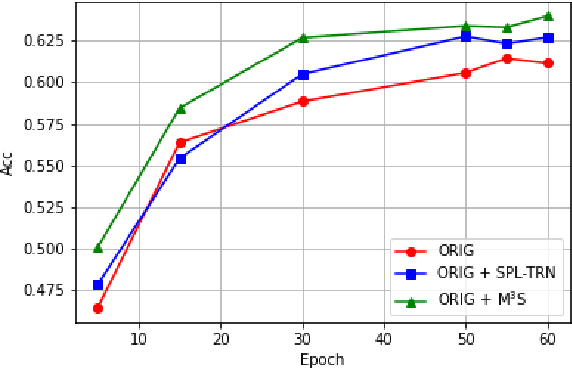
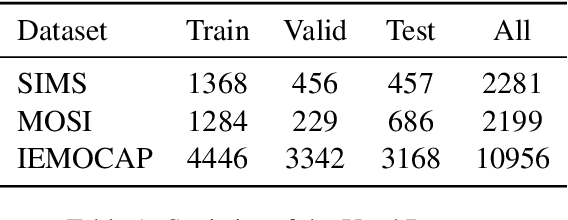
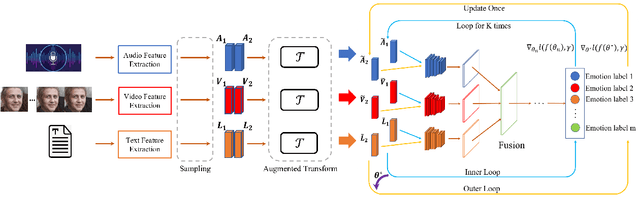
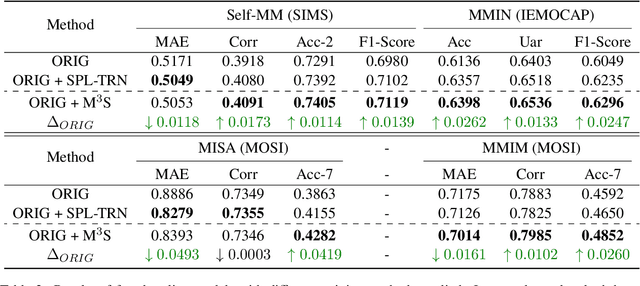
Multimodal sentiment analysis (MSA) is an important way of observing mental activities with the help of data captured from multiple modalities. However, due to the recording or transmission error, some modalities may include incomplete data. Most existing works that address missing modalities usually assume a particular modality is completely missing and seldom consider a mixture of missing across multiple modalities. In this paper, we propose a simple yet effective meta-sampling approach for multimodal sentiment analysis with missing modalities, namely Missing Modality-based Meta Sampling (M3S). To be specific, M3S formulates a missing modality sampling strategy into the modal agnostic meta-learning (MAML) framework. M3S can be treated as an efficient add-on training component on existing models and significantly improve their performances on multimodal data with a mixture of missing modalities. We conduct experiments on IEMOCAP, SIMS and CMU-MOSI datasets, and superior performance is achieved compared with recent state-of-the-art methods.
Preserve Pre-trained Knowledge: Transfer Learning With Self-Distillation For Action Recognition
May 01, 2022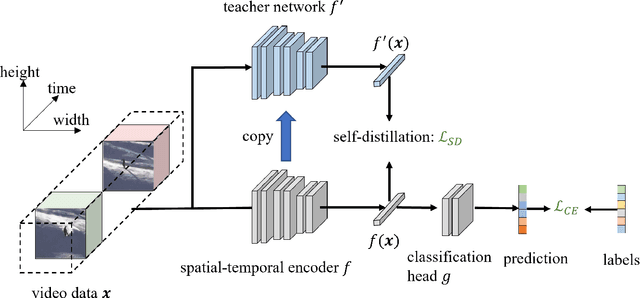
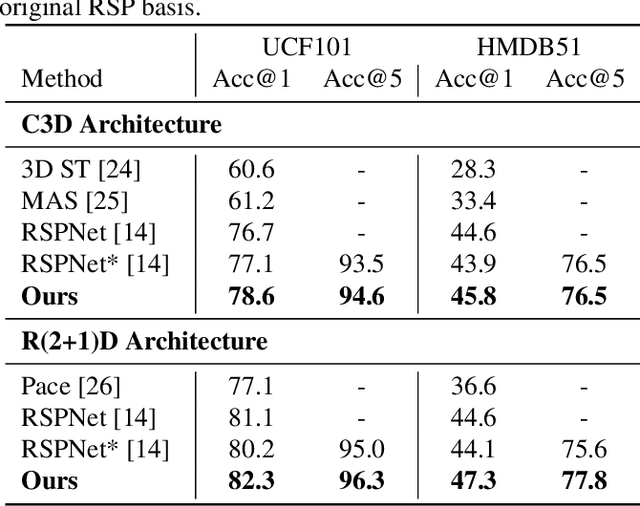
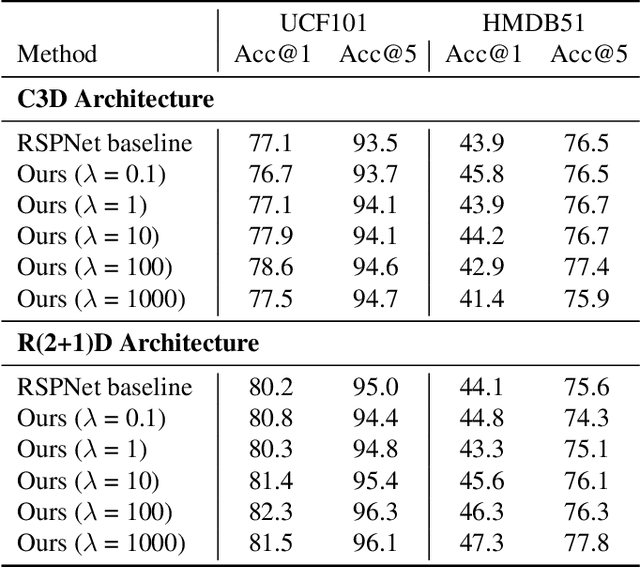
Video-based action recognition is one of the most popular topics in computer vision. With recent advances of selfsupervised video representation learning approaches, action recognition usually follows a two-stage training framework, i.e., self-supervised pre-training on large-scale unlabeled sets and transfer learning on a downstream labeled set. However, catastrophic forgetting of the pre-trained knowledge becomes the main issue in the downstream transfer learning of action recognition, resulting in a sub-optimal solution. In this paper, to alleviate the above issue, we propose a novel transfer learning approach that combines self-distillation in fine-tuning to preserve knowledge from the pre-trained model learned from the large-scale dataset. Specifically, we fix the encoder from the last epoch as the teacher model to guide the training of the encoder from the current epoch in the transfer learning. With such a simple yet effective learning strategy, we outperform state-of-the-art methods on widely used UCF101 and HMDB51 datasets in action recognition task.
Human-Centered Prior-Guided and Task-Dependent Multi-Task Representation Learning for Action Recognition Pre-Training
Apr 27, 2022
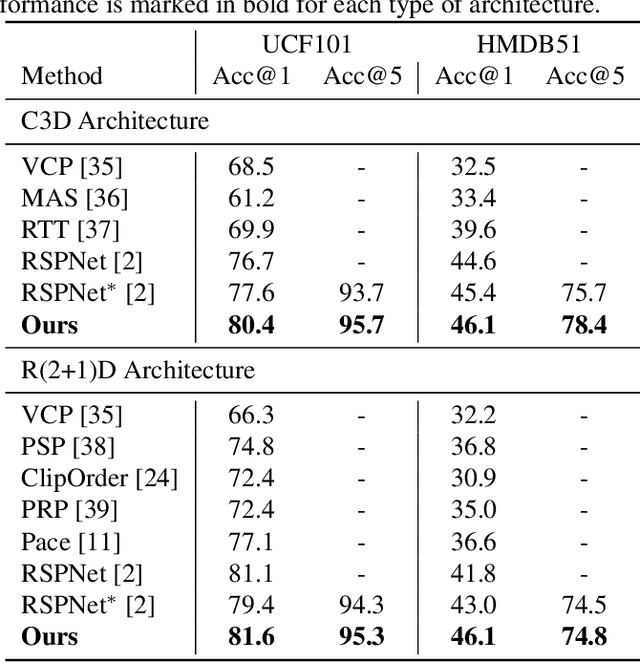
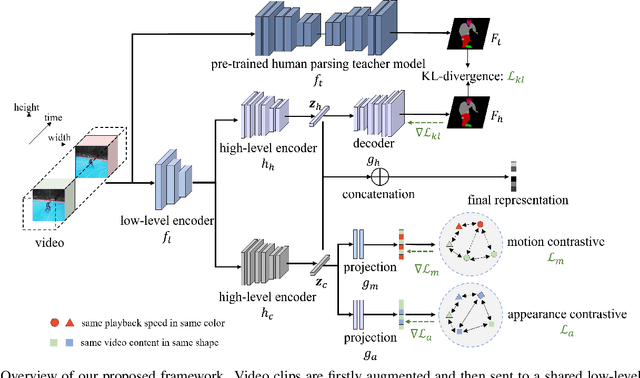
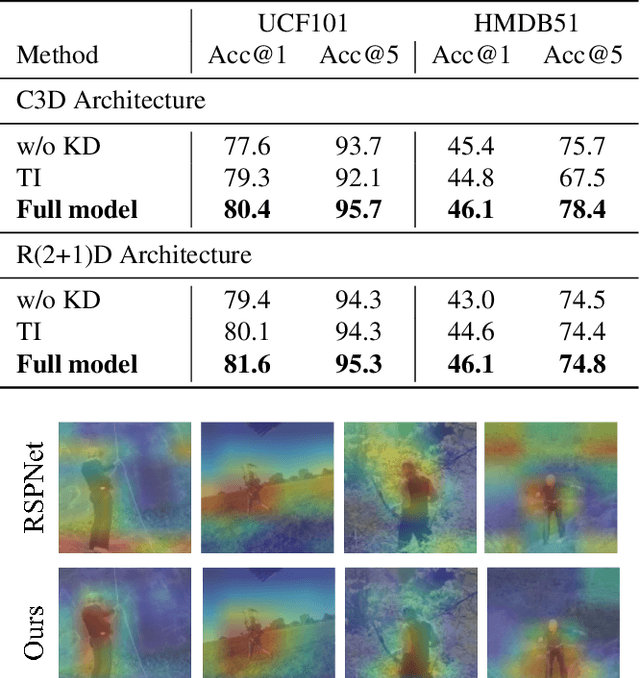
Recently, much progress has been made for self-supervised action recognition. Most existing approaches emphasize the contrastive relations among videos, including appearance and motion consistency. However, two main issues remain for existing pre-training methods: 1) the learned representation is neutral and not informative for a specific task; 2) multi-task learning-based pre-training sometimes leads to sub-optimal solutions due to inconsistent domains of different tasks. To address the above issues, we propose a novel action recognition pre-training framework, which exploits human-centered prior knowledge that generates more informative representation, and avoids the conflict between multiple tasks by using task-dependent representations. Specifically, we distill knowledge from a human parsing model to enrich the semantic capability of representation. In addition, we combine knowledge distillation with contrastive learning to constitute a task-dependent multi-task framework. We achieve state-of-the-art performance on two popular benchmarks for action recognition task, i.e., UCF101 and HMDB51, verifying the effectiveness of our method.