 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and Scalable Matrix Mechanisms via Divide and Conquer
Apr 01, 2026Matrix mechanisms are often used to provide unbiased differentially private query answers when publishing statistics or creating synthetic data. Recent work has developed matrix mechanisms, such as ResidualPlanner and Weighted Fourier Factorizations, that scale to high dimensional datasets while providing optimality guarantees for workloads such as marginals and circular product queries. They operate by adding noise to a linearly independent set of queries that can compactly represent the desired workloads. In this paper, we present QuerySmasher, an alternative scalable approach based on a divide-and-conquer strategy. Given a workload that can be answered from various data marginals, QuerySmasher splits each query into sub-queries and re-assembles the pieces into mutually orthogonal sub-workloads. These sub-workloads represent small, low-dimensional problems that can be independently and optimally answered by existing low-dimensional matrix mechanisms. QuerySmasher then stitches these solutions together to answer queries in the original workload. We show that QuerySmasher subsumes prior work, like ResidualPlanner (RP), ResidualPlanner+ (RP+), and Weighted Fourier Factorizations (WFF). We prove that it can dominate those approaches, under sum squared error, for all workloads. We also experimentally demonstrate the scalability and accuracy of QuerySmasher.
Efficient and Private Marginal Reconstruction with Local Non-Negativity
Oct 01, 2024
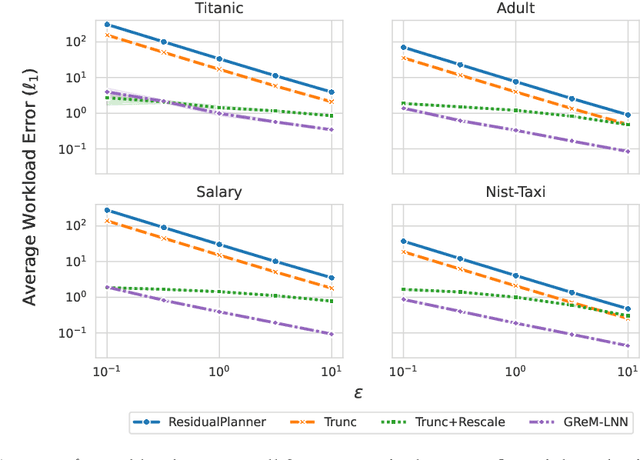
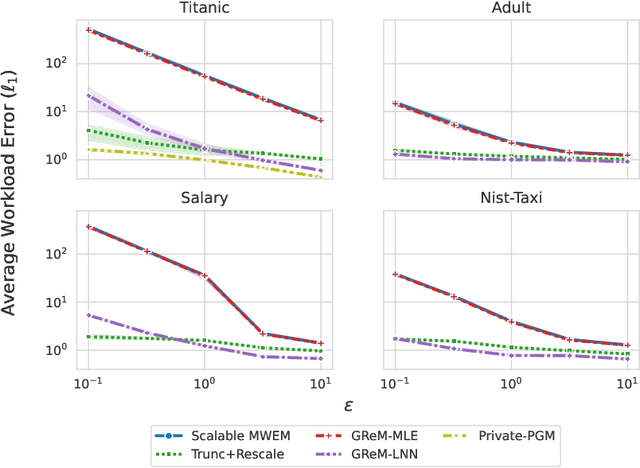
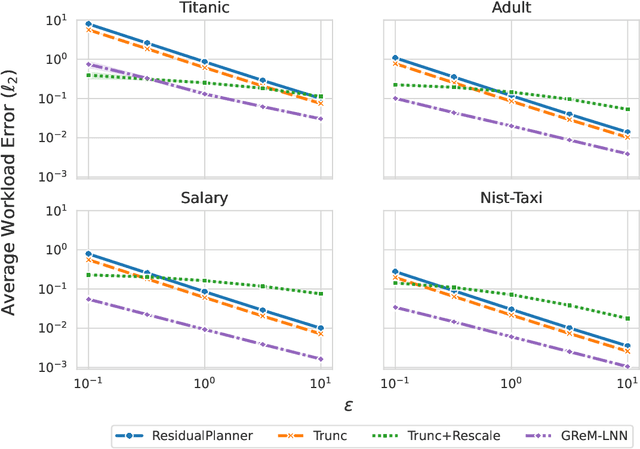
Differential privacy is the dominant standard for formal and quantifiable privacy and has been used in major deployments that impact millions of people. Many differentially private algorithms for query release and synthetic data contain steps that reconstruct answers to queries from answers to other queries measured by the mechanism. Reconstruction is an important subproblem for such mechanisms to economize the privacy budget, minimize error on reconstructed answers, and allow for scalability to high-dimensional datasets. In this paper, we introduce a principled and efficient postprocessing method ReM (Residuals-to-Marginals) for reconstructing answers to marginal queries. Our method builds on recent work on efficient mechanisms for marginal query release, based on making measurements using a residual query basis that admits efficient pseudoinversion, which is an important primitive used in reconstruction. An extension GReM-LNN (Gaussian Residuals-to-Marginals with Local Non-negativity) reconstructs marginals under Gaussian noise satisfying consistency and non-negativity, which often reduces error on reconstructed answers. We demonstrate the utility of ReM and GReM-LNN by applying them to improve existing private query answering mechanisms: ResidualPlanner and MWEM.
An Optimal and Scalable Matrix Mechanism for Noisy Marginals under Convex Loss Functions
May 14, 2023
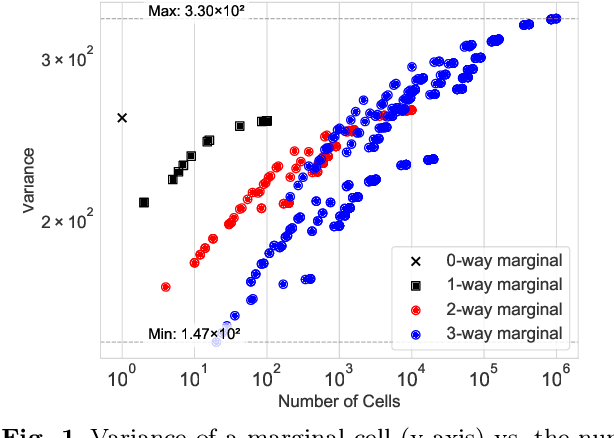
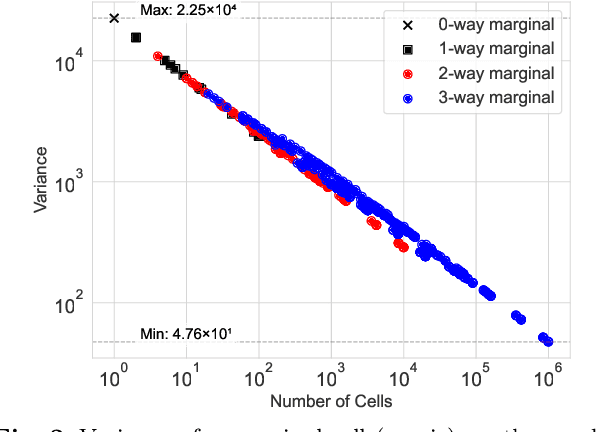
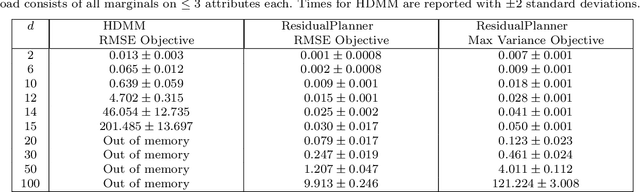
Noisy marginals are a common form of confidentiality-protecting data release and are useful for many downstream tasks such as contingency table analysis, construction of Bayesian networks, and even synthetic data generation. Privacy mechanisms that provide unbiased noisy answers to linear queries (such as marginals) are known as matrix mechanisms. We propose ResidualPlanner, a matrix mechanism for marginals with Gaussian noise that is both optimal and scalable. ResidualPlanner can optimize for many loss functions that can be written as a convex function of marginal variances (prior work was restricted to just one predefined objective function). ResidualPlanner can optimize the accuracy of marginals in large scale settings in seconds, even when the previous state of the art (HDMM) runs out of memory. It even runs on datasets with 100 attributes in a couple of minutes. Furthermore ResidualPlanner can efficiently compute variance/covariance values for each marginal (prior methods quickly run out of memory, even for relatively small datasets).
Answering Private Linear Queries Adaptively using the Common Mechanism
Nov 30, 2022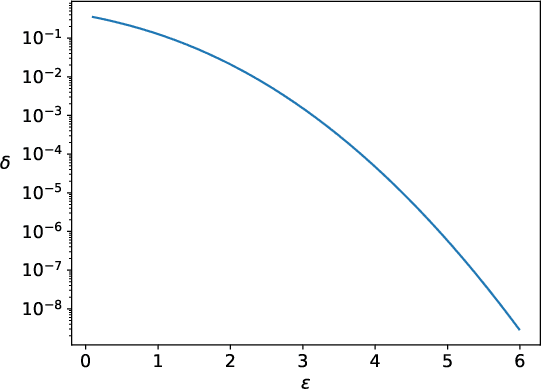

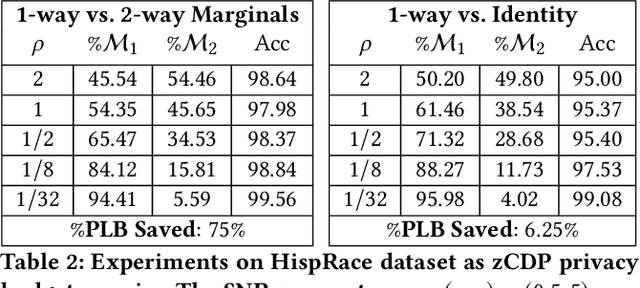
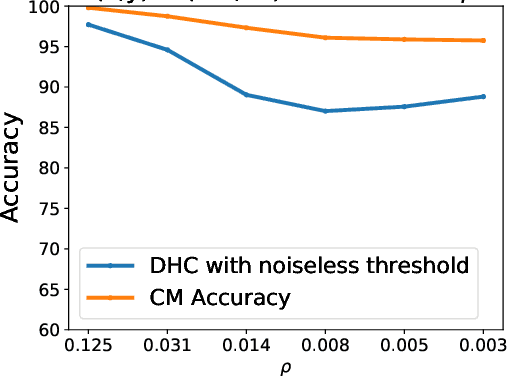
When analyzing confidential data through a privacy filter, a data scientist often needs to decide which queries will best support their intended analysis. For example, an analyst may wish to study noisy two-way marginals in a dataset produced by a mechanism M1. But, if the data are relatively sparse, the analyst may choose to examine noisy one-way marginals, produced by a mechanism M2 instead. Since the choice of whether to use M1 or M2 is data-dependent, a typical differentially private workflow is to first split the privacy loss budget rho into two parts: rho1 and rho2, then use the first part rho1 to determine which mechanism to use, and the remainder rho2 to obtain noisy answers from the chosen mechanism. In a sense, the first step seems wasteful because it takes away part of the privacy loss budget that could have been used to make the query answers more accurate. In this paper, we consider the question of whether the choice between M1 and M2 can be performed without wasting any privacy loss budget. For linear queries, we propose a method for decomposing M1 and M2 into three parts: (1) a mechanism M* that captures their shared information, (2) a mechanism M1' that captures information that is specific to M1, (3) a mechanism M2' that captures information that is specific to M2. Running M* and M1' together is completely equivalent to running M1 (both in terms of query answer accuracy and total privacy cost rho). Similarly, running M* and M2' together is completely equivalent to running M2. Since M* will be used no matter what, the analyst can use its output to decide whether to subsequently run M1'(thus recreating the analysis supported by M1) or M2'(recreating the analysis supported by M2), without wasting privacy loss budget.
Bandit Learning for Diversified Interactive Recommendation
Jul 01, 2019
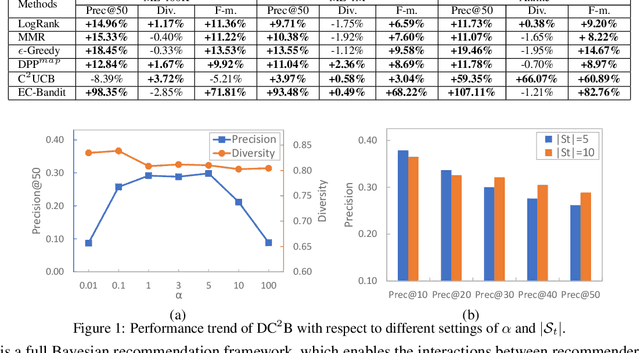
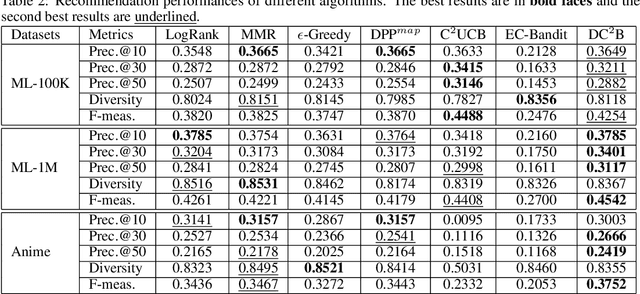
Interactive recommender systems that enable the interactions between users and the recommender system have attracted increasing research attentions. Previous methods mainly focus on optimizing recommendation accuracy. However, they usually ignore the diversity of the recommendation results, thus usually results in unsatisfying user experiences. In this paper, we propose a novel diversified recommendation model, named Diversified Contextual Combinatorial Bandit (DC$^2$B), for interactive recommendation with users' implicit feedback. Specifically, DC$^2$B employs determinantal point process in the recommendation procedure to promote diversity of the recommendation results. To learn the model parameters, a Thompson sampling-type algorithm based on variational Bayesian inference is proposed. In addition, theoretical regret analysis is also provided to guarantee the performance of DC$^2$B. Extensive experiments on real datasets are performed to demonstrate the effectiveness of the proposed method.